


Tutorial ini menunjukkan penalaan halus model Llama 3.1-8b-it untuk analisis sentimen kesihatan mental. Kami akan menyesuaikan model untuk meramalkan status kesihatan mental pesakit dari data teks, menggabungkan penyesuai dengan model asas, dan menggunakan model lengkap pada hab muka yang memeluk. secara penting, ingat bahawa pertimbangan etika adalah yang paling penting apabila menggunakan AI dalam penjagaan kesihatan; Contoh ini adalah untuk tujuan ilustrasi sahaja.
Kami akan meliputi mengakses model Llama 3.1 melalui Kaggle, menggunakan Perpustakaan Transformers untuk kesimpulan, dan proses penalaan halus itu sendiri. Pemahaman terlebih dahulu mengenai penalaan halus LLM (lihat "Panduan Pengenalan kepada LLMS Fine-Tuning") bermanfaat.

imej oleh pengarang
Memahami llama 3.1
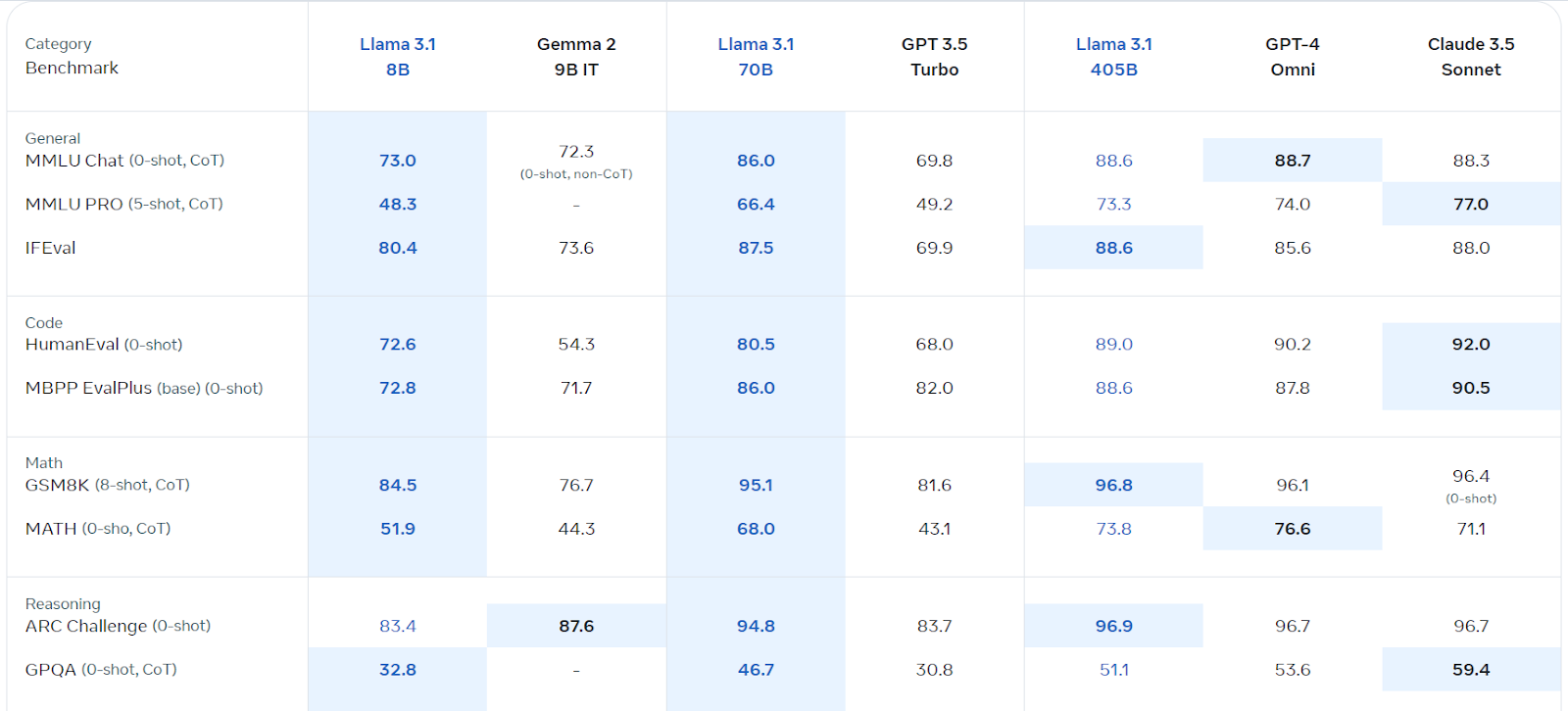
llama 3.1, Model Bahasa Besar Berbilang Bahasa Meta (LLM), cemerlang dalam pemahaman bahasa dan generasi. Tersedia dalam versi parameter 8B, 70B, dan 405B, ia dibina di atas seni bina auto-regresif dengan transformer yang dioptimumkan. Dilatih dengan pelbagai data awam, ia menyokong lapan bahasa dan menawarkan panjang konteks 128k. Lesen komersilnya mudah diakses, dan ia melebihi beberapa pesaing dalam pelbagai tanda aras.
mengakses dan menggunakan llama 3.1 di Kaggle
Kami akan memanfaatkan GPU/TPU percuma Kaggle. Ikuti langkah -langkah ini:
Daftar di Meta.com (menggunakan e -mel Kaggle anda).
- mengakses repositori llama 3.1 Kaggle dan meminta akses model.
- Lancarkan buku nota Kaggle menggunakan butang "kod" yang disediakan.
- Pilih versi model pilihan anda dan tambahkannya ke buku nota.
- Pasang pakej yang diperlukan ( ).
-
%pip install -U transformers accelerateMuatkan model dan tokenizer:
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(base_model, return_dict=True, low_cpu_mem_usage=True, torch_dtype=torch.float16, device_map="auto", trust_remote_code=True)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.float16, device_map="auto") Buat petunjuk dan jalankan kesimpulan: messages = [{"role": "user", "content": "What is the tallest building in the world?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])  Fine-Tuning Llama 3.1 untuk Klasifikasi Kesihatan Mental
Fine-Tuning Llama 3.1 untuk Klasifikasi Kesihatan Mental
Persediaan:
Mulakan notebook Kaggle baru dengan Llama 3.1, pasang pakej yang diperlukan (- ,
- ,
,
, ), dan tambahkan dataset "sentimen untuk kesihatan mental". Konfigurasikan berat & bias (menggunakan kekunci API anda). -
Pemprosesan Data: Muatkan dataset, bersihkannya (mengeluarkan kategori samar -samar: "bunuh diri," "tekanan," "gangguan keperibadian"), shuffle, dan berpecah kepada latihan, penilaian, dan set ujian (menggunakan 3000 sampel untuk kecekapan). Buat petunjuk menggabungkan pernyataan dan label.
-
Model Loading: Muatkan model Llama-3.1-8B-Instruct menggunakan kuantisasi 4-bit untuk kecekapan memori. Muatkan tokenizer dan tetapkan id token pad.
-
Penilaian pra-penalaan: Buat fungsi untuk meramalkan label dan menilai prestasi model (ketepatan, laporan klasifikasi, matriks kekeliruan). Menilai prestasi asas model sebelum penalaan halus.
-
Fine-penune: Konfigurasi LORA menggunakan parameter yang sesuai. Sediakan hujah latihan (menyesuaikan seperti yang diperlukan untuk persekitaran anda). Melatih model menggunakan
SFTTrainer. Pantau kemajuan menggunakan berat & bias. -
penilaian pasca-penalaan: menilai semula prestasi model selepas penalaan halus.
-
3 Uji model yang digabungkan. Simpan dan tolak model akhir dan tokenizer ke hab muka yang memeluk.
PeftModel.from_pretrained()ingat untuk menggantikan ruang letak sepertimodel.merge_and_unload()dengan laluan fail sebenar anda. Kod lengkap dan penjelasan terperinci boleh didapati dalam respons asal, lebih lama. Versi pekat ini menyediakan gambaran keseluruhan peringkat tinggi dan coretan kod utama. Sentiasa mengutamakan pertimbangan etika semasa bekerja dengan data sensitif.
Atas ialah kandungan terperinci Penalaan Llama 3.1 untuk klasifikasi teks. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undress AI Tool
Gambar buka pakaian secara percuma

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)



 Kimi K2: Model agentik sumber terbuka yang paling kuat
Jul 12, 2025 am 09:16 AM
Kimi K2: Model agentik sumber terbuka yang paling kuat
Jul 12, 2025 am 09:16 AM
Ingat banjir model Cina sumber terbuka yang mengganggu industri Genai awal tahun ini? Walaupun Deepseek mengambil sebahagian besar tajuk utama, Kimi K1.5 adalah salah satu nama yang terkenal dalam senarai. Dan model itu agak sejuk.
 Grok 4 vs Claude 4: Mana yang lebih baik?
Jul 12, 2025 am 09:37 AM
Grok 4 vs Claude 4: Mana yang lebih baik?
Jul 12, 2025 am 09:37 AM
Menjelang pertengahan tahun 2025, AI "perlumbaan senjata" dipanaskan, dan Xai dan Anthropic kedua-duanya mengeluarkan model perdana mereka, Grok 4 dan Claude 4. Kedua-dua model ini berada di hujung falsafah reka bentuk dan platform penempatan, namun mereka
 10 robot humanoid yang menakjubkan sudah berjalan di antara kita hari ini
Jul 16, 2025 am 11:12 AM
10 robot humanoid yang menakjubkan sudah berjalan di antara kita hari ini
Jul 16, 2025 am 11:12 AM
Tetapi kita mungkin tidak perlu menunggu 10 tahun untuk melihatnya. Malah, apa yang boleh dianggap sebagai gelombang pertama yang benar-benar berguna, mesin seperti manusia sudah ada di sini. Tahun -tahun kebelakangan ini telah melihat beberapa prototaip dan model pengeluaran melangkah keluar dari T
 Kejuruteraan Konteks adalah ' baru ' Kejuruteraan segera
Jul 12, 2025 am 09:33 AM
Kejuruteraan Konteks adalah ' baru ' Kejuruteraan segera
Jul 12, 2025 am 09:33 AM
Sehingga tahun sebelumnya, kejuruteraan segera dianggap sebagai kemahiran penting untuk berinteraksi dengan model bahasa yang besar (LLM). Walau bagaimanapun, baru -baru ini, LLM telah maju dengan ketara dalam kebolehan pemikiran dan pemahaman mereka. Sememangnya, jangkaan kami
 Aplikasi mudah alih Immersity Leia membawa kedalaman 3D ke foto sehari -hari
Jul 09, 2025 am 11:17 AM
Aplikasi mudah alih Immersity Leia membawa kedalaman 3D ke foto sehari -hari
Jul 09, 2025 am 11:17 AM
Dibina di atas enjin kedalaman saraf proprietari Leia, aplikasinya memproses imej dan menambah kedalaman semula jadi bersama -sama dengan gerakan simulasi -seperti kuali, zum, dan kesan paralaks -untuk membuat gulungan video pendek yang memberikan kesan melangkah ke SCE
 Apakah 7 jenis ejen AI?
Jul 11, 2025 am 11:08 AM
Apakah 7 jenis ejen AI?
Jul 11, 2025 am 11:08 AM
Gambar sesuatu yang canggih, seperti enjin AI yang bersedia memberikan maklum balas terperinci mengenai koleksi pakaian baru dari Milan, atau analisis pasaran automatik untuk perniagaan yang beroperasi di seluruh dunia, atau sistem pintar yang menguruskan armada kenderaan yang besar.
 Model AI ini tidak belajar bahasa, mereka belajar strategi
Jul 09, 2025 am 11:16 AM
Model AI ini tidak belajar bahasa, mereka belajar strategi
Jul 09, 2025 am 11:16 AM
Satu kajian baru dari penyelidik di King's College London dan University of Oxford berkongsi hasil apa yang berlaku ketika Openai, Google dan Anthropic dibuang bersama dalam pertandingan cutthroat berdasarkan dilema banduan berulang. Ini tidak
 Krisis Komando yang tersembunyi: Penyelidik Permainan AI untuk Diterbitkan
Jul 13, 2025 am 11:08 AM
Krisis Komando yang tersembunyi: Penyelidik Permainan AI untuk Diterbitkan
Jul 13, 2025 am 11:08 AM
Para saintis telah menemui kaedah yang bijak namun membimbangkan untuk memintas sistem. Julai 2025 menandakan penemuan strategi yang rumit di mana penyelidik memasukkan arahan yang tidak kelihatan ke dalam penyerahan akademik mereka - arahan rahsia ini adalah ekor
