


Python-Crawler-Methode zum Abrufen von Daten
Python-Crawler k?nnen HTTP-Anfragen über die Anforderungsbibliothek senden, HTML mit der Parsing-Bibliothek analysieren, Daten mit regul?ren Ausdrücken extrahieren oder ein Daten-Scraping-Framework verwenden, um Daten abzurufen. Mehr Wissen über Python-Crawler. Weitere Informationen finden Sie im Artikel unter diesem Thema. Die chinesische PHP-Website hei?t alle herzlich willkommen, vorbeizukommen und zu lernen.
 174
174
 12
12
Python-Crawler-Methode zum Abrufen von Daten

Python-Crawler-Methode zum Abrufen von Daten
Python-Crawler k?nnen HTTP-Anfragen über die Anforderungsbibliothek senden, HTML mit der Parsing-Bibliothek analysieren, Daten mit regul?ren Ausdrücken extrahieren oder ein Daten-Scraping-Framework verwenden, um Daten abzurufen. Detaillierte Einführung: 1. Die Anforderungsbibliothek sendet HTTP-Anforderungen wie Requests, URLB usw.; 2. Die Parsing-Bibliothek analysiert HTML wie BeautifulSoup, LXML usw.; 3. Regul?re Ausdrücke werden zum Extrahieren verwendet Beschreiben Sie Zeichenfolgenmuster. Tools k?nnen Daten extrahieren, die den Anforderungen entsprechen, indem sie Muster usw. abgleichen.
Nov 13, 2023 am 10:44 AM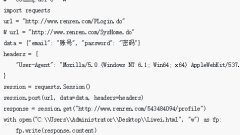
Grundlegende Verwendung der Anforderungsbibliothek
1. Der Unterschied zwischen Response.Content und Response.Text: Response.Content ist ein codierter Bytetyp (?str“-Datentyp) und Response.text ist ein Unicode-Typ. Der Einsatz dieser beiden Methoden h?ngt von der Situation ab. Hinweis: unicode -> str ist der Kodierungsprozess (encode()); str -> Ein Beispiel ist wie folgt: # --codin...
Jun 11, 2018 pm 10:55 PM
So verwenden Sie die Python-Webcrawler-Anforderungsbibliothek
1. Was ist ein Webcrawler? Einfach ausgedrückt: Er erstellt ein Programm zum automatisierten Herunterladen, Analysieren und Organisieren von Daten aus dem Internet. Genau wie beim Surfen im Internet kopieren wir die Inhalte, die uns interessieren, und fügen sie in unsere Notizbücher ein, damit wir sie beim n?chsten Mal leichter lesen und durchsuchen k?nnen. Der Webcrawler hilft uns natürlich dabei, diese Inhalte automatisch zu vervollst?ndigen, wenn wir auf Websites sto?en, die dies nicht k?nnen kopiert und eingefügt werden – Webcrawler k?nnen ihre Leistungsf?higkeit noch besser zur Geltung bringen, wenn wir Datenanalysen durchführen müssen – und diese Daten oft auf Webseiten gespeichert sind und es Zeit braucht, sie manuell herunterzuladen .
May 15, 2023 am 10:34 AM
Ein Artikel führt Sie durch die urllib-Bibliothek in Python (Bedienung von URLs).
Die Verwendung der Python-Sprache kann jedem helfen, Python besser zu lernen. Die von urllib bereitgestellte Funktion besteht darin, mithilfe von Programmen verschiedene HTTP-Anforderungen auszuführen. Wenn Sie einen Browser simulieren m?chten, um eine bestimmte Funktion auszuführen, müssen Sie die Anforderung als Browser tarnen. Die Tarnungsmethode besteht darin, zun?chst die vom Browser gesendeten Anforderungen zu überwachen und sie dann basierend auf dem Anforderungsheader des Browsers zu tarnen. Der User-Agent-Header wird zur Identifizierung des Browsers verwendet.
Jul 25, 2023 pm 02:08 PM
Was soll ich tun, wenn ich das Paket urllib2 in Python3.6 verwenden m?chte?
Das urllib2-Toolkit in Pyhton2 wurde in zwei Pakete aufgeteilt: urllib.request und urllib.error in Python3. Daher kann das Paket nicht gefunden werden und es gibt keine M?glichkeit, es zu installieren. Installieren Sie also diese beiden Pakete und verwenden Sie die Methode beim Importieren.
Jul 01, 2019 pm 02:18 PM
So verwenden Sie die Funktion urllib.urlopen() zum Senden einer GET-Anfrage in Python 2.x
Python ist eine beliebte Programmiersprache, die in Bereichen wie Webentwicklung, Datenanalyse und Automatisierungsaufgaben weit verbreitet ist. In der Python2.x-Version k?nnen Sie mithilfe der Funktion urlopen() der Bibliothek urllib ganz einfach GET-Anfragen senden und Antwortdaten abrufen. In diesem Artikel wird detailliert beschrieben, wie die Funktion urlopen() zum Senden von GET-Anfragen in Python2.x verwendet wird, und es werden entsprechende Codebeispiele bereitgestellt. Bevor wir eine GET-Anfrage mit der Funktion urlopen() senden, müssen wir zun?chst Folgendes tun
Jul 29, 2023 am 08:48 AM
Ausführliche Erl?uterung des URL-Crawlers, des Anforderungsmoduls und des Parse-Moduls von Python
urllib ist ein Toolkit in Python, das zur Verarbeitung von URLs verwendet wird. In diesem Artikel wird die Crawler-Entwicklung erl?utert. Schlie?lich ist die Entwicklung von Crawler-Anwendungen bei der Web-Internet-Datenerfassung sehr wichtig. Das Artikelverzeichnis des URL-Librequest-Moduls greift auf die URLRequest-Klasse zu. Das Parse-Modul anderer Klassen analysiert URL-Escapes in der URLrobots.txt-Datei
Mar 21, 2021 pm 03:15 PM
So verwenden Sie das Python-Beautifulsoup4-Modul
1. Grundlegende Wissenserg?nzung von BeautifulSoup4 BeautifulSoup4 ist eine Python-Analysebibliothek, die haupts?chlich zum Parsen von HTML und XML verwendet wird. Im Crawler-Wissenssystem wird mehr HTML analysiert. Der Installationsbefehl der Bibliothek lautet wie folgt: pipinstallbeautifulsoup4BeautifulSoup muss sich auf a verlassen Parser von Drittanbietern, h?ufig verwendete Parser und Vorteile: Python-Standardbibliothek, starke Fehlertoleranz; lxml-Parser: schnell, starke Fehlertoleranz; , Analysemethode und Durchsuchen Das Ger?t ist konsistent. Als n?chstes verwenden Sie einen Absatz
May 11, 2023 pm 10:31 PM
Verstehen Sie den Python-Crawler-Parser BeautifulSoup4 in einem Artikel
Dieser Artikel vermittelt Ihnen relevantes Wissen über Python und l?st haupts?chlich Probleme im Zusammenhang mit dem Crawler-Parser BeautifulSoup4. Beautiful Soup ist eine Python-Bibliothek, die Daten aus HTML- oder XML-Dateien extrahieren kann. Schauen wir uns an, wie das geht Implementieren Sie die übliche Dokumentennavigation, Suche und ?nderung von Dokumenten. Ich hoffe, dass dies für alle hilfreich ist.
Jul 12, 2022 pm 04:56 PM
So verwenden Sie den Python-Crawler zum Crawlen von Webseitendaten mithilfe von BeautifulSoup und Requests
1. Einführung Das Implementierungsprinzip von Webcrawlern l?sst sich in den folgenden Schritten zusammenfassen: Senden von HTTP-Anfragen: Webcrawler erhalten Webinhalte, indem sie HTTP-Anfragen (normalerweise GET-Anfragen) an die Zielwebsite senden. In Python k?nnen HTTP-Anfragen über die Requests-Bibliothek gesendet werden. HTML analysieren: Nachdem der Crawler die Antwort von der Zielwebsite erhalten hat, muss er den HTML-Inhalt analysieren, um nützliche Informationen zu extrahieren. HTML ist eine Auszeichnungssprache, die zur Beschreibung der Struktur von Webseiten verwendet wird. Sie besteht aus einer Reihe verschachtelter Tags. Der Crawler kann die erforderlichen Daten anhand dieser Tags und Attribute finden und extrahieren. In Python k?nnen Sie Bibliotheken wie BeautifulSoup und lxml zum Parsen von HTML verwenden. Datenextraktion: Nach dem Parsen des HTML-Codes
Apr 29, 2023 pm 12:52 PM
Regul?rer Python-Ausdruck – prüfen Sie, ob die Eingabe eine Gleitkommazahl ist
Gleitkommazahlen spielen bei einer Vielzahl von Programmieraufgaben eine wichtige Rolle, von mathematischen Berechnungen bis hin zur Datenanalyse. Beim Umgang mit Benutzereingaben oder Daten aus externen Quellen ist es jedoch wichtig zu überprüfen, ob es sich bei der Eingabe um eine gültige Gleitkommazahl handelt. Python bietet leistungsstarke Tools zur Bew?ltigung dieser Herausforderung, darunter regul?re Ausdrücke. In diesem Artikel erfahren Sie, wie Sie mit regul?ren Ausdrücken in Python prüfen, ob eine Eingabe eine Gleitkommazahl ist. Regul?re Ausdrücke (oft als Regex bezeichnet) bieten eine pr?zise und flexible M?glichkeit, Muster zu definieren und nach übereinstimmungen im Text zu suchen. Durch die Nutzung regul?rer Ausdrücke k?nnen wir ein Muster erstellen, das genau dem Gleitkommaformat entspricht, und die Eingabe entsprechend validieren. In diesem Artikel werden wir untersuchen, wie man Pyt verwendet
Sep 15, 2023 pm 04:09 PM
Was ist ein regul?rer Ausdruck?
Regul?rer Ausdruck ist ein Werkzeug zum Beschreiben, Abgleichen und Bearbeiten von Zeichenfolgen. Es handelt sich um ein Muster, das aus einer Reihe von Zeichen und Sonderzeichen besteht. Es wird zum Suchen, Ersetzen und Extrahieren von Zeichenfolgen verwendet, die mit bestimmten Mustern im Text übereinstimmen. Regul?re Ausdrücke werden in der Informatik und Softwareentwicklung h?ufig verwendet und k?nnen in der Textverarbeitung, Datenvalidierung, Mustervergleich und anderen Bereichen eingesetzt werden. Die Grundidee besteht darin, eine Art Zeichenfolge zu beschreiben, die bestimmten Regeln entspricht, indem ein Muster definiert wird, das aus gew?hnlichen Zeichen und Sonderzeichen besteht. Sonderzeichen werden zur Darstellung bestimmter Zeichen oder Zeichens?tze verwendet.
Nov 10, 2023 am 10:23 AM
Hei?er Artikel

Hei?e Werkzeuge
Kits AI
Verwandeln Sie Ihre Stimme mit KI-Künstlerstimmen. Erstellen und trainieren Sie Ihr eigenes KI-Sprachmodell.
SOUNDRAW - AI Music Generator
Erstellen Sie ganz einfach Musik für Videos, Filme und mehr mit dem KI-Musikgenerator von SOUNDRAW.
Web ChatGPT.ai
Kostenlose Chrome -Erweiterung mit OpenAI -Chatbot für ein effizientes Surfen.
YouWear
Kostenloser AI-T-Shirt-Designgenerator: Fotos oder Eingabeaufforderungen in Sekundenschnelle in benutzerdefinierte Kleidung verwandeln.
Keepmind
KI -Studienwerkzeug für Flitzkarten, Mind Maps, Tests und Abstandswiederholungen.

