
 Technologie-Peripherieger?te
KI
LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
Technologie-Peripherieger?te
KI
LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
May 09, 2024 pm 04:55 PM
Vorab geschrieben und das pers?nliche Verst?ndnis des Autors
Dieses Papier widmet sich der L?sung der wichtigsten Herausforderungen aktueller multimodaler gro?er Sprachmodelle (MLLMs) in autonomen Fahranwendungen, d. h. der Erweiterung von MLLMs vom 2D-Verst?ndnis auf den 3D-Raum Frage. Diese Erweiterung ist besonders wichtig, da autonome Fahrzeuge (AVs) genaue Entscheidungen über 3D-Umgebungen treffen müssen. Das r?umliche 3D-Verst?ndnis ist für AVs von entscheidender Bedeutung, da es sich direkt auf die F?higkeit des Fahrzeugs auswirkt, fundierte Entscheidungen zu treffen, zukünftige Zust?nde vorherzusagen und sicher mit der Umgebung zu interagieren.
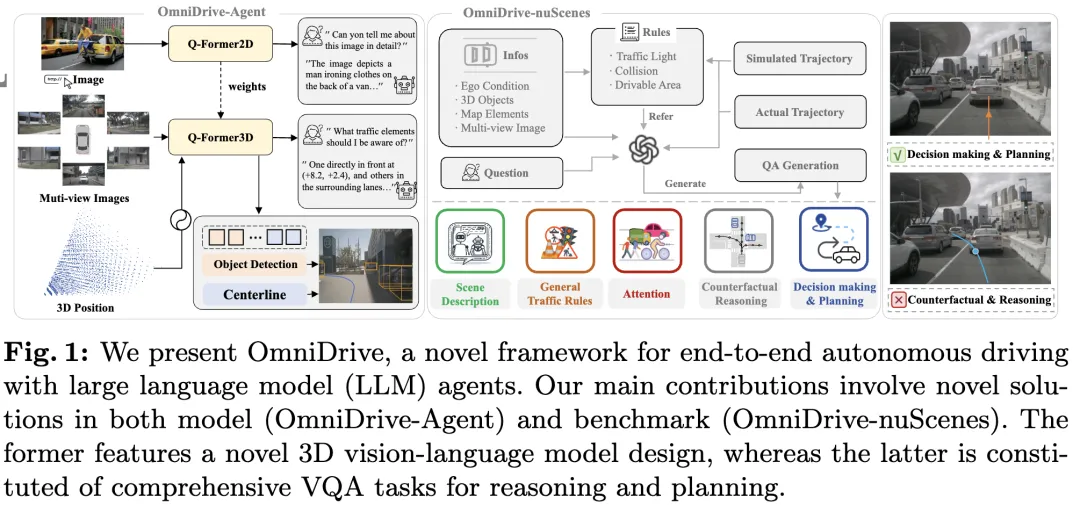
Aktuelle multimodale gro?e Sprachmodelle (wie LLaVA-1.5) k?nnen aufgrund von Aufl?sungsbeschr?nkungen des visuellen Encoders und LLM-Sequenzl?ngenbeschr?nkungen normalerweise nur Bildeingaben mit niedrigerer Aufl?sung verarbeiten (z. B.). Allerdings erfordern autonome Fahranwendungen einen hochaufl?senden Multi-View-Videoeingang, um sicherzustellen, dass Fahrzeuge die Umgebung wahrnehmen und über gro?e Entfernungen sichere Entscheidungen treffen k?nnen. Darüber hinaus haben viele bestehende 2D-Modellarchitekturen Schwierigkeiten, diese Eingaben effizient zu verarbeiten, da sie umfangreiche Rechen- und Speicherressourcen erfordern. Um diese Probleme anzugehen, arbeiten Forscher an der Entwicklung neuer Modellarchitekturen und Speicherressourcen.
In diesem Zusammenhang schl?gt dieses Papier eine neue 3D-MLLM-Architektur vor, die auf dem Design im Q-Former-Stil basiert. Die Architektur verwendet einen Cross-Attention-Decoder, um hochaufl?sende visuelle Informationen in sp?rliche Abfragen zu komprimieren und so die Skalierung auf hochaufl?sende Eingaben zu erleichtern. Diese Architektur weist ?hnlichkeiten mit Familien von Ansichtsmodellen wie DETR3D, PETR(v2), StreamPETR und Far3D auf, da sie alle sp?rliche 3D-Abfragemechanismen nutzen. Durch das Anh?ngen einer 3D-Positionskodierung an diese Abfragen und die Interaktion mit Multi-View-Eingaben erreicht unsere Architektur ein r?umliches 3D-Verst?ndnis und nutzt dadurch vorab trainiertes Wissen in 2D-Bildern besser.
Zus?tzlich zur Innovation der Modellarchitektur schl?gt dieser Artikel auch anspruchsvollere Benchmark-OmniDrive-nuScenes vor. Der Benchmark deckt eine Reihe komplexer Aufgaben ab, die ein 3D-Raumverst?ndnis und weitreichendes Denken erfordern, und führt einen Benchmark für kontrafaktisches Denken ein, um Ergebnisse durch Simulation von L?sungen und Trajektorien zu bewerten. Dieser Benchmark kompensiert effektiv das Problem der Bevorzugung eines einzelnen Expertenverlaufs in aktuellen offenen Bewertungen und vermeidet so eine überanpassung an Expertenverl?ufe.
In diesem Artikel wird OmniDrive vorgestellt, ein umfassendes End-to-End-Framework für autonomes Fahren, das ein effektives 3D-Argumentations- und Planungsmodell auf Basis des LLM-Agenten bereitstellt und einen anspruchsvolleren Benchmark bildet, der weitere Entwicklungen im Bereich des autonomen Fahrens vorantreibt. Die spezifischen Beitr?ge sind wie folgt:
- Vorgeschlagene 3D-Q-Former-Architektur geeignet für verschiedene fahrbezogene Aufgaben, einschlie?lich Zielerkennung, Fahrspurerkennung, visuelle 3D-Positionierung, Entscheidungsfindung und Planung.
- Wir stellen den OmniDrive-nuScenes-Benchmark vor, den ersten QA-Benchmark, der zur L?sung planungsbezogener Herausforderungen entwickelt wurde und genaue 3D-Rauminformationen abdeckt.
- Erzielen Sie die beste Leistung bei Planungsaufgaben.
Detaillierte Erl?uterung von OmniDrive
Gesamtstruktur
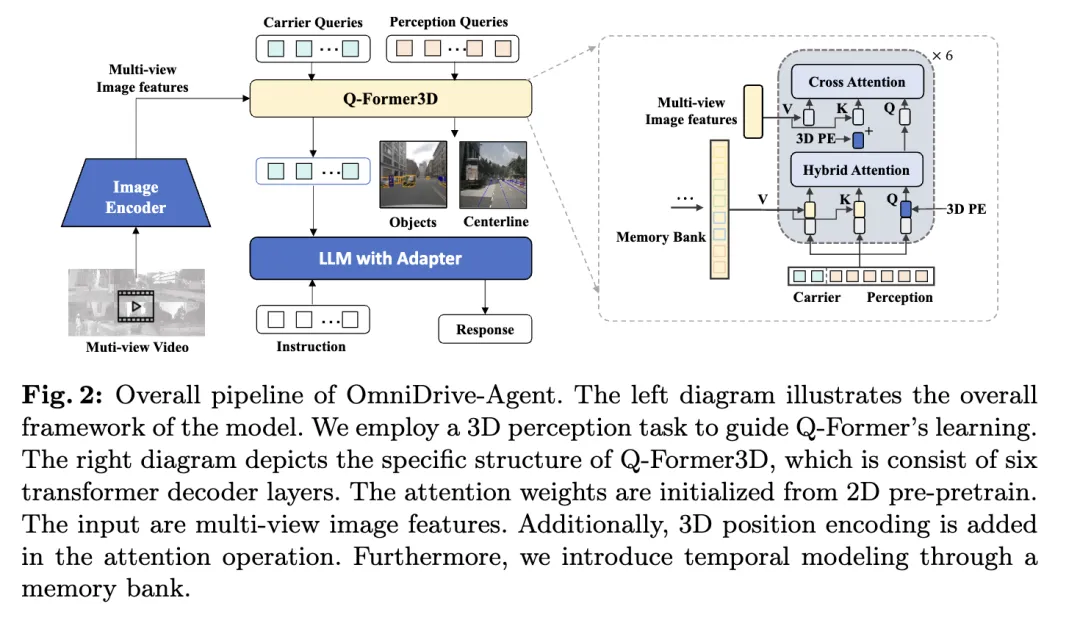
Der in diesem Artikel vorgeschlagene OmniDrive-Agent kombiniert die Vorteile von Q-Former und abfragebasierten 3D-Wahrnehmungsmodellen, um 3D-Rauminformationen effizient in mehreren zu erhalten -Bildfunktionen anzeigen, 3D-Wahrnehmungs- und Planungsaufgaben beim autonomen Fahren l?sen. Die Gesamtarchitektur ist in der Abbildung dargestellt.
- Visueller Encoder: Zun?chst wird ein gemeinsamer visueller Encoder verwendet, um Bildfunktionen für mehrere Ansichten zu extrahieren.
- Positionskodierung: Die extrahierten Bildmerkmale werden zusammen mit der Positionskodierung in Q-Former3D eingegeben.
- Q-Former3D-Modul: Unter diesen steht für den Splei?vorgang. Der Kürze halber wird in der Formel auf die Positionskodierung verzichtet. Nach diesem Schritt wird die Abfragesammlung zur interagierten . Darunter steht für die 3D-Positionskodierung und ist eine Funktion zur Mehrfachansicht von Bildern.
- Multi-View-Bild-Feature-Sammlung: Als n?chstes sammeln diese Abfragen Informationen aus Multi-View-Bildern:
- Abfrageinitialisierung und Selbstaufmerksamkeit: In Q-Former3D werden die Erkennungsabfrage und die Vektorabfrage initialisiert, und Selbstaufmerksamkeitsoperationen werden durchgeführt, um Informationen zwischen ihnen auszutauschen:
- Ausgabeverarbeitung:
- Vorhersage von Wahrnehmungsaufgaben: Vorhersage der Kategorie und Koordinaten von Vordergrundelementen mithilfe von Wahrnehmungsabfragen.
- Tr?gerabfrageausrichtung und Textgenerierung: Die Tr?gerabfrage wird über ein einschichtiges MLP an die Dimensionen des LLM-Tokens (z. B. die 4096-Dimension in LLaMA) ausgerichtet und weiter zur Textgenerierung verwendet.
- Die Rolle der Tr?gerabfrage
Durch dieses Architekturdesign kann OmniDrive-Agent effizient umfangreiche r?umliche 3D-Informationen aus Bildern mit mehreren Ansichten abrufen und diese mit LLM zur Textgenerierung kombinieren, um eine 3D-Raumwahrnehmung zu erm?glichen und Autonomes Fahren bietet neue L?sungen.
Multitasking und zeitliche Modellierung
Die Methode des Autors profitiert vom Multitasking-Lernen und der zeitlichen Modellierung. Beim Lernen mit mehreren Aufgaben kann der Autor spezifische Q-Former3D-Module für jede Wahrnehmungsaufgabe integrieren und eine einheitliche Initialisierungsstrategie übernehmen (siehe cref{Training Strategy}). In verschiedenen Aufgaben k?nnen Carrier-Anfragen Informationen über verschiedene Verkehrselemente sammeln. Die Implementierung des Autors umfasst Aufgaben wie die Mittellinienkonstruktion und die 3D-Objekterkennung. W?hrend der Trainings- und Inferenzphasen verwenden diese Module dieselbe 3D-Positionskodierung. Unsere Methode bereichert Aufgaben wie die Mittellinienkonstruktion und die 3D-Objekterkennung. W?hrend der Trainings- und Inferenzphasen verwenden diese Module dieselbe 3D-Positionskodierung. Unsere Methode bereichert Aufgaben wie die Mittellinienkonstruktion und die 3D-Objekterkennung. W?hrend der Trainings- und Inferenzphasen verwenden diese Module dieselbe 3D-Positionskodierung.
In Bezug auf die zeitliche Modellierung speichern die Autoren Wahrnehmungsabfragen mit Top-K-Klassifizierungswerten in der Speicherbank und verbreiten sie Frame für Frame. Die propagierte Abfrage interagiert durch Queraufmerksamkeit mit der Wahrnehmungsabfrage und der Tr?gerabfrage des aktuellen Frames und erweitert dadurch die Verarbeitungsf?higkeiten des Modells für Videoeingaben.
Trainingsstrategie
Die Trainingsstrategie von OmniDrive-Agent ist in zwei Phasen unterteilt: 2D-Vortraining und 3D-Feinabstimmung. In der Anfangsphase haben die Autoren zun?chst multimodale gro?e Modelle (MLLMs) für 2D-Bildaufgaben vorab trainiert, um Q-Former- und Vektorabfragen zu initialisieren. Nach dem Entfernen der Erkennungsabfrage kann das OmniDrive-Modell als standardm??iges visuelles Sprachmodell betrachtet werden, das in der Lage ist, Text basierend auf Bildern zu generieren. Daher nutzte der Autor die Trainingsstrategie und Daten von LLaVA v1.5, um OmniDrive vorab auf 558K-Bild- und Textpaaren zu trainieren. W?hrend des Vortrainings bleiben alle Parameter au?er Q-Former eingefroren. Anschlie?end wurden die MLLMs mithilfe des Befehlsoptimierungsdatensatzes von LLaVA v1.5 feinabgestimmt. W?hrend der Feinabstimmung bleibt der Bildencoder eingefroren und andere Parameter k?nnen trainiert werden.
In der 3D-Feinabstimmungsphase besteht das Ziel darin, die 3D-Positionierungsf?higkeiten des Modells zu verbessern und gleichzeitig seine semantischen 2D-Verst?ndnisf?higkeiten so weit wie m?glich beizubehalten. Zu diesem Zweck fügte der Autor dem ursprünglichen Q-Former 3D-Positionskodierungs- und Timing-Module hinzu. In dieser Phase verwendet der Autor die LoRA-Technologie, um den visuellen Encoder und das gro?e Sprachmodell mit einer kleinen Lernrate zu optimieren und Q-Former3D mit einer relativ gro?en Lernrate zu trainieren. In diesen beiden Phasen berücksichtigt die Verlustberechnung von OmniDrive-Agent nur den Textgenerierungsverlust, ohne die kontrastiven Lern- und Matching-Verluste in BLIP-2 zu berücksichtigen.
OmniDrive-nuScenes

Um das Fahren multimodaler gro?er Modellagenten zu bewerten, schlagen die Autoren OmniDrive-nuScenes vor, einen neuartigen Benchmark, der auf dem nuScenes-Datensatz basiert und hochwertige visuelle Fragenbeantwortung (QA) enth?lt. Ja, abdeckend Wahrnehmungs-, Argumentations- und Planungsaufgaben im 3D-Bereich.
Das Highlight von OmniDrive-nuScenes ist der vollautomatische QA-Generierungsprozess, der GPT-4 zur Generierung von Fragen und Antworten verwendet. ?hnlich wie LLaVA stellt unsere Pipeline 3D-f?hige Anmerkungen als Kontextinformationen für GPT-4 bereit. Auf dieser Grundlage nutzt der Autor au?erdem Verkehrsregeln und Planungssimulationen als zus?tzliche Eingaben, um GPT-4 dabei zu helfen, die 3D-Umgebung besser zu verstehen. Der Benchmark des Autors testet nicht nur die Wahrnehmungs- und Argumentationsf?higkeiten des Modells, sondern fordert auch das tats?chliche r?umliche Verst?ndnis und die Planungsf?higkeiten des Modells im 3D-Raum durch langfristige Probleme mit Aufmerksamkeit, kontrafaktischem Denken und Planung im offenen Regelkreis heraus, da diese Probleme eine Fahrplanung erfordern In den n?chsten Sekunden wird simuliert, um zur richtigen Antwort zu gelangen.
Zus?tzlich zum Generierungsprozess für Offline-Fragen und -Antworten schl?gt der Autor auch einen Prozess zur Online-Generierung verschiedener Positionierungsfragen vor. Dieser Prozess kann als implizite Datenverbesserungsmethode angesehen werden, um das r?umliche 3D-Verst?ndnis und die Argumentationsf?higkeiten des Modells zu verbessern.
Offline-Fragen-Antworten
Im Offline-QA-Generierungsprozess verwendet der Autor Kontextinformationen, um QA-Paare auf nuScenes zu generieren. Zun?chst generiert der Autor mit GPT-4 eine Szenenbeschreibung, fügt die dreiperspektivische Vorderansicht und die dreiperspektivische Rückansicht in zwei unabh?ngige Bilder zusammen und gibt sie in GPT-4 ein. Durch schnelle Eingabe kann GPT-4 Informationen wie Wetter, Zeit, Szenentyp usw. beschreiben und die Richtung jedes Betrachtungswinkels identifizieren. Gleichzeitig wird die Beschreibung nach Betrachtungswinkel vermieden, sondern der Inhalt relativ zum Position des eigenen Fahrzeugs.
Damit GPT-4V die relative r?umliche Beziehung zwischen Verkehrselementen besser verstehen kann, stellt der Autor die Beziehung zwischen Objekten und Fahrspurlinien in einer Dateibaumstruktur dar und basiert auf dem 3D-Begrenzungsrahmen des Objekts. Seine Informationen werden in eine Beschreibung in natürlicher Sprache umgewandelt.
Dann generierte der Autor Trajektorien, indem er verschiedene Fahrabsichten simulierte, einschlie?lich Spurhalten, Spurwechsel nach links und Spur nach rechts, und verwendete einen Tiefensuchalgorithmus, um die Spurmittellinien zu verbinden, um alle m?glichen Fahrpfade zu generieren. Darüber hinaus hat der Autor die Trajektorien des eigenen Fahrzeugs im nuScenes-Datensatz geclustert, repr?sentative Fahrwege ausgew?hlt und sie als Teil der simulierten Trajektorie verwendet.
Durch die Kombination verschiedener Kontextinformationen im Offline-QA-Generierungsprozess sind die Autoren schlie?lich in der Lage, mehrere Arten von QA-Paaren zu generieren, einschlie?lich Szenenbeschreibung, Aufmerksamkeitsobjekterkennung, kontrafaktisches Denken und Entscheidungsplanung. GPT-4 kann Bedrohungsobjekte anhand von Simulationen und Expertentrajektorien identifizieren und sinnvolle Fahrempfehlungen geben, indem es überlegungen zur Sicherheit des Fahrwegs anstellt.

Online-Fragen-Beantwortung
Um die 3D-Wahrnehmungsanmerkungen im autonomen Fahrdatensatz voll auszunutzen, hat der Autor w?hrend des Trainingsprozesses online eine gro?e Anzahl von Positionierungsaufgaben generiert. Diese Aufgaben sollen das r?umliche 3D-Verst?ndnis und die Argumentationsf?higkeiten des Modells verbessern, einschlie?lich:
- 2D-zu-3D-Lokalisierung: Bei einem 2D-Begrenzungsrahmen auf einer bestimmten Kamera muss das Modell die 3D-Attribute des entsprechenden Objekts bereitstellen. einschlie?lich Kategorie, Standort, Gr??e, Ausrichtung und Geschwindigkeit.
- 3D-Entfernung: Identifizieren Sie Verkehrselemente in der N?he des Zielorts anhand zuf?llig generierter 3D-Koordinaten und geben Sie deren 3D-Attribute an.
- Spur zu Objekten: Listen Sie basierend auf einer zuf?llig ausgew?hlten Spurmittellinie alle Objekte auf dieser Spur und ihre 3D-Eigenschaften auf.
Metriken
Der OmniDrive-nuScenes-Datensatz umfasst Szenenbeschreibungen, Open-Loop-Planung und kontrafaktische Argumentationsaufgaben. Jede Aufgabe konzentriert sich auf unterschiedliche Aspekte, was eine Bewertung anhand einer einzigen Metrik erschwert. Daher haben die Autoren unterschiedliche Bewertungskriterien für unterschiedliche Aufgaben entwickelt.
Für Aufgaben im Zusammenhang mit der Szenenbeschreibung (z. B. Szenenbeschreibung und Auswahl von Aufmerksamkeitsobjekten) verwendet der Autor h?ufig verwendete Sprachbewertungsindikatoren, einschlie?lich METEOR, ROUGE und CIDEr, um die Satz?hnlichkeit zu bewerten. In der Open-Loop-Planungsaufgabe verwenden die Autoren die Kollisionsrate und die Geschwindigkeit des überquerens von Stra?engrenzen, um die Leistung des Modells zu bewerten. Für die Aufgabe des kontrafaktischen Denkens verwenden die Autoren GPT-3.5, um Schlüsselw?rter in Vorhersagen zu extrahieren und diese Schlüsselw?rter mit der Grundwahrheit zu vergleichen, um Pr?zision und Erinnerung für verschiedene Unfallkategorien zu berechnen.
Experimentelle Ergebnisse
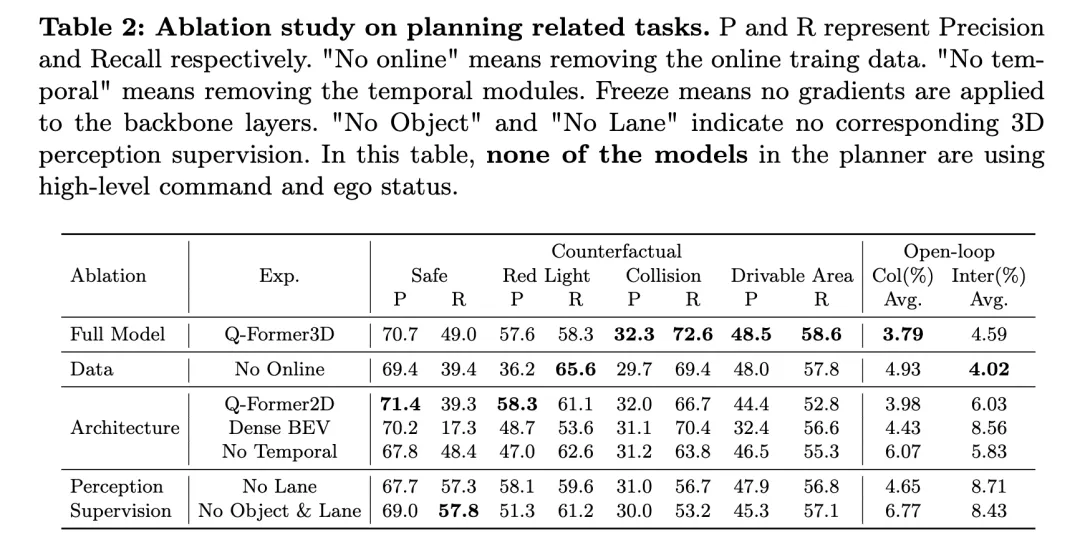
Die obige Tabelle zeigt die Ergebnisse der Ablationsforschung zu planungsbezogenen Aufgaben, einschlie?lich der Leistungsbewertung von kontrafaktischem Denken und Open-Loop-Planung.
Das vollst?ndige Modell, Q-Former3D, schneidet sowohl bei kontrafaktischen überlegungen als auch bei Planungsaufgaben mit offenem Regelkreis gut ab. Bei der Aufgabe zum kontrafaktischen Denken zeigte das Modell eine hohe Pr?zision und Erinnerungsraten sowohl in den Kategorien ?Versto? gegen die rote Ampel“ als auch ?Versto? gegen zug?ngliche Bereiche“, die jeweils bei 57,6 %/58,3 % und 48,5 %/58,6 % lagen. Gleichzeitig erreichte das Modell die h?chste Rückrufquote (72,6 %) in der Kategorie ?Kollision“. Bei der Open-Loop-Planungsaufgabe schnitt Q-Former3D sowohl bei der durchschnittlichen Kollisionsrate als auch bei der Kreuzungsrate von Stra?engrenzen gut ab und erreichte 3,79 % bzw. 4,59 %.
Nach dem Entfernen der Online-Trainingsdaten (No Online) stieg die Rückrufrate der Kategorie ?Rotlichtversto?“ in der Aufgabe zum kontrafaktischen Denken (65,6 %), die Gesamtleistung nahm jedoch leicht ab. Die Pr?zisionsrate und die Erinnerungsrate von Kollisionen und Verst??en gegen befahrbare Bereiche sind etwas niedriger als die des Gesamtmodells, w?hrend die durchschnittliche Kollisionsrate der Open-Loop-Planungsaufgabe auf 4,93 % stieg und die durchschnittliche Rate des überquerens von Stra?engrenzen auf 4,02 % sank. Dies spiegelt die Bedeutung von Online-Trainingsdaten für die Verbesserung der Gesamtplanungsleistung des Modells wider.
Im Architekturablationsexperiment erreichte die Q-Former2D-Version die h?chste Pr?zision (58,3 %) und den h?chsten Rückruf (61,1 %) in der Kategorie ?Rotlichtverletzung“, aber die Leistung in anderen Kategorien war nicht so gut wie die Vollversion Modell, insbesondere ?Rückrufe für die Kategorien ?Kollision“ und ?Verst??e gegen zug?ngliche Bereiche“ gingen deutlich zurück. Bei der Planungsaufgabe mit offenem Regelkreis sind die durchschnittliche Kollisionsrate und die Kreuzungsrate der Stra?engrenzen h?her als im Gesamtmodell, n?mlich 3,98 % bzw. 6,03 %.
Das Modell mit der Dense-BEV-Architektur schneidet bei allen Kategorien kontrafaktischer Argumentationsaufgaben besser ab, aber die Gesamtrückrufrate ist niedrig. Die durchschnittliche Kollisionsrate und die Kreuzungsrate von Stra?engrenzen in der Planungsaufgabe mit offenem Regelkreis erreichten 4,43 % bzw. 8,56 %.
Wenn das Zeitmodul entfernt wird (kein Temporal), sinkt die Leistung des Modells bei der Aufgabe des kontrafaktischen Denkens erheblich, insbesondere steigt die durchschnittliche Kollisionsrate auf 6,07 % und die Stra?engrenzüberschreitungsrate erreicht 5,83 %.
In Bezug auf die Wahrnehmungsüberwachung sank die Erinnerungsrate des Modells in der Kategorie ?Kollision“ nach dem Entfernen der Spurlinienüberwachung (?No Lane“) deutlich, w?hrend die Leistung anderer Kategorien kontrafaktischer Denkaufgaben und Planungsaufgaben mit offenem Regelkreis sank relativ Stabil. Nachdem die 3D-Wahrnehmungsüberwachung von Objekten und Fahrspurlinien vollst?ndig entfernt wurde (No Object & Lane), verringerten sich die Pr?zision und die Erinnerungsrate jeder Kategorie der kontrafaktischen Denkaufgabe, insbesondere sank die Erinnerungsrate der Kategorie ?Kollision“ auf 53,2 %. Die durchschnittliche Kollisionsrate und die Kreuzungsrate von Stra?engrenzen stiegen bei der Planungsaufgabe mit offenem Regelkreis auf 6,77 % bzw. 8,43 % und lagen damit deutlich über dem Gesamtmodell.
Wie aus den obigen experimentellen Ergebnissen ersichtlich ist, schneidet das vollst?ndige Modell bei kontrafaktischen Argumentations- und Open-Loop-Planungsaufgaben gut ab. Online-Trainingsdaten, Zeitmodule und die 3D-Wahrnehmungsüberwachung von Fahrspurlinien und Objekten spielen eine wichtige Rolle bei der Verbesserung der Modellleistung. Das vollst?ndige Modell kann multimodale Informationen effektiv für eine effiziente Planung und Entscheidungsfindung nutzen, und die Ergebnisse des Ablationsexperiments best?tigen die Schlüsselrolle dieser Komponenten bei autonomen Fahraufgaben weiter.
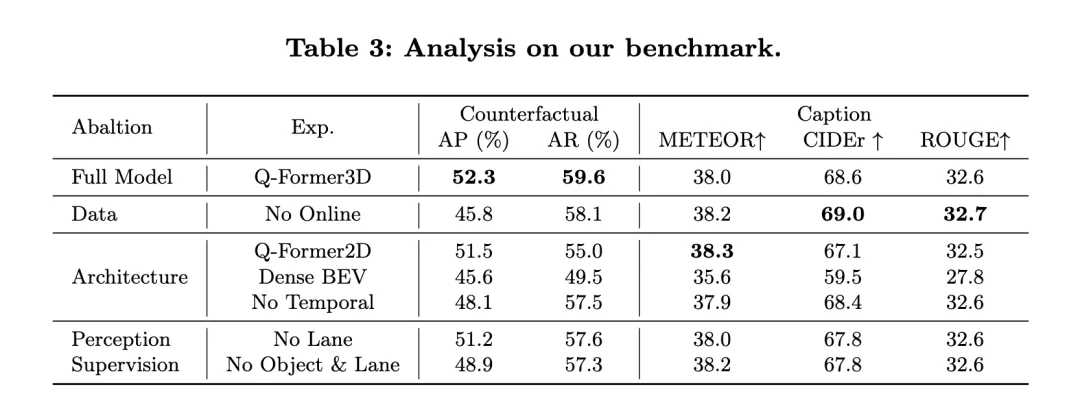
Pada masa yang sama, mari kita lihat prestasi NuScenes-QA: ia menunjukkan prestasi OmniDrive dalam tugas perancangan gelung terbuka dan membandingkannya dengan kaedah sedia ada yang lain. Keputusan menunjukkan bahawa OmniDrive++ (versi penuh) mencapai prestasi terbaik dalam semua penunjuk, terutamanya dalam ralat purata perancangan gelung terbuka, kadar perlanggaran dan kadar persimpangan sempadan jalan, yang lebih baik daripada kaedah lain.
Prestasi OmniDrive++: Model OmniDrive++ mempunyai ralat purata L2 sebanyak 0.14, 0.29 dan 0.55 meter dalam masa ramalan masing-masing 1 saat, 2 saat dan 3 saat, dan ralat purata akhir hanya 0.33 meter Selain itu, kadar perlanggaran purata dan purata kadar persimpangan sempadan jalan bagi model ini juga masing-masing mencapai 0.30% dan 3.00%, yang jauh lebih rendah daripada kaedah lain. Terutamanya dari segi kadar perlanggaran, OmniDrive++ mencapai kadar perlanggaran sifar dalam tempoh masa ramalan 1 saat dan 2 saat, menunjukkan sepenuhnya perancangan cemerlang dan keupayaan mengelak halangannya.
Perbandingan dengan kaedah lain: Berbanding model penanda aras lanjutan lain, seperti UniAD, BEV-Planner++ dan Ego-MLP, OmniDrive++ mengatasi semua metrik utama. Apabila UniAD menggunakan arahan peringkat tinggi dan maklumat status kenderaan sendiri, ralat purata L2nya ialah 0.46 meter, manakala OmniDrive++ mempunyai ralat yang lebih rendah iaitu 0.33 meter di bawah tetapan yang sama. Pada masa yang sama, kadar perlanggaran dan kadar persimpangan sempadan jalan OmniDrive++ juga jauh lebih rendah daripada UniAD, terutamanya kadar perlanggaran dikurangkan hampir separuh.
Berbanding dengan BEV-Planner++, ralat L2 OmniDrive++ dikurangkan dengan ketara dalam semua tempoh masa ramalan, terutamanya dalam tempoh masa ramalan 3 saat, ralat dikurangkan daripada 0.57 meter kepada 0.55 meter. Pada masa yang sama, OmniDrive++ juga lebih baik daripada BEV-Planner++ dari segi kadar perlanggaran dan kadar lintasan sempadan jalan menurun daripada 0.34% kepada 0.30%, dan kadar lintasan sempadan jalan menurun daripada 3.16% kepada 3.00%.
Percubaan Ablasi: Untuk menilai lebih lanjut kesan modul utama dalam seni bina OmniDrive terhadap prestasi, penulis juga membandingkan prestasi versi berbeza model OmniDrive. OmniDrive (yang tidak menggunakan arahan peringkat tinggi dan maklumat status kenderaan sendiri) adalah jauh lebih rendah daripada model lengkap dari segi ralat ramalan, kadar perlanggaran dan kadar lintasan sempadan jalan, terutamanya ralat L2 dalam tempoh ramalan 3 saat mencapai 2.84 meter, dengan purata Kadar perlanggaran adalah setinggi 3.79%.
Apabila hanya menggunakan model OmniDrive (tanpa arahan peringkat tinggi dan maklumat status kenderaan sendiri), ralat ramalan, kadar perlanggaran dan kadar persimpangan sempadan jalan telah bertambah baik, tetapi masih terdapat jurang berbanding model lengkap. Ini menunjukkan bahawa penyepaduan arahan peringkat tinggi dan maklumat status kenderaan sendiri mempunyai kesan yang ketara ke atas peningkatan prestasi perancangan keseluruhan model.
Secara keseluruhan, hasil percubaan jelas menunjukkan prestasi cemerlang OmniDrive++ dalam tugas perancangan gelung terbuka. Dengan menyepadukan maklumat berbilang mod, arahan peringkat tinggi dan maklumat status kenderaan sendiri, OmniDrive++ mencapai ramalan laluan yang lebih tepat dan kadar perlanggaran yang lebih rendah dan kadar persimpangan sempadan jalan dalam tugas perancangan yang kompleks, menyediakan maklumat untuk perancangan pemanduan autonomi dan membuat keputusan yang kukuh sokongan.
Perbincangan

Ejen OmniDrive dan dataset OmniDrive-nuScenes yang dicadangkan oleh pengarang memperkenalkan paradigma baharu dalam bidang model besar berbilang mod, yang mampu menyelesaikan masalah pemanduan dalam persekitaran 3D model tersebut Penilaian menyediakan penanda aras yang komprehensif. Walau bagaimanapun, setiap kaedah dan set data baru mempunyai kelebihan dan kekurangannya.
Ejen OmniDrive mencadangkan strategi latihan dua peringkat: pra-latihan 2D dan penalaan halus 3D. Dalam peringkat pra-latihan 2D, penjajaran yang lebih baik antara ciri imej dan model bahasa besar dicapai dengan pra-latihan Q-Former dan pertanyaan pembawa menggunakan set data berpasangan teks imej LLaVA v1.5. Dalam peringkat penalaan halus 3D, pengekodan maklumat kedudukan 3D dan modul masa diperkenalkan untuk meningkatkan keupayaan kedudukan 3D model. Dengan memanfaatkan LoRA untuk memperhalusi pengekod visual dan model bahasa, OmniDrive mengekalkan pemahaman semantik 2D sambil meningkatkan penguasaannya terhadap penyetempatan 3D. Strategi latihan berperingkat ini melepaskan sepenuhnya potensi model besar berbilang modal, memberikan persepsi, penaakulan dan keupayaan perancangan yang lebih kukuh dalam senario pemanduan 3D. Sebaliknya, OmniDrive-nuScenes berfungsi sebagai penanda aras baharu yang direka khusus untuk menilai keupayaan memandu model besar. Proses penjanaan QA automatik sepenuhnya menjana pasangan soalan-jawapan berkualiti tinggi melalui GPT-4, meliputi tugas yang berbeza daripada persepsi kepada perancangan. Di samping itu, tugas penentududukan yang dijana dalam talian juga menyediakan peningkatan data tersirat untuk model, membantunya lebih memahami persekitaran 3D. Kelebihan set data ini ialah ia bukan sahaja menguji persepsi dan keupayaan penaakulan model, tetapi juga menilai kefahaman spatial model dan keupayaan perancangan melalui masalah jangka panjang. Penanda aras komprehensif ini memberikan sokongan kukuh untuk pembangunan model besar pelbagai modal masa hadapan.
Walau bagaimanapun, ejen OmniDrive dan set data OmniDrive-nuScenes juga mempunyai beberapa kelemahan. Pertama, memandangkan ejen OmniDrive perlu memperhalusi keseluruhan model semasa peringkat penalaan halus 3D, keperluan sumber latihan adalah tinggi, yang meningkatkan masa latihan dan kos perkakasan dengan ketara. Di samping itu, penjanaan data OmniDrive-nuScenes bergantung sepenuhnya pada GPT-4 Walaupun ia memastikan kualiti dan kepelbagaian soalan, ia juga menyebabkan soalan yang dihasilkan lebih cenderung kepada model dengan keupayaan bahasa semula jadi yang kuat, yang mungkin menjadikan model itu. lebih bergantung kepada ujian penanda aras Berdasarkan ciri bahasa dan bukannya keupayaan pemanduan sebenar. Walaupun OmniDrive-nuScenes menyediakan penanda aras QA yang komprehensif, liputan senario pemanduannya masih terhad. Peraturan lalu lintas dan simulasi perancangan yang terlibat dalam set data hanya berdasarkan set data nuScenes, yang menyukarkan masalah yang dijana untuk mewakili sepenuhnya pelbagai senario pemanduan di dunia nyata. Selain itu, disebabkan sifat proses penjanaan data yang sangat automatik, soalan yang dijana pasti dipengaruhi oleh berat sebelah data dan reka bentuk segera.
Kesimpulan
Ejen OmniDrive dan dataset OmniDrive-nuScenes yang dicadangkan oleh pengarang membawa perspektif baharu dan penanda aras penilaian kepada penyelidikan model besar berbilang mod dalam adegan pemanduan 3D. Strategi latihan dua peringkat ejen OmniDrive berjaya menggabungkan pra-latihan 2D dan penalaan halus 3D, menghasilkan model yang cemerlang dalam persepsi, penaakulan dan perancangan. Sebagai penanda aras QA baharu, OmniDrive-nuScenes menyediakan penunjuk komprehensif untuk menilai model pemanduan besar. Walau bagaimanapun, penyelidikan lanjut masih diperlukan untuk mengoptimumkan keperluan sumber latihan model, menambah baik proses penjanaan set data, dan memastikan soalan yang dijana dengan lebih tepat mewakili persekitaran pemanduan kehidupan sebenar. Secara keseluruhannya, kaedah dan set data pengarang adalah sangat penting dalam memajukan penyelidikan model besar berbilang mod dalam bidang pemanduan, meletakkan asas yang kukuh untuk kerja masa depan.
Das obige ist der detaillierte Inhalt vonLLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Wie l?sst sich das Long-Tail-Problem in autonomen Fahrszenarien l?sen?
Jun 02, 2024 pm 02:44 PM
Wie l?sst sich das Long-Tail-Problem in autonomen Fahrszenarien l?sen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich w?hrend des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt h?tte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randf?lle bei autonomen Fahrzeugen, also m?gliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschr?nken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gel?st, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschr?nkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen geh?ren eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der ?Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randf?lle in autonomen Fahrzeugen (AVs). Randf?lle sind m?gliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die ?ra der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach ?unter Tr?nen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Ver?ffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesj?hrige Er?ffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus gr??er als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Das weltweit leistungsst?rkste Open-Source-MoE-Modell ist da, mit chinesischen F?higkeiten, die mit GPT-4 vergleichbar sind, und der Preis betr?gt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsst?rkste Open-Source-MoE-Modell ist da, mit chinesischen F?higkeiten, die mit GPT-4 vergleichbar sind, und der Preis betr?gt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die F?higkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsst?rkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine st?rkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erh?ht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz besch?ftigt
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der H?nde wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der H?nde wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist ver?ffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch ver?ffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen ?Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik v?llig autonom und ohne menschliches Eingreifen w?hrend des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine H?nde sind nicht nur taktil
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer gr??eren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem h?heren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, w?hrend KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, w?hrend KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!
Apr 15, 2024 am 09:01 AM
Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!
Apr 15, 2024 am 09:01 AM
Ollama ist ein superpraktisches Tool, mit dem Sie Open-Source-Modelle wie Llama2, Mistral und Gemma problemlos lokal ausführen k?nnen. In diesem Artikel werde ich vorstellen, wie man Ollama zum Vektorisieren von Text verwendet. Wenn Sie Ollama nicht lokal installiert haben, k?nnen Sie diesen Artikel lesen. In diesem Artikel verwenden wir das Modell nomic-embed-text[2]. Es handelt sich um einen Text-Encoder, der OpenAI text-embedding-ada-002 und text-embedding-3-small bei kurzen und langen Kontextaufgaben übertrifft. Starten Sie den nomic-embed-text-Dienst, wenn Sie o erfolgreich installiert haben
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fu?g?ngererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der gro?en radialen Verzerrung ist es schwierig, die standardm??ige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell ?fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Das Neueste von der Universit?t Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universit?t Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen gesch?tzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere gesch?tzten Posen sind ma?stabsunabh?ngig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posensch?tzung von Skalenmetriken und sind daher auf externe Tiefensch?tzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden k?nnen. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern k?nnen wir auf metrische Relativwerte schlie?en
