
 Backend-Entwicklung
PHP-Tutorial
Wie konfigurieren Sie Opcache effizient, um die Leistung der Produktionsumgebung zu verbessern?
Backend-Entwicklung
PHP-Tutorial
Wie konfigurieren Sie Opcache effizient, um die Leistung der Produktionsumgebung zu verbessern?
Wie konfigurieren Sie Opcache effizient, um die Leistung der Produktionsumgebung zu verbessern?
Apr 01, 2025 am 10:42 AM

PHP 7.3 OPCACHE -Leistungsstimmen: Best Practices der Produktion Umgebung
In PHP 7.3 -Produktionsumgebungen ist die Optimierung der Opcache -Konfiguration für die Leistung von entscheidender Bedeutung. In diesem Artikel wird Ihnen die Konfiguration von Opcache, die Maximierung der Cache -Effizienz, die Reduzierung der Serverlast und die Verbesserung der Reaktionsgeschwindigkeit der Anwendungen.
Detaillierte Erl?uterung der Kernkonfigurationsparameter:
Stellen Sie zun?chst sicher, dass Opcache aktiviert ist:
-
opcache.enable=1: OPCache -Switch aktivieren, muss auf 1 eingestellt werden.
Passen Sie als N?chstes Opcache -Speicherzuweisung an:
-
opcache.memory_consumption=512: opcache kann die Speichergr??e (MB) verwenden. 512 MB ist ein gemeinsamer Wert, muss jedoch entsprechend der Anwendungsskala und dem Codevolumen angepasst werden. Zu klein reduziert die Cache -Trefferquote und der zu gro?e Abfallspeicher.
String -Caching optimieren:
-
opcache.interned_strings_buffer=64: OPCACHE INTERNEHT STRING PUBER Gr??e (MB). Angemessene Konfiguration reduziert die String -Duplikation und verbessert die Leistung.
Steuern Sie die Anzahl der zwischengespeicherten Dateien:
-
opcache.max_accelerated_files=4000: OPCACHE speichert die maximale Anzahl von PHP -Dateien. Angeordnet nach der Projektgr??e verursacht zu kleiner Cache -Ausfall und überm??ig gro?er Erh?hung des Speicherverbrauchs.
Frequenz der Dateiüberprüfung festlegen:
-
opcache.revalidate_freq=1000: opcache prüft die Dateimodifikationsfrequenz (Sekunden). 1000 Sekunden (ca. 16 Minuten) sind ein gemeinsamer Wert, eine Ausgleichsleistung und die Aktualisierungsfestigkeit von Code -Update. überm??ige überprüfung erh?ht die CPU -Last.
Aktivieren Sie den CLI -Modus Opcache:
-
opcache.enable_cli=1: Wenn Sie Opcache in der Befehlszeile verwenden müssen, setzen Sie sich auf 1.
Einfache Konfiguration für die schnelle Leistungsverbesserung:
In vielen F?llen müssen Sie nur die folgenden zwei Elemente konfigurieren, um die Leistung erheblich zu verbessern:
-
opcache.enable=1: OPCache aktivieren. -
opcache.revalidate_freq=1000: Legt die überprüfungsfrequenz fest.
Die Konfiguration anderer Parameter muss gem?? den tats?chlichen Anwendungsbedingungen angepasst und getestet werden (Serverspeicher, Codegr??e, Aktualisierungsfrequenz usw.). Die kontinuierliche überwachung und Tests sind der Schlüssel zur Optimierung der Konfiguration.
Das obige ist der detaillierte Inhalt vonWie konfigurieren Sie Opcache effizient, um die Leistung der Produktionsumgebung zu verbessern?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Hei?e Themen



 Was tun, wenn Ihr Huawei-Telefon nicht über genügend Speicher verfügt (Praktische Methoden zur L?sung des Problems des unzureichenden Speichers)
Apr 29, 2024 pm 06:34 PM
Was tun, wenn Ihr Huawei-Telefon nicht über genügend Speicher verfügt (Praktische Methoden zur L?sung des Problems des unzureichenden Speichers)
Apr 29, 2024 pm 06:34 PM
Unzureichender Speicher auf Huawei-Mobiltelefonen ist mit der Zunahme mobiler Anwendungen und Mediendateien zu einem h?ufigen Problem geworden, mit dem viele Benutzer konfrontiert sind. Um Benutzern zu helfen, den Speicherplatz ihres Mobiltelefons voll auszunutzen, werden in diesem Artikel einige praktische Methoden vorgestellt, um das Problem des unzureichenden Speichers auf Huawei-Mobiltelefonen zu l?sen. 1. Cache bereinigen: Verlaufsdatens?tze und ungültige Daten, um Speicherplatz freizugeben und von Anwendungen generierte tempor?re Dateien zu l?schen. Suchen Sie in den Huawei-Telefoneinstellungen nach ?Speicher“, klicken Sie auf die Schaltfl?che ?Cache l?schen“ und l?schen Sie dann die Cache-Dateien der Anwendung. 2. Deinstallieren Sie selten verwendete Anwendungen: Um Speicherplatz freizugeben, l?schen Sie einige selten verwendete Anwendungen. Ziehen Sie es an den oberen Rand des Telefonbildschirms, drücken Sie lange auf das Symbol ?Deinstallieren“ der Anwendung, die Sie l?schen m?chten, und klicken Sie dann auf die Best?tigungsschaltfl?che, um die Deinstallation abzuschlie?en. 3.Mobile Anwendung auf
 Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Die bekannten gro?en Open-Source-Sprachmodelle wie Llama3 von Meta, Mistral- und Mixtral-Modelle von MistralAI und Jamba von AI21 Lab sind zu Konkurrenten von OpenAI geworden. In den meisten F?llen müssen Benutzer diese Open-Source-Modelle anhand ihrer eigenen Daten verfeinern, um das Potenzial des Modells voll auszusch?pfen. Es ist nicht schwer, ein gro?es Sprachmodell (wie Mistral) im Vergleich zu einem kleinen mithilfe von Q-Learning auf einer einzelnen GPU zu optimieren, aber die effiziente Feinabstimmung eines gro?en Modells wie Llama370b oder Mixtral blieb bisher eine Herausforderung . Deshalb Philipp Sch, technischer Leiter von HuggingFace
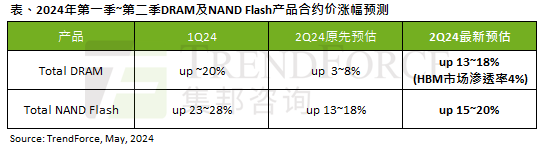 Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserh?hungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserh?hungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Laut einem TrendForce-Umfragebericht hat die KI-Welle erhebliche Auswirkungen auf die M?rkte für DRAM-Speicher und NAND-Flash-Speicher. In den Nachrichten dieser Website vom 7. Mai sagte TrendForce heute in seinem neuesten Forschungsbericht, dass die Agentur die Vertragspreiserh?hungen für zwei Arten von Speicherprodukten in diesem Quartal erh?ht habe. Konkret sch?tzte TrendForce ursprünglich, dass der DRAM-Speichervertragspreis im zweiten Quartal 2024 um 3 bis 8 % steigen wird, und sch?tzt ihn nun auf 13 bis 18 %, bezogen auf NAND-Flash-Speicher, die ursprüngliche Sch?tzung wird um 13 bis 18 % steigen 18 %, und die neue Sch?tzung liegt bei 15 %, nur eMMC/UFS weist einen geringeren Anstieg von 10 % auf. ▲B(niǎo)ildquelle TrendForce TrendForce gab an, dass die Agentur ursprünglich damit gerechnet hatte, dies auch weiterhin zu tun
 Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Die lokale Feinabstimmung von Deepseek-Klasse-Modellen steht vor der Herausforderung unzureichender Rechenressourcen und Fachkenntnisse. Um diese Herausforderungen zu bew?ltigen, k?nnen die folgenden Strategien angewendet werden: Modellquantisierung: Umwandlung von Modellparametern in Ganzzahlen mit niedriger Pr?zision und Reduzierung des Speicherboots. Verwenden Sie kleinere Modelle: W?hlen Sie ein vorgezogenes Modell mit kleineren Parametern für eine einfachere lokale Feinabstimmung aus. Datenauswahl und Vorverarbeitung: W?hlen Sie hochwertige Daten aus und führen Sie eine geeignete Vorverarbeitung durch, um eine schlechte Datenqualit?t zu vermeiden, die die Modelleffizienz beeinflusst. Batch -Training: Laden Sie für gro?e Datens?tze Daten in Stapel für das Training, um den Speicherüberlauf zu vermeiden. Beschleunigung mit GPU: Verwenden Sie unabh?ngige Grafikkarten, um den Schulungsprozess zu beschleunigen und die Trainingszeit zu verkürzen.
 Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
1. Rufen Sie zun?chst den Edge-Browser auf und klicken Sie auf die drei Punkte in der oberen rechten Ecke. 2. W?hlen Sie dann in der Taskleiste [Erweiterungen] aus. 3. Schlie?en oder deinstallieren Sie als N?chstes die Plug-Ins, die Sie nicht ben?tigen.
 Lassen Sie gro?e Modelle nicht l?nger ?Big Mac' sein. Dies ist die neueste überprüfung der effizienten Feinabstimmung gro?er Modellparameter.
Apr 28, 2024 pm 04:04 PM
Lassen Sie gro?e Modelle nicht l?nger ?Big Mac' sein. Dies ist die neueste überprüfung der effizienten Feinabstimmung gro?er Modellparameter.
Apr 28, 2024 pm 04:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte ver?ffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore gro?er Universit?ten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam f?rdern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen m?chten, k?nnen Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. In letzter Zeit haben sich gro? angelegte KI-Modelle wie gro?e Sprachmodelle und vinzentinische Graphenmodelle rasant entwickelt. In dieser Situation ist die Anpassung an sich schnell ?ndernde Anforderungen und die schnelle Anpassung gro?er Modelle an verschiedene nachgelagerte Aufgaben zu einer wichtigen Herausforderung geworden. Begrenzt durch Rechenressourcen, traditionelle Vollparameter-Mikro
 Laravel eloquent orm bei bangla partieller Modellsuche)
Apr 08, 2025 pm 02:06 PM
Laravel eloquent orm bei bangla partieller Modellsuche)
Apr 08, 2025 pm 02:06 PM
Laraveleloquent-Modellab Abruf: Das Erhalten von Datenbankdaten Eloquentorm bietet eine pr?gnante und leicht verst?ndliche M?glichkeit, die Datenbank zu bedienen. In diesem Artikel werden verschiedene eloquente Modellsuchtechniken im Detail eingeführt, um Daten aus der Datenbank effizient zu erhalten. 1. Holen Sie sich alle Aufzeichnungen. Verwenden Sie die Methode All (), um alle Datens?tze in der Datenbanktabelle zu erhalten: UseApp \ Models \ post; $ posts = post :: all (); Dies wird eine Sammlung zurückgeben. Sie k?nnen mit der Foreach-Schleife oder anderen Sammelmethoden auf Daten zugreifen: foreach ($ postas $ post) {echo $ post->
 Welche Warnungen oder Vorbehalte sollten in der Golang-Funktionsdokumentation enthalten sein?
May 04, 2024 am 11:39 AM
Welche Warnungen oder Vorbehalte sollten in der Golang-Funktionsdokumentation enthalten sein?
May 04, 2024 am 11:39 AM
Die Go-Funktionsdokumentation enth?lt Warnungen und Vorbehalte, die für das Verst?ndnis potenzieller Probleme und die Vermeidung von Fehlern unerl?sslich sind. Dazu geh?ren: Parametervalidierungswarnung: überprüfen Sie die Parametergültigkeit. überlegungen zur Parallelit?tssicherheit: Geben Sie die Thread-Sicherheit einer Funktion an. Leistungsaspekte: Heben Sie den hohen Rechenaufwand oder Speicherbedarf einer Funktion hervor. Anmerkung zum Rückgabetyp: Beschreibt den von der Funktion zurückgegebenen Fehlertyp. Abh?ngigkeitshinweis: Listet externe Bibliotheken oder Pakete auf, die für die Funktion erforderlich sind. Veraltungswarnung: Zeigt an, dass eine Funktion veraltet ist, und schl?gt eine Alternative vor.
