
 Peranti teknologi
AI
Model dunia penjanaan video adegan pemanduan berbilang paparan autonomi |
Peranti teknologi
AI
Model dunia penjanaan video adegan pemanduan berbilang paparan autonomi |
Model dunia penjanaan video adegan pemanduan berbilang paparan autonomi |
Oct 23, 2023 am 11:13 AM
Beberapa pemikiran peribadi pengarang
Dalam bidang pemanduan autonomi, dengan pembangunan sub-tugas/penyelesaian hujung-ke-hujung berasaskan BEV, data latihan berbilang-pandangan berkualiti tinggi dan simulasi yang sepadan pembinaan tempat kejadian semakin penting . Sebagai tindak balas kepada titik kesakitan tugas semasa, "kualiti tinggi" boleh dipecahkan kepada tiga aspek:
- Senario ekor panjang dalam dimensi berbeza: seperti kenderaan jarak dekat dalam data halangan dan sudut arah yang tepat semasa pemotongan kereta . Serta senario seperti lengkung dengan lengkungan yang berbeza atau tanjakan/cantuman/cantuman yang sukar dikumpul dalam data garisan lorong. Ini selalunya bergantung pada sejumlah besar pengumpulan data dan strategi perlombongan data yang kompleks, yang mahal.
- Nilai sebenar 3D - ketekalan imej yang tinggi: Pemerolehan data BEV semasa sering dipengaruhi oleh ralat dalam pemasangan/penentukuran sensor, peta berketepatan tinggi dan algoritma pembinaan semula itu sendiri. Ini menyukarkan kami untuk memastikan bahawa setiap set [3D true values-image-sensor parameters] dalam data adalah tepat dan konsisten.
- Data siri masa berdasarkan memenuhi syarat di atas: imej berbilang paparan bingkai berturut-turut dan nilai sebenar sepadan, yang penting untuk persepsi/ramalan/membuat keputusan/hujung-ke-akhir dan tugasan lain semasa.
Untuk simulasi, penjanaan video yang memenuhi syarat di atas boleh dijana terus melalui reka letak, yang sudah pasti cara paling langsung untuk membina input sensor berbilang ejen. DrivingDiffusion menyelesaikan masalah di atas dari perspektif baharu.
Apakah itu DrivingDiffusion?
- DrivingDiffusion ialah rangka kerja model resapan untuk penjanaan pemandangan pemanduan autonomi, yang masing-masing melaksanakan reka letakterkawal penjanaan imej/video berbilang dan melaksanakan SOTA.
- DrivingDiffusion-Future sebagai model dunia pemanduan autonomi mempunyai keupayaan untuk meramalkan video adegan masa hadapan berdasarkan imej bingkai tunggal dan mempengaruhi perancangan gerakan kenderaan utama/kenderaan lain berdasarkan gesaan bahasa.
Apakah kesan penjanaan DrivingDiffusion?
Pelajar yang memerlukan boleh terlebih dahulu melihat laman utama projek: https://drivingdiffusion.github.io(1) DrivingDiffusion
Penjanaan imej berbilang perspektif dengan kawalan reka letak
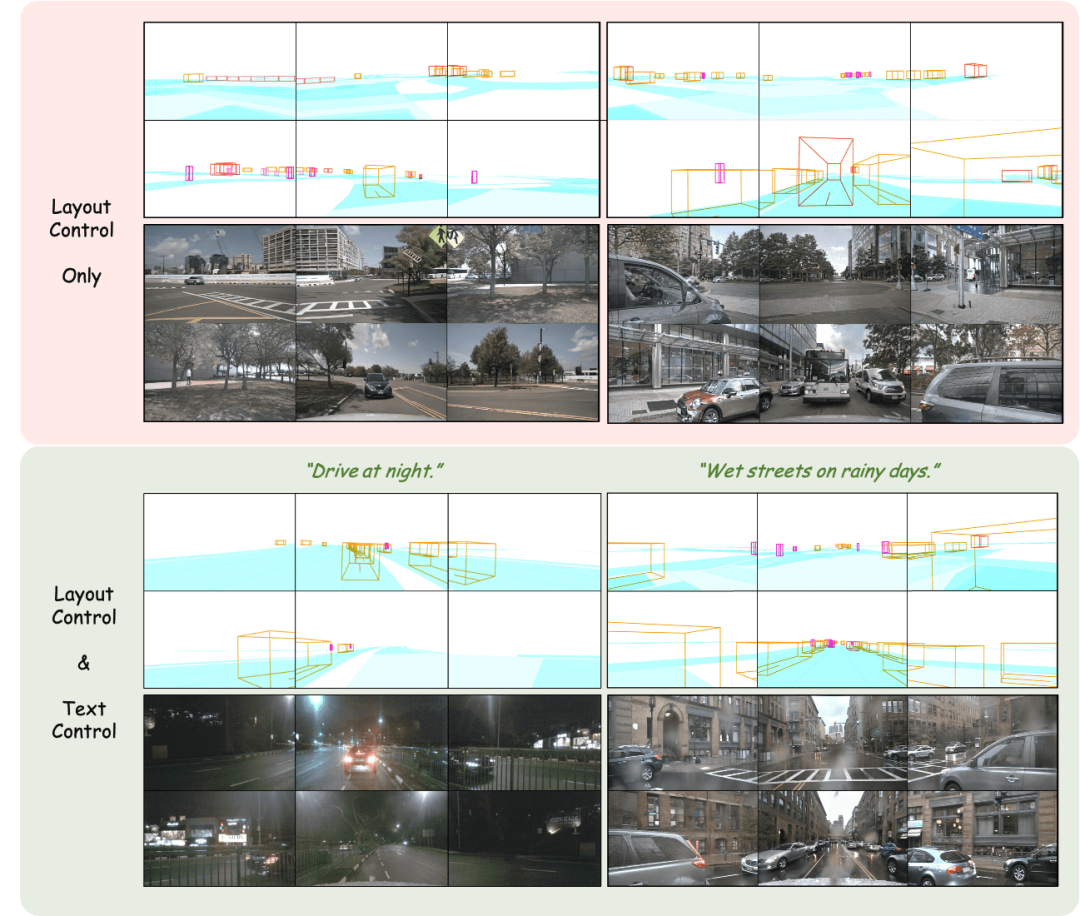
Laraskan reka letak: Kawal dengan tepat hasil yang dijana

Penjanaan video berbilang paparan terkawal reka letak
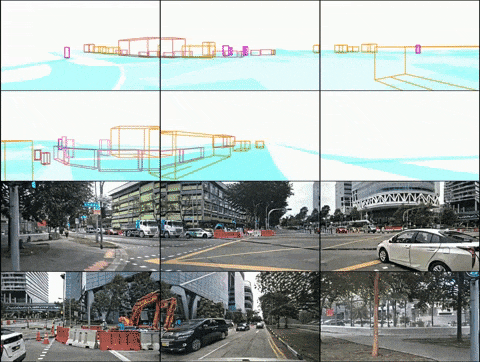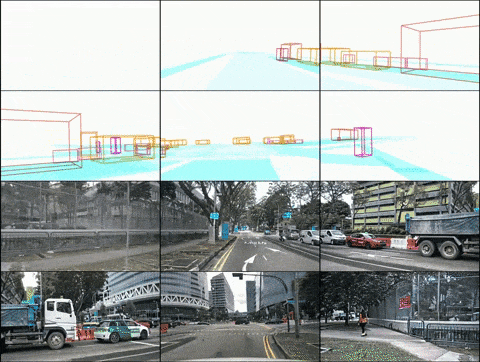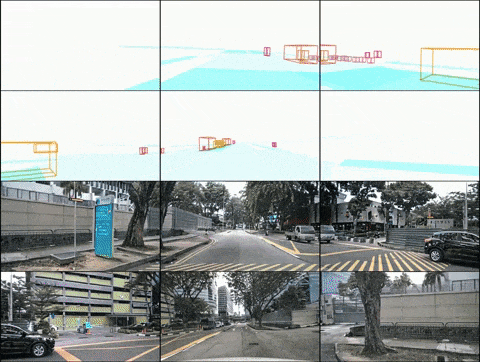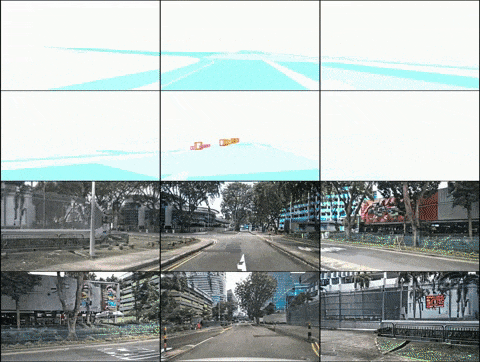

(2) DrivingDiffusion-Future
Janakan bingkai berikutnya berdasarkan bingkai input + keterangan teks

Secara langsung menjana bingkai seterusnya berdasarkan bingkai input

Bagaimanakah DrivingDiffusion menyelesaikan masalah di atas?
DrivingDiffusion mula-mula membina secara buatan semua nilai sebenar 3D (halangan/struktur jalan) di tempat kejadian Selepas menayangkan nilai sebenar ke dalam imej Layout, ia digunakan sebagai input model untuk mendapatkan imej/video sebenar daripada berbilang kamera. perspektif. Sebab mengapa nilai benar 3D (pandangan BEV atau contoh yang dikodkan) tidak digunakan secara langsung sebagai input model, tetapi parameter digunakan untuk input pasca unjuran, adalah untuk menghapuskan ralat konsistensi 3D-2D yang sistematik. (Dalam set data sedemikian, nilai sebenar 3D dan parameter kenderaan dibina secara buatan mengikut keperluan sebenar. Yang pertama membawa keupayaan untuk membina data pemandangan yang jarang berlaku sesuka hati , dan yang terakhir menghapuskan Ralat pengeluaran data tradisional dalam ketekalan geometri)
Masih ada satu soalan lagi buat masa ini: Bolehkah kualiti imej/video yang dijana memenuhi keperluan penggunaan? Apabila membina senario, semua orang sering berfikir untuk menggunakan enjin simulasi Walau bagaimanapun, terdapat jurang domain yang besar antara data yang dijana dan data sebenar. Hasil yang dihasilkan kaedah berasaskan GAN selalunya mempunyai berat sebelah tertentu daripada pengedaran data sebenar sebenar. Model Penyebaran adalah berdasarkan ciri-ciri rantai Markov yang menjana data dengan mempelajari bunyi bising Kesetiaan hasil yang dihasilkan adalah lebih tinggi dan lebih sesuai untuk digunakan sebagai pengganti kepada data sebenar. DrivingDiffusion secara langsung menjanapandangan berbilang paparan berurutan berdasarkan adegan yang dibina secara buatan dan parameter kenderaan, yang bukan sahaja boleh digunakan sebagai data latihan untuk tugas pemanduan autonomi hiliran, tetapi juga membina sistem simulasi autonomi untuk maklum balas algoritma memandu.
"Adegan buatan buatan" di sini hanya mengandungi halangan dan maklumat struktur jalan, tetapi rangka kerja DrivingDiffusion boleh memperkenalkan maklumat susun atur seperti papan tanda, lampu isyarat, kawasan pembinaan dan juga mod kawalan seperti grid/peta kedalaman pendudukan peringkat rendah.Ikhtisar kaedah DrivingDiffusion
Terdapat beberapa kesukaran semasa menjana video berbilang tontonan:
- Berbanding dengan penjanaan imej biasa, penjanaan video berbilang tontonan menambah dua dimensi dan pemasakan baharu:
- . Bagaimana untuk mereka bentuk rangka kerja yang boleh menghasilkan video panjang? Bagaimana untuk mengekalkan ketekalan pandangan silang dan ketekalan bingkai silang? Model stable-diffusion-v1-4 digunakan sebagai model pra-latihan untuk imej, dan menggunakan pseudo-convolution 3D untuk mengembangkan input imej asal, yang digunakan untuk memproses dimensi baharu siri perspektif/masa dan kemudian dimasukkan ke dalam 3D-Unet Selepas memproses model penyebaran dimensi baharu, pengembangan video berulang bergantian telah dijalankan, dan konsistensi keseluruhan jujukan jangka pendek dan jangka panjang dipastikan melalui operasi kawalan bingkai kunci dan fine- penalaan. Selain itu, DrivingDiffusion mencadangkan Modul Konsistensi dan Prompt Setempat, yang masing-masing menyelesaikan masalah ketekalan pandangan silang/rentas bingkai dan kualiti contoh.
- DrivingDiffusion menjana proses video yang panjang
Model berbilang paparan bingkai tunggal: menjana bingkai kekunci berbilang paparan,
menggunakan bingkai utama sebagai kawalan tambahan, model pemasaan paparan tunggal dikongsi berbilang paparan: melaksanakan pemasaan pada setiap paparan dalam Sambungan selari, Model berbilang paparan bingkai tunggal dengan hasil yang dijana sebagai kawalan tambahan: memperhalusi bingkai berikutnya dalam selari temporal,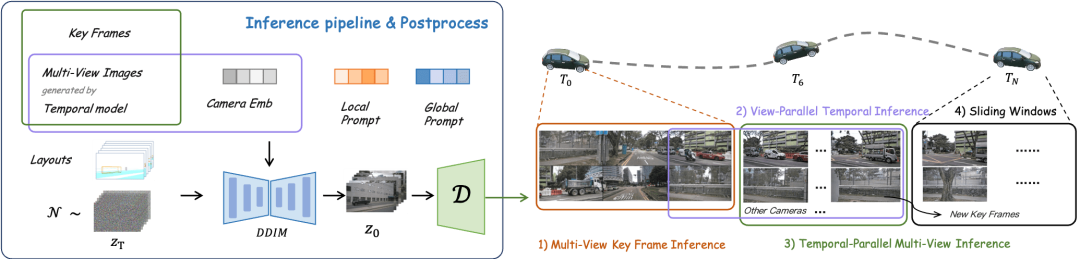 tentukan bingkai utama baharu dan lanjutkan video melalui tetingkap gelongsor.
tentukan bingkai utama baharu dan lanjutkan video melalui tetingkap gelongsor.
- Rangka kerja latihan untuk model pandangan silang dan model temporal
-
- Untuk model berbilang paparan dan model pemasaan, dimensi lanjutan 3D-Unet ialah perspektif dan masa masing-masing. Kedua-duanya mempunyai pengawal susun atur yang sama. Penulis percaya bahawa bingkai berikutnya boleh mendapatkan maklumat dalam adegan daripada bingkai utama berbilang paparan dan secara tersirat mempelajari maklumat berkaitan sasaran yang berbeza. Kedua-duanya menggunakan modul perhatian konsistensi yang berbeza dan modul Prompt Tempatan yang sama masing-masing.
- Pengekodan reka letak: Maklumat kategori/contoh halangan dan susun atur pembahagian struktur jalan dikodkan ke dalam imej RGB dengan nilai pengekodan tetap berbeza, dan token reka letak dikeluarkan selepas pengekodan.
- Kawalan bingkai kunci: Semua proses pengembangan siri masa menggunakan imej berbilang paparan bagi bingkai kunci tertentu Ini berdasarkan andaian bahawa bingkai berikutnya dalam siri masa yang singkat boleh mendapatkan maklumat daripada bingkai kunci. Semua proses penalaan halus menggunakan bingkai utama dan imej berbilang paparan bagi bingkai berikutnya yang dijana olehnya sebagai kawalan tambahan dan mengeluarkan imej berbilang paparan selepas mengoptimumkan ketekalan pandangan silang bingkai.
- Aliran optik terdahulu berdasarkan perspektif tertentu: Untuk model temporal, hanya data daripada perspektif tertentu diambil sampel semasa latihan. Selain itu, nilai terdahulu aliran optik bagi setiap kedudukan piksel di bawah imej perspektif, yang dikira terlebih dahulu, dikodkan dan digunakan sebagai token ID kamera untuk melaksanakan kawalan interaktif lapisan tersembunyi yang serupa dengan pembenaman masa dalam proses penyebaran.
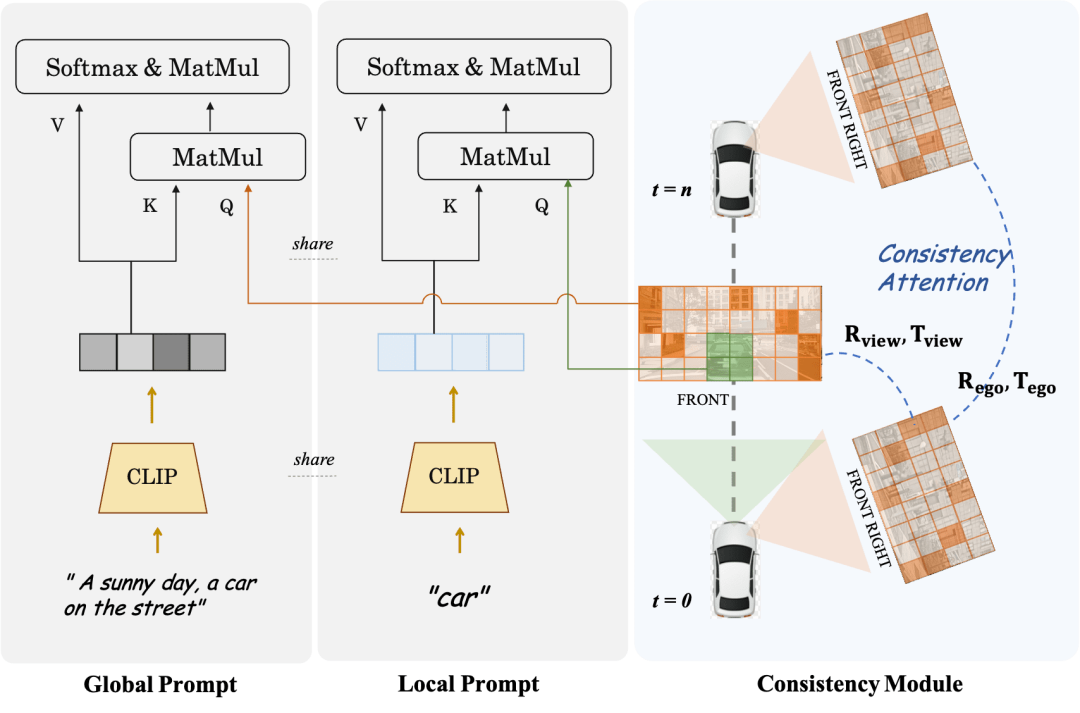
Modul Konsistensi & Prompt Tempatan

Modul Konsistensi terbahagi kepada dua bahagian: Mekanisme Perhatian Konsisten dan Kehilangan Persatuan Konsisten.
Mekanisme perhatian konsisten memfokuskan pada interaksi antara pandangan bersebelahan dan bingkai berkaitan temporal Khususnya, untuk ketekalan bingkai silang, ia hanya memfokuskan pada interaksi maklumat antara pandangan bersebelahan kiri dan kanan yang bertindih Untuk model temporal, setiap bingkai sahaja memfokuskan pada bingkai kunci dan bingkai sebelumnya. Ini mengelakkan beban pengiraan yang besar yang disebabkan oleh interaksi global.
Kehilangan korelasi yang konsisten menambah kekangan geometri dengan korelasi mengikut piksel dan mengundur pose, yang kecerunannya disediakan oleh regressor pose yang telah terlatih. Regressor menambah kepala regresi pose berdasarkan LoFTR dan dilatih menggunakan nilai pose sebenar pada data sebenar set data yang sepadan. Untuk model berbilang paparan dan model siri masa, modul ini masing-masing menyelia pose relatif kamera dan pose gerakan kenderaan utama.
Local Prompt dan Global Prompt bekerjasama untuk menggunakan semula semantik parameter CLIP dan stable-diffusion-v1-4 untuk mempertingkatkan kawasan contoh kategori tertentu secara tempatan. Seperti yang ditunjukkan dalam rajah, berdasarkan mekanisme perhatian silang token imej dan gesaan penerangan teks global, pengarang mereka bentuk gesaan tempatan untuk kategori tertentu dan menggunakan token imej dalam kawasan topeng kategori untuk menanyakan tempatan. segera. Proses ini menggunakan maksimum konsep penjanaan imej berpandukan teks dalam domain terbuka dalam parameter model asal.
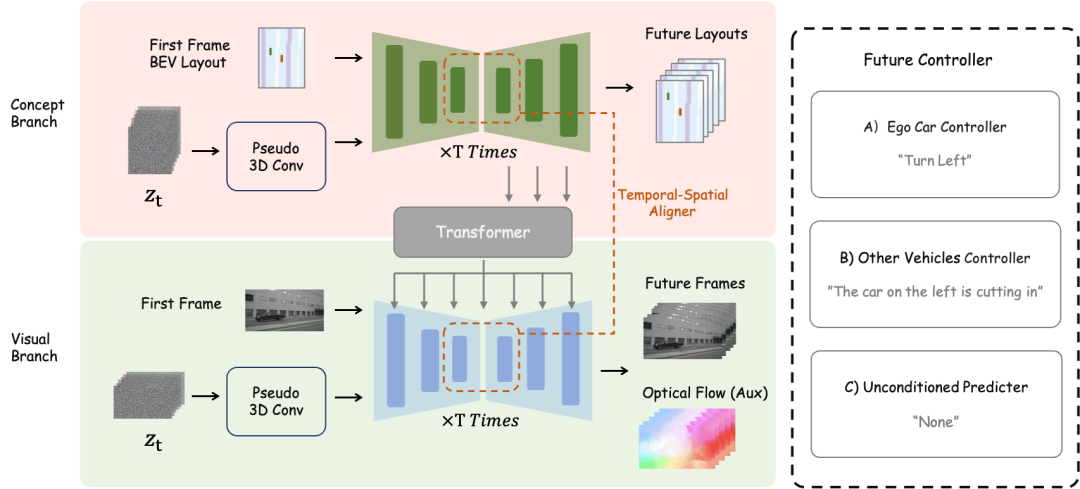
Ikhtisar kaedah DrivingDiffusion-Future
Untuk tugas pembinaan adegan masa hadapan, DrivingDiffusion-Future menggunakan dua kaedah: satu ialah meramalkan imej bingkai berikutnya (cawangan visual) terus daripada imej bingkai pertama, dan Gunakan aliran optik bingkai sebagai kehilangan tambahan. Kaedah ini agak mudah, tetapi kesan penjanaan bingkai berikutnya berdasarkan penerangan teks adalah purata. Cara lain ialah menambah cawangan konsep baharu berdasarkan bekas, yang meramalkan paparan BEV bagi bingkai berikutnya melalui paparan BEV bagi bingkai pertama Ini kerana ramalan pandangan BEV membantu model menangkap maklumat teras pemanduan adegan dan mewujudkan konsep. Pada masa ini, perihalan teks bertindak pada kedua-dua cawangan pada masa yang sama, dan ciri-ciri cabang konsep bertindak pada cawangan visual melalui modul penukaran perspektif BEV2PV Beberapa parameter modul penukaran perspektif telah dilatih dengan menggunakan imej nilai benar untuk menggantikan input hingar (dan dalam Pembekuan semasa latihan berikutnya). Perlu diingat bahawa pengawal keterangan teks kawalan kenderaan utama dan pengawal penerangan teks kawalan kenderaan/persekitaran lain dipisahkan.
Analisis Eksperimen
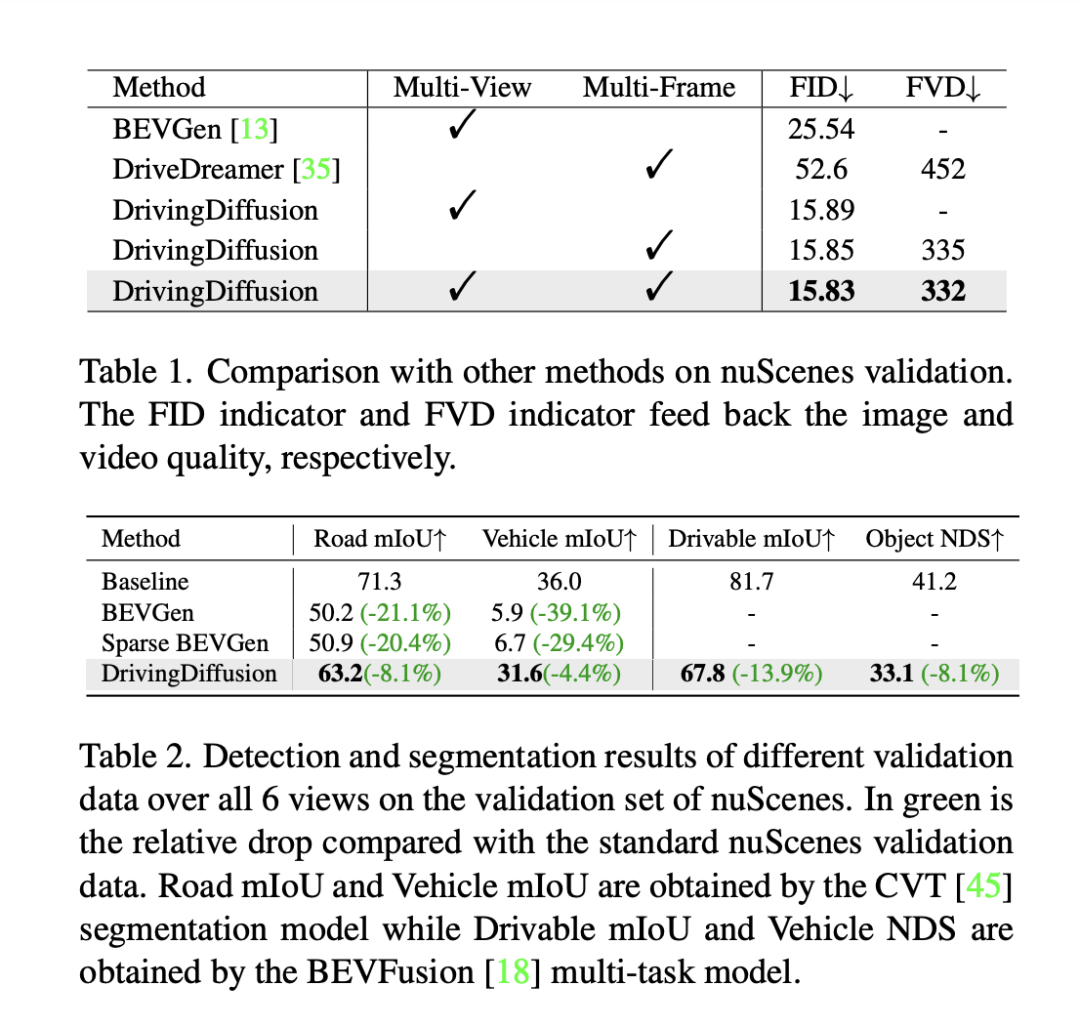
Untuk menilai prestasi model, DrivingDiffusion menggunakan Fréchet Inception Distance (FID) peringkat bingkai untuk menilai kualiti imej yang dijana, dan dengan itu menggunakan FVD untuk menilai kualiti video yang dijana. Semua metrik dikira pada set pengesahan nuScenes. Seperti yang ditunjukkan dalam Jadual 1, berbanding dengan tugas penjanaan imej BEVGen dan tugas penjanaan video DriveDreamer dalam senario pemanduan autonomi, DrivingDiffusion mempunyai kelebihan yang lebih besar dalam penunjuk prestasi di bawah tetapan yang berbeza.
Walaupun kaedah seperti FID sering digunakan untuk mengukur kualiti sintesis imej, kaedah ini tidak memberi maklum balas sepenuhnya terhadap matlamat reka bentuk tugasan, dan juga tidak mencerminkan kualiti sintesis untuk kategori semantik yang berbeza. Memandangkan tugas itu dikhususkan untuk menjana imej berbilang paparan selaras dengan reka letak 3D, DrivingDiffuison mencadangkan untuk menggunakan metrik model persepsi BEV untuk mengukur prestasi dari segi ketekalan: menggunakan model rasmi CVT dan BEVFusion sebagai penilai, menggunakan model 3D sebenar yang sama sebagai set pengesahan nuScenes Jana imej secara bersyarat pada susun atur, lakukan inferens CVT dan BevFusion pada setiap set imej yang dijana, dan kemudian bandingkan keputusan yang diramalkan dengan keputusan sebenar, termasuk purata persimpangan di atas skor U (mIoU) bagi kawasan boleh pandu dan NDS bagi semua kelas objek Statistik ditunjukkan dalam Jadual 2. Keputusan eksperimen menunjukkan bahawa penunjuk persepsi set penilaian data sintetik adalah sangat hampir dengan set penilaian sebenar, yang mencerminkan ketekalan tinggi hasil yang dijana dan nilai sebenar 3D dan kesetiaan tinggi kualiti imej.
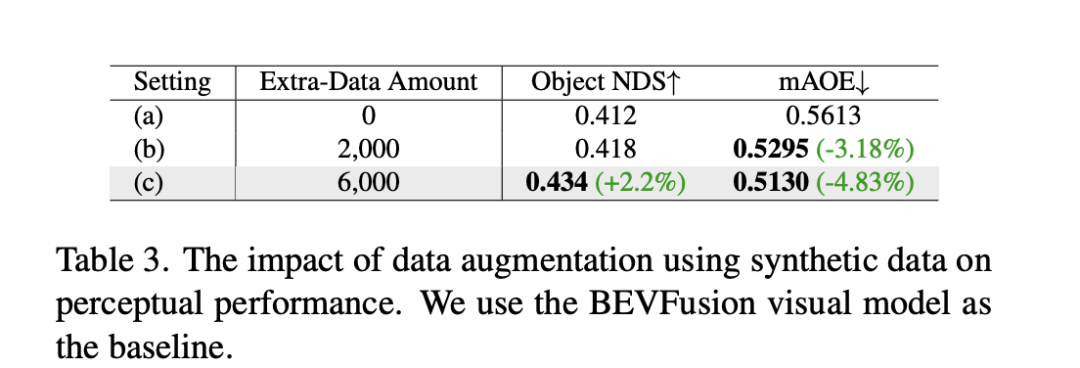
Selain daripada eksperimen di atas, DrivingDiffusion menjalankan eksperimen untuk menambah latihan data sintetik untuk menangani masalah utama yang diselesaikannya - meningkatkan prestasi tugasan hiliran pemanduan autonomi. Jadual 3 menunjukkan peningkatan prestasi yang dicapai oleh penambahan data sintetik dalam tugas persepsi BEV. Dalam data latihan asal, terdapat masalah dengan pengagihan ekor panjang, terutamanya untuk sasaran kecil, kenderaan jarak dekat dan sudut orientasi kenderaan. DrivingDiffusion memfokuskan pada penjanaan data tambahan untuk kelas ini dengan sampel terhad untuk menyelesaikan masalah ini. Selepas menambah 2000 bingkai data yang tertumpu pada penambahbaikan pengagihan sudut orientasi halangan, NDS bertambah baik sedikit, manakala mAOE turun dengan ketara daripada 0.5613 kepada 0.5295. Selepas menggunakan 6000 bingkai data sintetik yang lebih komprehensif dan tertumpu pada adegan yang jarang berlaku untuk membantu latihan, peningkatan ketara boleh diperhatikan pada set pengesahan nuScenes: NDS meningkat daripada 0.412 kepada 0.434, dan mAOE menurun daripada 0.5613 kepada 0.5130. Ini menunjukkan peningkatan ketara yang boleh dibawa oleh penambahan data data sintetik kepada tugas persepsi. Pengguna boleh membuat statistik mengenai pengedaran pelbagai dimensi dalam data berdasarkan keperluan sebenar, dan kemudian menambahnya dengan data sintetik yang disasarkan.
Kepentingan dan kerja masa depan DrivingDiffusion
DrivingDiffusion pada masa yang sama merealisasikan keupayaan untuk menjana video berbilang tontonan adegan pemanduan autonomi dan meramalkan masa depan, yang sangat penting untuk tugas pemanduan autonomi. Antaranya, reka letak dan parameter semuanya dibina secara buatan dan penukaran antara 3D-2D adalah melalui unjuran dan bukannya bergantung pada parameter model yang boleh dipelajari Ini menghapuskan ralat geometri dalam proses mendapatkan data sebelumnya dan mempunyai nilai praktikal yang kukuh. Pada masa yang sama, DrivingDiffuison sangat berskala dan menyokong susun atur kandungan pemandangan baharu serta pengawal tambahan Ia juga boleh meningkatkan kualiti penjanaan tanpa kehilangan melalui teknologi pemasukan bingkai video dan resolusi super.
Dalam simulasi pemanduan autonomi, semakin banyak percubaan di Nerf. Walau bagaimanapun, dalam tugas penjanaan paparan jalan, pemisahan kandungan dinamik dan statik, pembinaan semula blok berskala besar, kawalan penampilan decoupling cuaca dan dimensi lain, dan lain-lain, membawa sejumlah besar kerja Di samping itu, Nerf sering perlu dijalankan dalam julat adegan tertentu Hanya selepas latihan ia boleh menyokong tugasan sintesis perspektif baharu dalam simulasi seterusnya. DrivingDiffusion secara semula jadi mengandungi sejumlah pengetahuan am sebelum ini, termasuk sambungan teks visual, pemahaman konsep kandungan visual, dll. Ia boleh mencipta pemandangan mengikut keperluan dengan cepat hanya dengan membina reka letak. Walau bagaimanapun, seperti yang dinyatakan di atas, keseluruhan proses adalah agak kompleks, dan penjanaan video panjang memerlukan penalaan halus dan pengembangan model pasca pemprosesan. DrivingDiffusion akan terus meneroka pemampatan dimensi perspektif dan dimensi masa, serta menggabungkan Nerf untuk penjanaan dan penukaran perspektif baharu, serta terus meningkatkan kualiti penjanaan dan kebolehskalaan.
Atas ialah kandungan terperinci Model dunia penjanaan video adegan pemanduan berbilang paparan autonomi |. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undress AI Tool
Gambar buka pakaian secara percuma

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)



 Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Ditulis di atas & pemahaman peribadi pengarang Gaussiansplatting tiga dimensi (3DGS) ialah teknologi transformatif yang telah muncul dalam bidang medan sinaran eksplisit dan grafik komputer dalam beberapa tahun kebelakangan ini. Kaedah inovatif ini dicirikan oleh penggunaan berjuta-juta Gaussians 3D, yang sangat berbeza daripada kaedah medan sinaran saraf (NeRF), yang terutamanya menggunakan model berasaskan koordinat tersirat untuk memetakan koordinat spatial kepada nilai piksel. Dengan perwakilan adegan yang eksplisit dan algoritma pemaparan yang boleh dibezakan, 3DGS bukan sahaja menjamin keupayaan pemaparan masa nyata, tetapi juga memperkenalkan tahap kawalan dan pengeditan adegan yang tidak pernah berlaku sebelum ini. Ini meletakkan 3DGS sebagai penukar permainan yang berpotensi untuk pembinaan semula dan perwakilan 3D generasi akan datang. Untuk tujuan ini, kami menyediakan gambaran keseluruhan sistematik tentang perkembangan dan kebimbangan terkini dalam bidang 3DGS buat kali pertama.
 Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Semalam semasa temu bual, saya telah ditanya sama ada saya telah membuat sebarang soalan berkaitan ekor panjang, jadi saya fikir saya akan memberikan ringkasan ringkas. Masalah ekor panjang pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi, iaitu, kemungkinan senario dengan kebarangkalian yang rendah untuk berlaku. Masalah ekor panjang yang dirasakan adalah salah satu sebab utama yang kini mengehadkan domain reka bentuk pengendalian kenderaan autonomi pintar satu kenderaan. Seni bina asas dan kebanyakan isu teknikal pemanduan autonomi telah diselesaikan, dan baki 5% masalah ekor panjang secara beransur-ansur menjadi kunci untuk menyekat pembangunan pemanduan autonomi. Masalah ini termasuk pelbagai senario yang berpecah-belah, situasi yang melampau dan tingkah laku manusia yang tidak dapat diramalkan. "Ekor panjang" senario tepi dalam pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi (AVs) kes Edge adalah senario yang mungkin dengan kebarangkalian yang rendah untuk berlaku. kejadian yang jarang berlaku ini
 DualBEV: mengatasi BEVFormer dan BEVDet4D dengan ketara, buka buku!
Mar 21, 2024 pm 05:21 PM
DualBEV: mengatasi BEVFormer dan BEVDet4D dengan ketara, buka buku!
Mar 21, 2024 pm 05:21 PM
Kertas kerja ini meneroka masalah mengesan objek dengan tepat dari sudut pandangan yang berbeza (seperti perspektif dan pandangan mata burung) dalam pemanduan autonomi, terutamanya cara mengubah ciri dari perspektif (PV) kepada ruang pandangan mata burung (BEV) dengan berkesan dilaksanakan melalui modul Transformasi Visual (VT). Kaedah sedia ada secara amnya dibahagikan kepada dua strategi: penukaran 2D kepada 3D dan 3D kepada 2D. Kaedah 2D-ke-3D meningkatkan ciri 2D yang padat dengan meramalkan kebarangkalian kedalaman, tetapi ketidakpastian yang wujud dalam ramalan kedalaman, terutamanya di kawasan yang jauh, mungkin menimbulkan ketidaktepatan. Manakala kaedah 3D ke 2D biasanya menggunakan pertanyaan 3D untuk mencuba ciri 2D dan mempelajari berat perhatian bagi kesesuaian antara ciri 3D dan 2D melalui Transformer, yang meningkatkan masa pengiraan dan penggunaan.
 SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
Tajuk asal: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper pautan: https://arxiv.org/pdf/2402.02519.pdf Pautan kod: https://github.com/HKUST-Aerial-Robotics/SIMPL Unit pengarang: Universiti Sains Hong Kong dan Teknologi Idea Kertas DJI: Kertas kerja ini mencadangkan garis dasar ramalan pergerakan (SIMPL) yang mudah dan cekap untuk kenderaan autonomi. Berbanding dengan agen-sen tradisional
 Kertas Stable Diffusion 3 akhirnya telah dikeluarkan, dan butiran seni bina didedahkan Adakah ia akan membantu untuk menghasilkan semula Sora?
Mar 06, 2024 pm 05:34 PM
Kertas Stable Diffusion 3 akhirnya telah dikeluarkan, dan butiran seni bina didedahkan Adakah ia akan membantu untuk menghasilkan semula Sora?
Mar 06, 2024 pm 05:34 PM
Kertas StableDiffusion3 akhirnya di sini! Model ini dikeluarkan dua minggu lalu dan menggunakan seni bina DiT (DiffusionTransformer) yang sama seperti Sora. Ia menimbulkan kekecohan apabila ia dikeluarkan. Berbanding dengan versi sebelumnya, kualiti imej yang dijana oleh StableDiffusion3 telah dipertingkatkan dengan ketara Ia kini menyokong gesaan berbilang tema, dan kesan penulisan teks juga telah dipertingkatkan, dan aksara bercelaru tidak lagi muncul. StabilityAI menegaskan bahawa StableDiffusion3 ialah satu siri model dengan saiz parameter antara 800M hingga 8B. Julat parameter ini bermakna model boleh dijalankan terus pada banyak peranti mudah alih, dengan ketara mengurangkan penggunaan AI
 Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
0. Ditulis di hadapan&& Pemahaman peribadi bahawa sistem pemanduan autonomi bergantung pada persepsi lanjutan, membuat keputusan dan teknologi kawalan, dengan menggunakan pelbagai penderia (seperti kamera, lidar, radar, dll.) untuk melihat persekitaran sekeliling dan menggunakan algoritma dan model untuk analisis masa nyata dan membuat keputusan. Ini membolehkan kenderaan mengenali papan tanda jalan, mengesan dan menjejaki kenderaan lain, meramalkan tingkah laku pejalan kaki, dsb., dengan itu selamat beroperasi dan menyesuaikan diri dengan persekitaran trafik yang kompleks. Teknologi ini kini menarik perhatian meluas dan dianggap sebagai kawasan pembangunan penting dalam pengangkutan masa depan satu. Tetapi apa yang menyukarkan pemanduan autonomi ialah memikirkan cara membuat kereta itu memahami perkara yang berlaku di sekelilingnya. Ini memerlukan algoritma pengesanan objek tiga dimensi dalam sistem pemanduan autonomi boleh melihat dan menerangkan dengan tepat objek dalam persekitaran sekeliling, termasuk lokasinya,
 Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Ramalan trajektori memainkan peranan penting dalam pemanduan autonomi Ramalan trajektori pemanduan autonomi merujuk kepada meramalkan trajektori pemanduan masa hadapan kenderaan dengan menganalisis pelbagai data semasa proses pemanduan kenderaan. Sebagai modul teras pemanduan autonomi, kualiti ramalan trajektori adalah penting untuk kawalan perancangan hiliran. Tugas ramalan trajektori mempunyai timbunan teknologi yang kaya dan memerlukan kebiasaan dengan persepsi dinamik/statik pemanduan autonomi, peta ketepatan tinggi, garisan lorong, kemahiran seni bina rangkaian saraf (CNN&GNN&Transformer), dll. Sangat sukar untuk bermula! Ramai peminat berharap untuk memulakan ramalan trajektori secepat mungkin dan mengelakkan perangkap Hari ini saya akan mengambil kira beberapa masalah biasa dan kaedah pembelajaran pengenalan untuk ramalan trajektori! Pengetahuan berkaitan pengenalan 1. Adakah kertas pratonton teratur? A: Tengok survey dulu, hlm
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
