
 Java
javaDidacticiel
Java Cache Data Perte: Pourquoi les données ne peuvent-elles pas être récupérées à partir du cache?
Java
javaDidacticiel
Java Cache Data Perte: Pourquoi les données ne peuvent-elles pas être récupérées à partir du cache?
Java Cache Data Perte: Pourquoi les données ne peuvent-elles pas être récupérées à partir du cache?
Apr 19, 2025 pm 02:57 PM

Problème de perte de données Java Cached: diagnostic et solutions
Dans les applications Java, la mise en cache de la mémoire est une stratégie clé pour améliorer les performances. Cependant, la perte de données mise en cache est un problème courant. Cet article effectuera une analyse de cas pour explorer les causes profondes des données en cache Java en profondeur et fournir des solutions d'optimisation efficaces.
Contexte du cas:
Un projet utilise une classe appelée scenarioBuffer pour mettre en cache environ 160 000 données asset dans un hashmap. scenarioBuffer utilise l'annotation @Component et fournit une méthode statique getBAsset pour l'acquisition de données. Lorsque l'application démarre, scenarioBuffer initialise le cache via ApplicationRunner . Cependant, pendant la course, la méthode getBAsset renvoie fréquemment des valeurs nulles. Ce qui est encore plus déroutant, c'est que la mémoire du serveur est dans un besoin urgent (seulement 100 Mo de mémoire disponible sont laissés, le cache prend 3 Go et la mémoire totale est de 8 Go). Après avoir redémarré le serveur et effacé le cache, le problème est temporairement résolu.
Analyse de la cause profonde du problème:
Malgré l'allocation d'environ 3 Go de mémoire pour Tomcat, la mémoire du serveur insuffisante reste le principal problème. Lorsque la mémoire est insuffisante, le JVM déclenchera la collecte des ordures et même la force de l'arrêt pour libérer la mémoire, ce qui entra?nera une effacement des données mises en cache.
Flaws de code:
Le code d'origine a les problèmes suivants:
- Méthodes statiques et singletons:
scenarioBufferutilise la méthode statiquegetBAssetet la variable statiqueassetBuffer, ainsi quegetInstance(). Dans les haricots gérés par le printemps, ce n'est complètement pas nécessaire. Les conteneurs de ressort eux-mêmes gérent les singletons de haricots, les méthodes et variables statiques augmentent la complexité du code et sont difficiles à tester unitaires. - L'injection de dépendance est manquante: l'obtention
scenarioBuffern'utilise pas l'injection de dépendance de Spring, mais utilisegetInstance(), ce qui réduit la maintenabilité et la testabilité du code. - Méthode d'initialisation: Bien qu'il soit possible d'initialiser le cache à l'aide
ApplicationRunner, l'interface@PostConstructAnnotation ouInitializingBeanest plus claire et plus facile à comprendre.
Solution d'optimisation:
Il est recommandé d'utiliser l'injection de dépendance de Spring et le code d'optimisation de l'annotation @PostConstruct :
Classe scenarioBuffer modifiés:
@Composant
classe publique ScénarioBuffer implémente iActionListener {
@Autowired
Service d'actions privés de l'IASSETSETSE;
carte privée <string list> > AssetBuffer = new HashMap ();
@PostConstruct
public void init () {
Liste<asset> AssetList = AssetsService.List ();
AssetBuffer.put ("Key", AssetList); // Ici, vous devez modifier la clé en fonction de la situation réelle
}
liste publique<asset> getBasset (String GroupID) {
return AssetBuffer.get (GroupID);
}
}</asset></asset></string>
Dans la classe qui doit utiliser le cache, injectez scenarioBuffer via @Autowired :
@Service
classe publique xxxService {
@Autowired
Scénario-scénario-scénario-option;
public void xxx () {
Liste<asset> Asset = scearioBuffer.getBasset ("xxx"); // Ici, vous devez modifier le groupe GroupID en fonction de la situation réelle
// ...
}
}</asset>
Ces modifications rendent le code plus concis, facile à entretenir et à tester, et évitent les problèmes causés par des méthodes et variables statiques.
De plus, vous devez faire attention à l'utilisation de la mémoire du serveur. Si la mémoire est souvent insuffisante, envisagez d'augmenter la mémoire du serveur ou d'optimiser les programmes pour réduire l'utilisation de la mémoire. Bien que Redis ne soit pas pris en compte pour le moment dans le cas, à long terme, l'utilisation de caches distribuées telles que Redis peut atténuer efficacement la pression de la mémoire et améliorer les performances.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
échangez les visages dans n'importe quelle vidéo sans effort grace à notre outil d'échange de visage AI entièrement gratuit?!

Article chaud
Outils chauds

Bloc-notes++7.3.1
éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment étendre la capacité du disque C s'il est trop petit? 5 solutions pour une expansion du disque C à petite capacité
May 22, 2025 pm 09:15 PM
Comment étendre la capacité du disque C s'il est trop petit? 5 solutions pour une expansion du disque C à petite capacité
May 22, 2025 pm 09:15 PM
C le lecteur peut augmenter la capacité de cinq manières: 1. Utilisez des outils de gestion du disque Windows pour étendre le volume, mais il doit y avoir un espace non alloué; 2. Utilisez des logiciels tiers tels que EaseUS ou Aomei pour ajuster la taille de la partition; 3. Utilisez des outils de ligne de commande DISKPART pour étendre le lecteur C, adapté aux utilisateurs qui connaissent la ligne de commande; 4. Répartition et format le disque dur, mais cela entra?nera la perte de données et les données doivent être sauvegardées; 5. Utilisez des dispositifs de stockage externes comme extension du lecteur C, des dossiers de transfert via des liens symboliques ou une modification du registre.
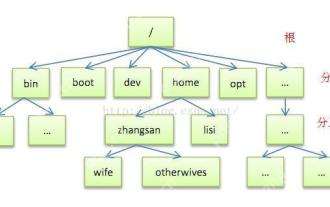 Introduction détaillée à chaque répertoire de Linux et de chaque répertoire (réimprimé)
May 22, 2025 pm 07:54 PM
Introduction détaillée à chaque répertoire de Linux et de chaque répertoire (réimprimé)
May 22, 2025 pm 07:54 PM
[DESCRIPTION DU RéPERTOIRE COMMUN] DIRECTEUR / BIN STORES Fichiers exécutables (LS, CAT, MKDIR, etc.), et les commandes communes sont généralement là. / ETC stocke la gestion du système et les fichiers de configuration / Home Stores tous les fichiers utilisateur. Le répertoire racine du répertoire personnel de l'utilisateur est la base du répertoire domestique de l'utilisateur. Par exemple, le répertoire domestique de l'utilisateur d'utilisateur est / home / utilisateur. Vous pouvez utiliser ~ User pour représenter / USR pour stocker les applications système. Le répertoire plus important / USR / répertoire d'installation du logiciel d'administrateur système local local (installer les applications au niveau du système). Il s'agit du plus grand répertoire, et presque toutes les applications et fichiers à utiliser sont dans ce répertoire. / USR / X11R6 Répertoire pour stocker x fenêtre / usr / bin beaucoup
 Comment développer une application Web Python complète?
May 23, 2025 pm 10:39 PM
Comment développer une application Web Python complète?
May 23, 2025 pm 10:39 PM
Pour développer une application Web Python complète, suivez ces étapes: 1. Choisissez le cadre approprié, tel que Django ou Flask. 2. Intégrez les bases de données et utilisez des orms tels que Sqlalchemy. 3. Concevez le frontal et utilisez Vue ou React. 4. Effectuez le test, utilisez Pytest ou Unittest. 5. Déployer les applications, utiliser Docker et des plates-formes telles que Heroku ou AWS. Grace à ces étapes, des applications Web puissantes et efficaces peuvent être construites.
 Comment mettre à jour Debian Tomcat
May 28, 2025 pm 04:54 PM
Comment mettre à jour Debian Tomcat
May 28, 2025 pm 04:54 PM
La mise à jour de la version Tomcat dans le système Debian comprend généralement le processus suivant: Avant d'effectuer l'opération de mise à jour, assurez-vous de faire une sauvegarde complète de l'environnement Tomcat existant. Cela couvre le dossier / opt / tomcat et ses documents de configuration connexes, tels que server.xml, context.xml et web.xml. La tache de sauvegarde peut être terminée via la commande suivante: sudocp-r / opt / tomcat / opt / tomcat_backup Obtenez la nouvelle version Tomcat allez sur le site officiel d'apachetomcat pour télécharger la dernière version. Selon votre système Debian
 Comment créer une base de données SQLite dans Python?
May 23, 2025 pm 10:36 PM
Comment créer une base de données SQLite dans Python?
May 23, 2025 pm 10:36 PM
Créez une base de données SQLite dans Python à l'aide du module SQLite3. Les étapes sont les suivantes: 1. Connectez-vous à la base de données, 2. Créez un objet de curseur, 3. Créez un tableau, 4. Soumettre une transaction, 5. Fermez la connexion. Ce n'est pas seulement simple et facile à faire, mais comprend également des optimisations et des considérations telles que l'utilisation d'index et d'opérations par lots pour améliorer les performances.
 Java Chinese Bragbled Problem, Cause and Corred for Brizze Code
May 28, 2025 pm 05:36 PM
Java Chinese Bragbled Problem, Cause and Corred for Brizze Code
May 28, 2025 pm 05:36 PM
Le problème brouillé en chinois java est principalement causé par un codage de caractère incohérent. La méthode de réparation comprend la cohérence du codage du système et la gestion correcte de la conversion de codage. 1. Utilisez UTF-8 Encodage uniformément des fichiers aux bases de données et programmes. 2. Spécifiez clairement le codage lors de la lecture du fichier, tel que l'utilisation de BufferedReader et InputStreamReader. 3. Définissez le jeu de caractères de la base de données, tel que MySQL à l'aide de l'instruction AlterDatabase. 4. Définissez le type de contenu sur Text / HTML; charset = UTF-8 dans les demandes et réponses HTTP. 5. Faites attention à l'encodage des compétences de cohérence, de conversion et de débogage pour assurer le traitement correct des données.
 BlockDag (BDAG): Les 7 jours restants, la pile restante avant de se rendre en ligne
May 26, 2025 pm 11:51 PM
BlockDag (BDAG): Les 7 jours restants, la pile restante avant de se rendre en ligne
May 26, 2025 pm 11:51 PM
Pour une bonne raison, BlockDag se concentre sur les intérêts des acheteurs. Blockdag a recueilli 265 millions de dollars étonnants en 28 lots de ses préventes à l'approche de 2025, les investisseurs accumulent régulièrement des projets crypto-potentiels. Qu'il s'agisse de pièces de pré-vente à faible co?t qui offrent beaucoup d'avantages ou d'un réseau de bleu qui se prépare aux mises à niveau critiques, ce moment fournit un point d'entrée unique. De l'évolutivité rapide à l'architecture modulaire flexible modulaire, ces quatre noms exceptionnels ont attiré l'attention sur tout le marché. Les analystes et les premiers adoptants surveillent attentivement, les appelant les meilleures pièces de monnaie cryptographiques pour acheter des gains à court terme et une valeur à long terme maintenant. 1. Blockdag (BDAG): 7 jours à faire
 Comment limiter les ressources des utilisateurs dans Linux? Comment configurer Ulimit?
May 29, 2025 pm 11:09 PM
Comment limiter les ressources des utilisateurs dans Linux? Comment configurer Ulimit?
May 29, 2025 pm 11:09 PM
Linux System restreint les ressources utilisateur via la commande UliMIT pour éviter une utilisation excessive des ressources. 1.Ulimit est une commande shell intégrée qui peut limiter le nombre de descripteurs de fichiers (-n), la taille de la mémoire (-v), le nombre de threads (-u), etc., qui sont divisés en limite douce (valeur effective actuelle) et limite dure (limite supérieure maximale). 2. Utilisez directement la commande ulimit pour une modification temporaire, telle que Ulimit-N2048, mais elle n'est valable que pour la session en cours. 3. Pour un effet permanent, vous devez modifier /etc/security/limits.conf et les fichiers de configuration PAM, et ajouter SessionRequiredPam_limits.so. 4. Le service SystemD doit définir Lim dans le fichier unitaire
