
 développement back-end
tutoriel php
Comment configurer efficacement OPCACH pour améliorer les performances de l'environnement de production?
développement back-end
tutoriel php
Comment configurer efficacement OPCACH pour améliorer les performances de l'environnement de production?
Comment configurer efficacement OPCACH pour améliorer les performances de l'environnement de production?
Apr 01, 2025 am 10:42 AM

PHP 7.3 OPCACHE Performance Tuning: Environnement de production Meilleures pratiques
Dans les environnements de production PHP 7.3, l'optimisation de la configuration d'Opcache pour les performances est cruciale. Cet article vous guidera comment configurer l'opcache, maximiser l'efficacité du cache, réduire la charge du serveur et améliorer la vitesse de réponse de l'application.
Explication détaillée des paramètres de configuration centrale:
Tout d'abord, assurez-vous que Opcache est activé:
-
opcache.enable=1: Activer le commutateur OPCACHE, doit être défini sur 1.
Ensuite, ajustez l'allocation de la mémoire OPCACHE:
-
opcache.memory_consumption=512: Opcache peut utiliser la taille de la mémoire (MB). 512 Mo est une valeur commune, mais elle doit être ajustée en fonction de l'échelle d'application et du volume de code. Trop petit réduit le taux de réussite du cache et la mémoire de déchets trop gros.
Optimiser la mise en cache des cha?nes:
-
opcache.interned_strings_buffer=64: taille de tampon de cha?ne interne OPCACH (MB). La configuration raisonnable réduit la duplication des cha?nes et améliore les performances.
Contr?lez le nombre de fichiers mis en cache:
-
opcache.max_accelerated_files=4000: Opcache cache le nombre maximum de fichiers PHP. Ajusté en fonction de la taille du projet, trop petites provoquent une défaillance fréquente du cache et une augmentation excessive d'augmentation de la mémoire.
Définir la fréquence de récification des fichiers:
-
opcache.revalidate_freq=1000: OPCACHE vérifie la fréquence de modification des fichiers (secondes). 1000 secondes (environ 16 minutes) est une valeur commune, équilibrant les performances et la mise à jour du code. La vérification excessive augmente la charge du processeur.
Activer le mode CLI OPCACHE:
-
opcache.enable_cli=1: Si vous avez besoin d'utiliser Opcache sur la ligne de commande, définissez-vous sur 1.
Configuration facile pour une amélioration rapide des performances:
Dans de nombreux cas, il vous suffit de configurer les deux éléments suivants pour améliorer considérablement les performances:
-
opcache.enable=1: Activer Opcache. -
opcache.revalidate_freq=1000: Définit la fréquence de ré-révification.
La configuration des autres paramètres doit être ajustée et testée en fonction des conditions réelles de l'application (mémoire du serveur, taille du code, fréquence de mise à jour, etc.). La surveillance et les tests continus sont essentiels pour optimiser la configuration.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
échangez les visages dans n'importe quelle vidéo sans effort grace à notre outil d'échange de visage AI entièrement gratuit?!

Article chaud
Outils chauds

Bloc-notes++7.3.1
éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Que faire si votre téléphone Huawei a une mémoire insuffisante (Méthodes pratiques pour résoudre le problème de mémoire insuffisante)
Apr 29, 2024 pm 06:34 PM
Que faire si votre téléphone Huawei a une mémoire insuffisante (Méthodes pratiques pour résoudre le problème de mémoire insuffisante)
Apr 29, 2024 pm 06:34 PM
Le manque de mémoire sur les téléphones mobiles Huawei est devenu un problème courant auquel sont confrontés de nombreux utilisateurs, avec l'augmentation des applications mobiles et des fichiers multimédias. Pour aider les utilisateurs à utiliser pleinement l'espace de stockage de leurs téléphones mobiles, cet article présentera quelques méthodes pratiques pour résoudre le problème de mémoire insuffisante sur les téléphones mobiles Huawei. 1. Nettoyer le cache?: enregistrements d'historique et données invalides pour libérer de l'espace mémoire et effacer les fichiers temporaires générés par les applications. Recherchez ??Stockage?? dans les paramètres de votre téléphone Huawei, cliquez sur ??Vider le cache?? et sélectionnez le bouton ??Vider le cache?? pour supprimer les fichiers de cache de l'application. 2. Désinstallez les applications rarement utilisées : pour libérer de l'espace mémoire, supprimez certaines applications rarement utilisées. Faites glisser vers le haut de l'écran du téléphone, appuyez longuement sur l'ic?ne ??Désinstaller?? de l'application que vous souhaitez supprimer, puis cliquez sur le bouton de confirmation pour terminer la désinstallation. 3.Application mobile pour
 Pour seulement 250$, le directeur technique de Hugging Face vous apprend étape par étape comment peaufiner Llama 3
May 06, 2024 pm 03:52 PM
Pour seulement 250$, le directeur technique de Hugging Face vous apprend étape par étape comment peaufiner Llama 3
May 06, 2024 pm 03:52 PM
Les grands modèles de langage open source familiers tels que Llama3 lancé par Meta, les modèles Mistral et Mixtral lancés par MistralAI et Jamba lancé par AI21 Lab sont devenus des concurrents d'OpenAI. Dans la plupart des cas, les utilisateurs doivent affiner ces modèles open source en fonction de leurs propres données pour libérer pleinement le potentiel du modèle. Il n'est pas difficile d'affiner un grand modèle de langage (comme Mistral) par rapport à un petit en utilisant Q-Learning sur un seul GPU, mais le réglage efficace d'un grand modèle comme Llama370b ou Mixtral est resté un défi jusqu'à présent. . C'est pourquoi Philipp Sch, directeur technique de HuggingFace
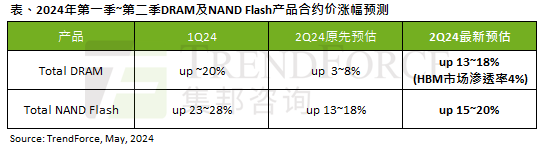 L'impact de la vague de l'IA est évident. TrendForce a révisé à la hausse ses prévisions d'augmentation des prix des contrats de mémoire DRAM et de mémoire flash NAND ce trimestre.
May 07, 2024 pm 09:58 PM
L'impact de la vague de l'IA est évident. TrendForce a révisé à la hausse ses prévisions d'augmentation des prix des contrats de mémoire DRAM et de mémoire flash NAND ce trimestre.
May 07, 2024 pm 09:58 PM
Selon un rapport d'enquête TrendForce, la vague de l'IA a un impact significatif sur les marchés de la mémoire DRAM et de la mémoire flash NAND. Dans l'actualité de ce site du 7 mai, TrendForce a déclaré aujourd'hui dans son dernier rapport de recherche que l'agence avait augmenté les augmentations de prix contractuels pour deux types de produits de stockage ce trimestre. Plus précisément, TrendForce avait initialement estimé que le prix du contrat de mémoire DRAM au deuxième trimestre 2024 augmenterait de 3 à 8 %, et l'estime désormais à 13 à 18 % en termes de mémoire flash NAND, l'estimation initiale augmentera de 13 à 8 % ; 18 %, et la nouvelle estimation est de 15 % ~ 20 %, seul eMMC/UFS a une augmentation inférieure de 10 %. ▲Source de l'image TrendForce TrendForce a déclaré que l'agence prévoyait initialement de continuer à
 Comment affiner la profondeur localement
Feb 19, 2025 pm 05:21 PM
Comment affiner la profondeur localement
Feb 19, 2025 pm 05:21 PM
Le réglage fin local des modèles de classe Deepseek est confronté au défi des ressources informatiques insuffisantes et de l'expertise. Pour relever ces défis, les stratégies suivantes peuvent être adoptées: quantification du modèle: convertir les paramètres du modèle en entiers à faible précision, réduisant l'empreinte de la mémoire. Utilisez des modèles plus petits: sélectionnez un modèle pré-entra?né avec des paramètres plus petits pour un réglage fin local plus facile. Sélection des données et prétraitement: sélectionnez des données de haute qualité et effectuez un prétraitement approprié pour éviter une mauvaise qualité des données affectant l'efficacité du modèle. Formation par lots: pour les grands ensembles de données, chargez les données en lots de formation pour éviter le débordement de la mémoire. Accélération avec GPU: Utilisez des cartes graphiques indépendantes pour accélérer le processus de formation et raccourcir le temps de formation.
 Que faire si le navigateur Edge prend trop de mémoire Que faire si le navigateur Edge prend trop de mémoire
May 09, 2024 am 11:10 AM
Que faire si le navigateur Edge prend trop de mémoire Que faire si le navigateur Edge prend trop de mémoire
May 09, 2024 am 11:10 AM
1. Tout d’abord, entrez dans le navigateur Edge et cliquez sur les trois points dans le coin supérieur droit. 2. Ensuite, sélectionnez [Extensions] dans la barre des taches. 3. Ensuite, fermez ou désinstallez les plug-ins dont vous n'avez pas besoin.
 Que les grands modèles ne soient plus des ? gros Mac ?. Il s'agit de la dernière revue du réglage efficace des paramètres des grands modèles.
Apr 28, 2024 pm 04:04 PM
Que les grands modèles ne soient plus des ? gros Mac ?. Il s'agit de la dernière revue du réglage efficace des paramètres des grands modèles.
Apr 28, 2024 pm 04:04 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a re?u plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission?: liyazhou@jiqizhixin.com?; zhaoyunfeng@jiqizhixin.com. Récemment, des modèles d’IA à grande échelle tels que les grands modèles de langage et les modèles de graphes vincentiens se sont développés rapidement. Dans cette situation, comment s'adapter à l'évolution rapide des besoins et adapter rapidement les grands modèles à diverses taches en aval est devenu un défi important. Limité par les ressources informatiques, micro traditionnel à paramètres complets
 Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravelelognent Model Retrieval: Faconttement l'obtention de données de base de données Eloquentorm fournit un moyen concis et facile à comprendre pour faire fonctionner la base de données. Cet article présentera en détail diverses techniques de recherche de modèles éloquentes pour vous aider à obtenir efficacement les données de la base de données. 1. Obtenez tous les enregistrements. Utilisez la méthode All () pour obtenir tous les enregistrements dans la table de base de données: usApp \ Modèles \ Post; $ poters = post :: all (); Cela rendra une collection. Vous pouvez accéder aux données à l'aide de Foreach Loop ou d'autres méthodes de collecte: ForEach ($ PostsAs $ POST) {echo $ post->
 Quels avertissements ou mises en garde doivent être inclus dans la documentation des fonctions Golang??
May 04, 2024 am 11:39 AM
Quels avertissements ou mises en garde doivent être inclus dans la documentation des fonctions Golang??
May 04, 2024 am 11:39 AM
La documentation de la fonction Go contient des avertissements et des mises en garde essentiels pour comprendre les problèmes potentiels et éviter les erreurs. Ceux-ci incluent : Avertissement de validation des paramètres : vérifiez la validité des paramètres. Considérations sur la sécurité de la concurrence?: indiquez la sécurité des threads d'une fonction. Considérations sur les performances?: mettez en évidence le co?t de calcul élevé ou l'empreinte mémoire d'une fonction. Annotation du type de retour?: décrit le type d'erreur renvoyé par la fonction. Remarque sur les dépendances?: répertorie les bibliothèques ou packages externes requis par la fonction. Avertissement de dépréciation?: indique qu'une fonction est obsolète et suggère une alternative.
