
 Technology peripherals
AI
Application of algorithms in the construction of 58 portrait platform
Technology peripherals
AI
Application of algorithms in the construction of 58 portrait platform
Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM

1. Background of the construction of the 58 portrait platform
First of all, I would like to share with you the background of the construction of the 58 portrait platform.
1. Traditional profiling platform
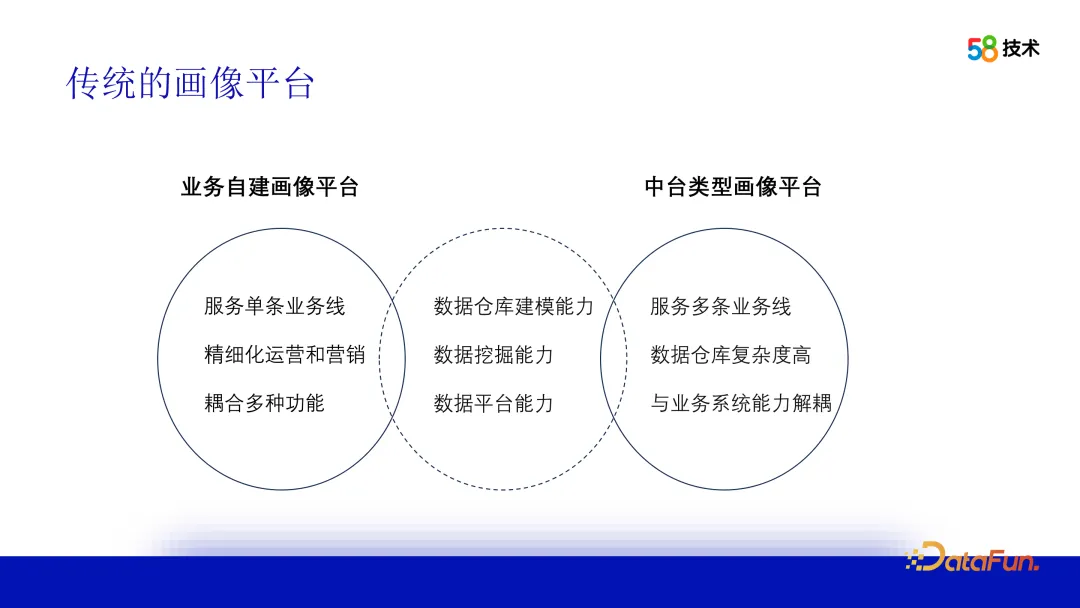
Traditional ideas are no longer enough, and building a user profiling platform relies on Data warehouse modeling capabilities integrate data from multiple business lines to build accurate user portraits; data mining is also required to understand user behavior, interests and needs, and provide algorithm-side capabilities; finally, data platform capabilities are required to efficiently store and query and share user profiling data and provide profiling services. The main difference between a self-built business profiling platform and a middle-office profiling platform is that the self-built profiling platform serves a single business line and can be customized on demand; the mid-office platform serves multiple business lines, has complex modeling, and provides more general capabilities.
2. 58 The background of China-Taiwan portrait construction

58 The construction of the user portrait platform mainly stems from the following factors A business requirement:
- Personalized recommendation: The business side needs to distribute content to thousands of people based on user portraits.
- Refined operation: Product operation requires the portrait platform to provide functions such as crowd insight and crowd selection to conduct more refined operational activities for different groups of people.
- User value growth: Extensive traffic growth has passed. How to use the portrait platform to increase the value of existing users is an urgent need.
3. Vientiane
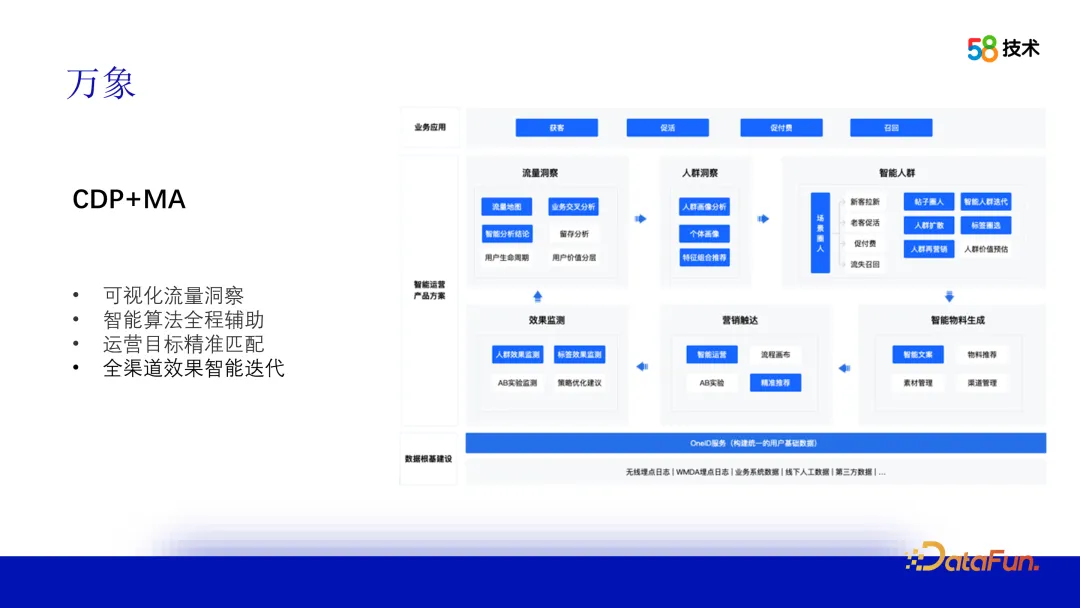
In order to solve the current business needs and external environment challenges, we proposed UA CDP MA is a set of user portrait platform solutions. Use the OneID service to build basic user portrait data, combine traffic and crowd insights, use algorithms to intelligently generate crowds, and match materials for precise marketing. At the same time, monitor the effect and recycle data to optimize the strategy and iterate the crowd. Provide intelligent growth solutions for business parties to achieve precise operations and business growth.
##2. The role of algorithm in the construction of 58 portrait platform

The construction of the algorithm side of the 58 user portrait platform mainly includes two aspects, one is the construction of the label system, and the other is the construction of the platform capabilities.
1. Construction of tag system
The Vientiane tag system includes multiple categories such as social attributes, geographical location, behavioral habits, preference attributes, and user stratification. , there are more than 1500 tags in total. We divide it into two types according to the production method:- Fact tags: Shucang students use statistics or rules to develop and produce through SQL, etc.
- Algorithm tags: The algorithm team processes and produces through data mining and other means.
2. Examples of algorithm tags
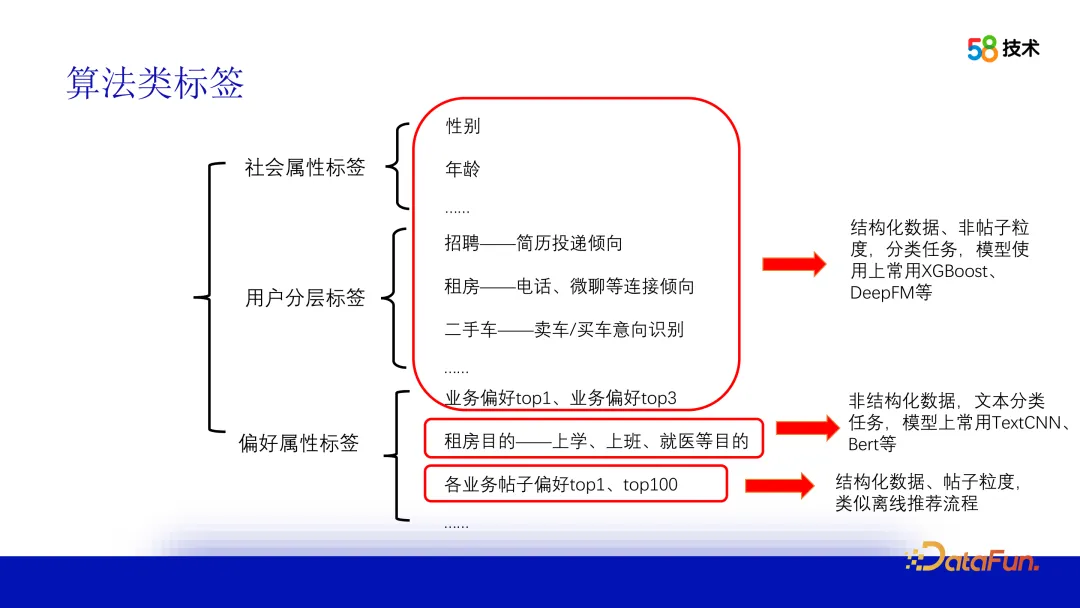
3. Take the content preference tag as an example to explain the tag process
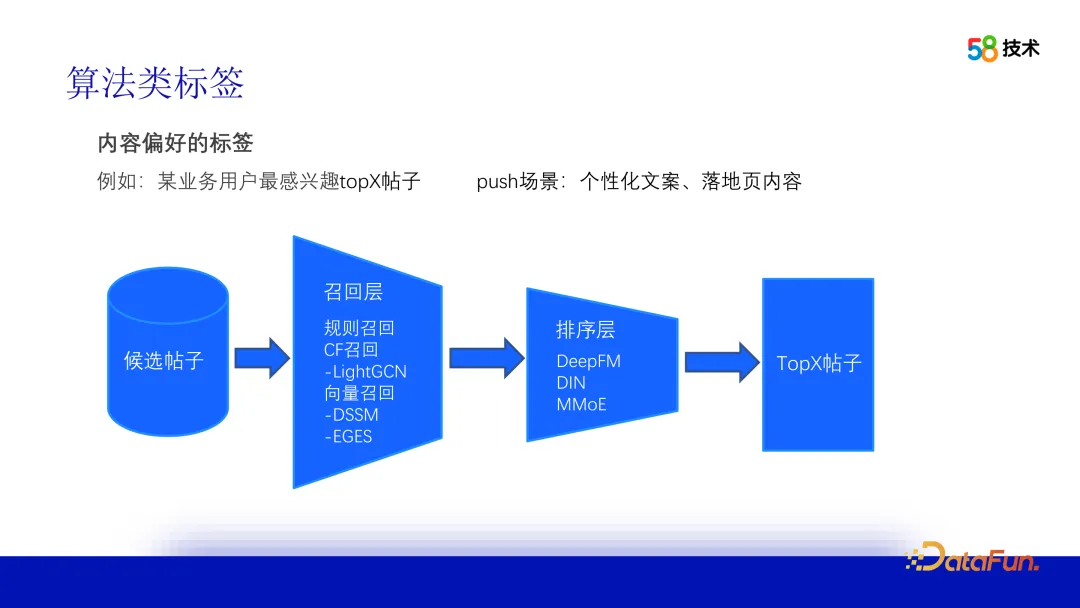
Take the content preference label as an example. To produce this label, an offline recommendation process needs to be established. Faced with millions or more posts, we first conduct preliminary screening through the recall stage, using popular, rule, collaborative filtering and other methods, such as the convolutional neural network (LightGCN) and the Twin Towers (DSSM) model in the figure. Then, based on the recalled posts, the Pointwise approach is used to sort through the CTR model. The final output is the Top N posts that users are most interested in. In practical applications, taking the push scenario as an example, key attributes can be extracted from the Top 1 posts to generate personalized copy. At the same time, the landing page can be the details page of the Top 1 post or the list page of the Top N posts.

When producing content preference tags, taking into account the regional and category characteristics of 58’s intra-city business, users usually only feel interested in posts from specific regions or categories in their recommendations. interest. Therefore, when vectorizing recall (such as using the EGES model), there may be a large number of off-site or non-category posts. To solve this problem, we represent the city information in hexadecimal, replace 0 with -1, and then splice this encoding directly into the previously generated vector. This can ensure that posts in the same city or for the same purpose are included in the similarity calculation. have the greatest similarity among them, thus improving the accuracy of recall and recommendation.
In the sorting stage, multi-modal information, including text content, is used to improve the accuracy of recommendations. For example, the post title, as a text feature, can be represented by embedding using pre-trained models such as BERT and M3E. However, this poses a challenge to computing resources due to the large number of posts. To solve this problem, we use Spark NLP, a natural language processing library based on Apache Spark Machine Learning. Although there is no Chinese BERT model in the native library, through some transformations, we successfully applied it to large-scale offline inference.
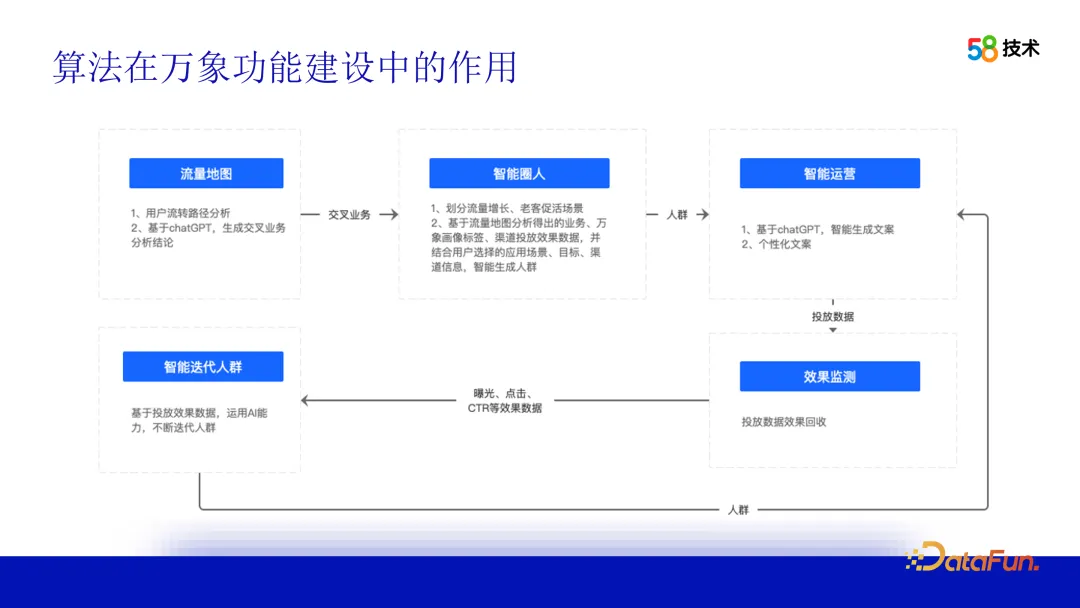
Algorithms also play a core role in the functional construction of the 58 city user portrait platform. Taking intelligent operation capabilities as an example, we use traffic maps to identify correlations between different businesses and provide operational suggestions or conclusions for business parties. Based on these suggestions, the business side can directly generate an operator crowd package through the intelligent circle function and connect it to the corresponding channels for delivery. The delivery effect can be monitored through the platform and iteratively optimized based on the effect data to continuously improve operational effects.
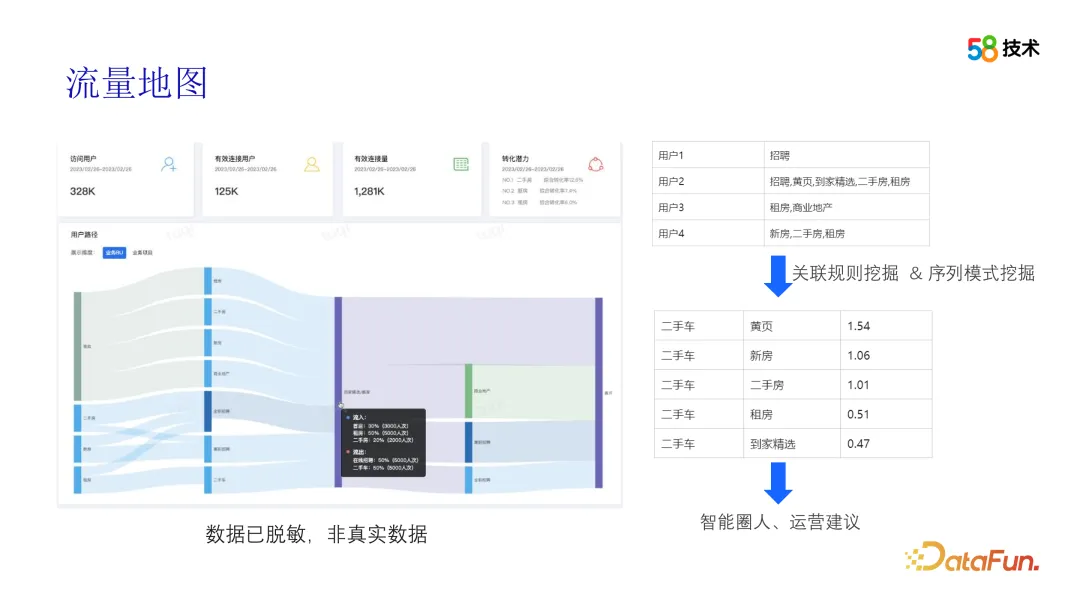
How does the algorithm work? Next, we will introduce it in several parts. The first is the traffic map. We use OLAP data mining and data visualization technology to conduct an in-depth analysis of 58APP users’ browsing behavior between different businesses. By analyzing and processing this data, users' flow paths between different businesses can be displayed, providing the operations team with an intuitive view of user behavior. In this process, algorithms can not only help us identify user behavior patterns, but also mine correlations between different businesses through correlation analysis and other technologies. These correlations provide us with valuable operational suggestions and support the operations team in cross-operations.
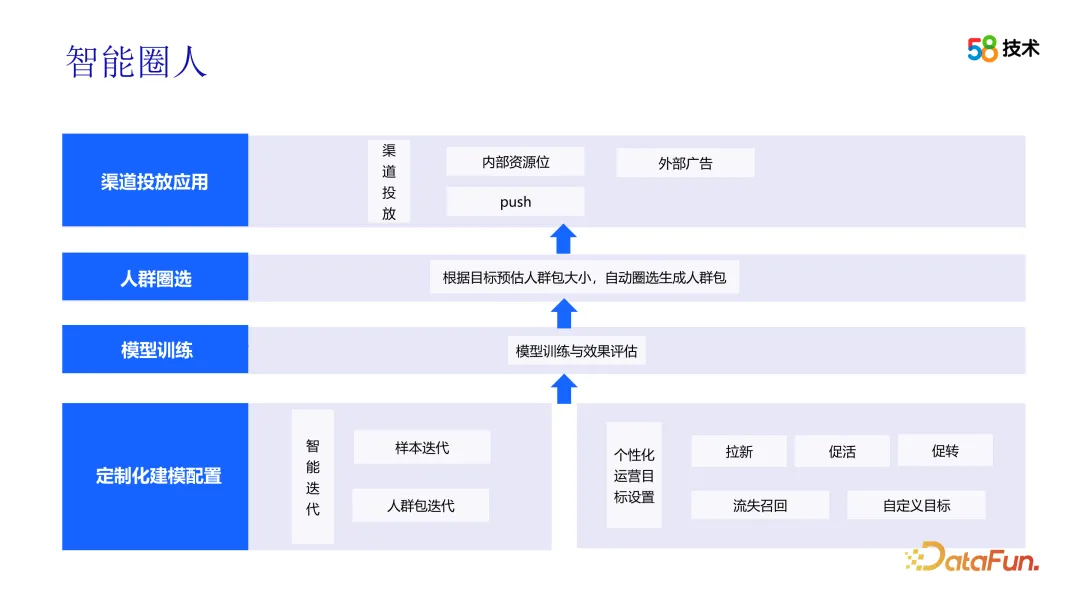
After receiving the operation suggestions, the operation team can select the target group through the intelligent circle function. In order to achieve this goal, the operations team needs to first configure personalized operational goals and clarify whether the goal is to attract new customers, promote activity, or promote conversions, etc. Next, you need to set the desired effect, including the size of the crowd package and the expected delivery effect. In addition, the operations team also needs to select suitable delivery channels to ensure that the target group can receive relevant operational activity information.
#The process of generating crowd packages is a black box for the operations team. To address this issue, we provide more explanations and descriptions of the algorithm principles and steps so that operations teams can better understand and apply the technology. At the same time, we provide more visual tools and interfaces to help the operation team intuitively view and analyze the characteristics and effects of crowd packets.
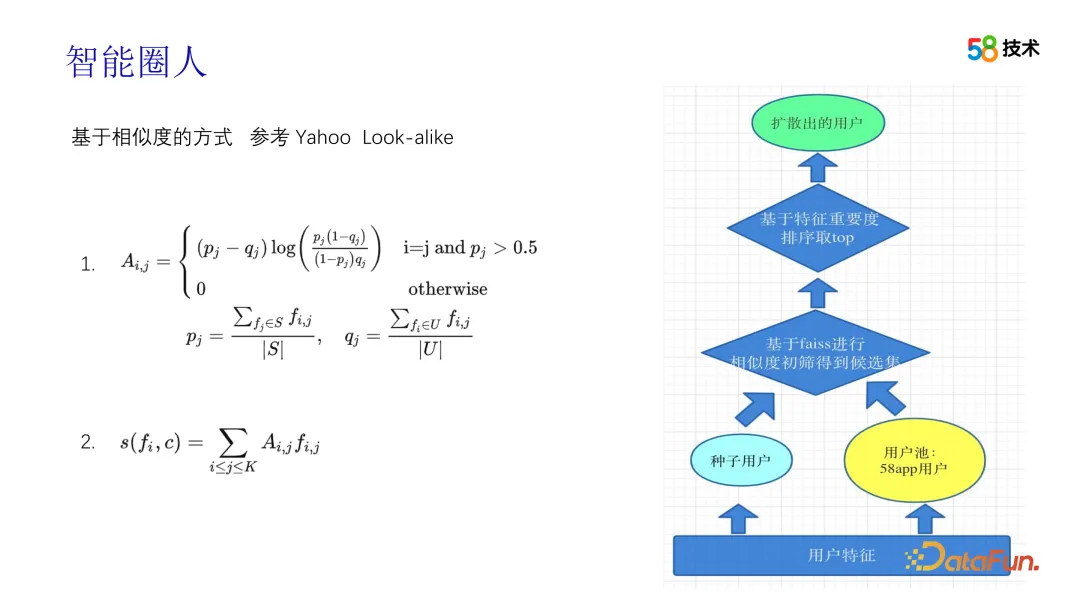
In the process of generating crowd packets, we mainly use Look-alike technology. We have gone through several stages in the evolution of this technology. In the early stage, we learned from Yahoo's solution and divided the output of the crowd package into recall and sorting modules. The recall module first constructs the feature vectors of all users, then uses minHash and local sensitive hashing technology to compress the feature vectors, and achieves retrieval similar to k-NN through a method similar to clustering and bucketing, and quickly calculates the relationship between seed users and Based on the pairwise similarity between the candidate groups, topN is selected as the recall group for each seed user. In the sorting stage, Information Value is first used to filter features, then the scores are calculated based on the filtered features, and finally the scores are sorted to finally produce a crowd package. Throughout the process, the algorithm played a key role in ensuring the accuracy and effectiveness of the crowd package.
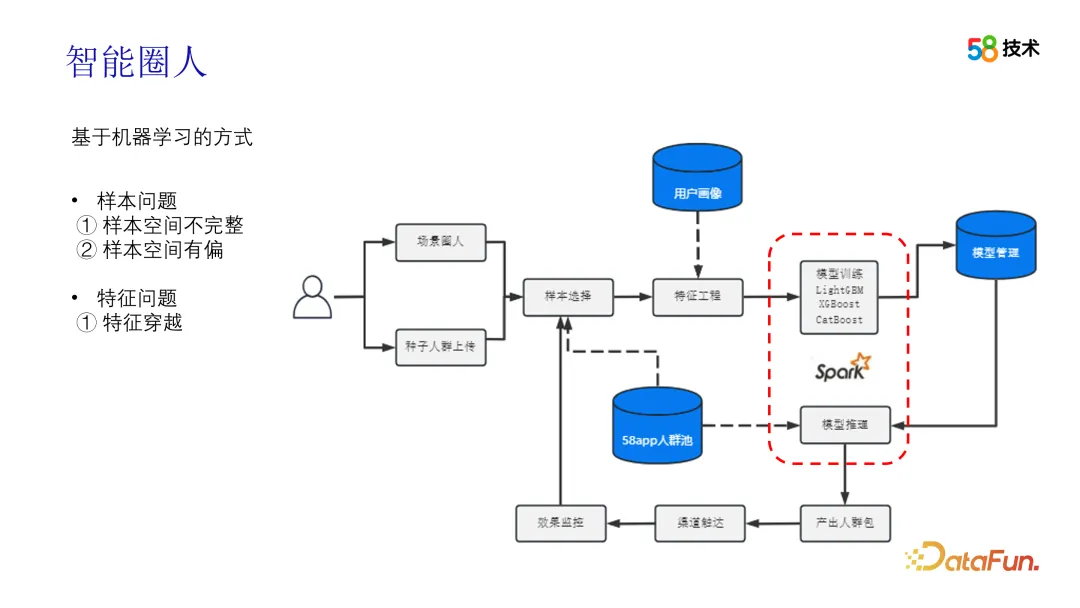
In addition to similarity-based solutions, machine learning-based methods also have good results. In practical applications, users can initiate requests through scene circle people or seed crowd uploading. The difference is whether the seed crowd is uploaded by users or automatically mined by us. After getting the seed population, that is, the positive samples, we need to select negative samples. We can use violent global random negative sampling, or we can use algorithms such as PU learning or TSA to complete the selection of negative samples. Next is the feature selection stage, which is divided into two options. One is to pre-prepare manually selected features in advance. After fixed feature engineering, models such as DeepFM can be used to complete training and CTR estimation, and TopN is selected as the crowd package based on CTR; Another option is to use all tags as features, automatically select and eliminate features through IV values ??and correlations, then use the AutoML framework to complete feature engineering and model training, and finally perform inference on the 58App crowd pool and output based on TopN Crowd package, connect to the channel to reach out, and finally collect the delivery effect data to complete the sample selection iteration.
There are some points worthy of attention in the above scheme. The first is the iteration of samples. When recycling effect data, not only the exposure data needs to be screened, but also the unexposed data, that is, Exposure Bias, needs to be debias processed. At the same time, the effect after iteration needs to be evaluated and verified offline to ensure the effect of iteration. In addition, the traversal problem also needs to be considered in terms of features, especially in the new scene, where the time factor of feature selection needs to be considered.
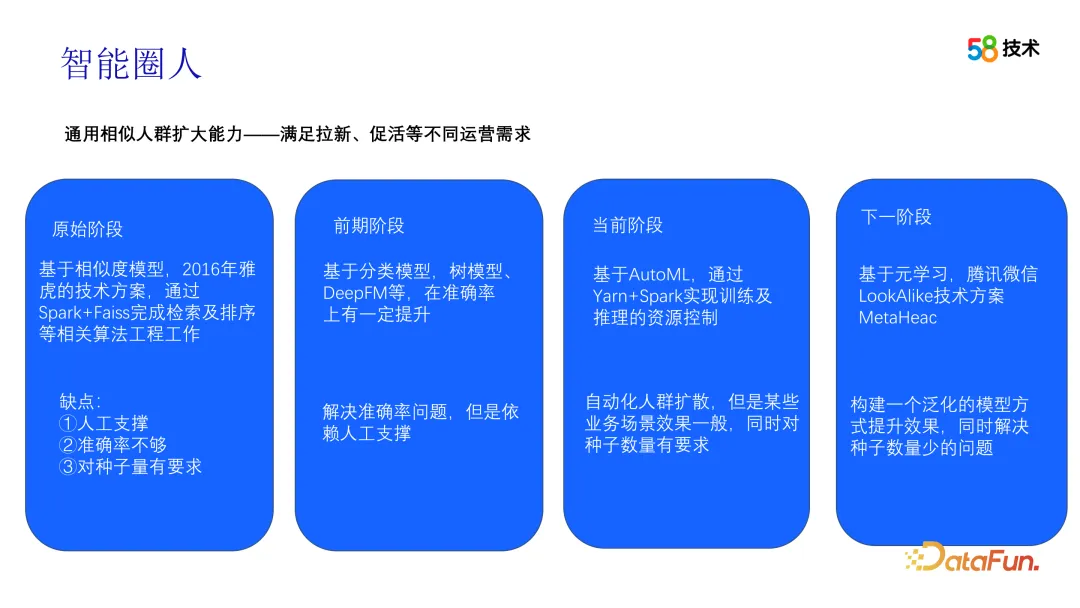
As more and more data are accumulated in operational scenarios, we begin to try to use this data to conduct offline experiments to optimize our iteration plan. One of them is the Look-alike method based on Tencent WeChat, which adopts a meta-learning method. Specifically, this method builds a generalized model, completes the model construction in the offline stage, and then uses a small amount of data sets to train the customized model and perform inference work in the online stage. This method can solve the problem of overfitting of the model when the sample size is relatively small. Multi-scenario and multi-target crowd diffusion is also one of our next iteration directions.
3. 58 Portrait Platform Application Cases
1. Personalization Resource position placement
Personalized resource position placement in 58App resource positions include screen opening, banner position, floating window, fees flow card, etc., all of which use the corresponding functions of the 58 user portrait platform. For example, price operations use the tag selection capabilities of the portrait platform to generate crowd packages and push specific content for them, completing refined operations for thousands of people.
2. Personalized push
Our portrait platform is also fully connected with 58’s push platform. Operation students can use Vientiane Circle Selection or Look-alike. Create a crowd, configure personalized copywriting, and reach users through push to achieve operational goals.
3. Search recommendation
Search recommendation is the most common application based on user portraits. 58 The two businesses of new cars and used cars do not have algorithm personnel, but they also want to make some personalized applications, so they have connected the content preference tags mentioned above. The content preference TopN tag is used in resource areas such as new car recommendations and related recommendations on the homepage. In the search position of used cars, this label is also used in the prompts of the search box and the related car series on the search discovery page. Compared with the previous method of using rules, accessing content preference tags as a solution in the early stage of the project has also achieved good results.
4. Outlook and Summary
The current portrait platform of 58 already possesses common portrait platform capabilities in the industry, and through algorithm blessing, it has achieved intelligent operation and other capabilities. It not only improves the operational effects of the business side, but also provides users with personalized services while also bringing a better user experience. Next, we will cooperate in depth with business parties to explore more application scenarios, summarize and refine, optimize and innovate during the cooperation process, and upgrade technology to meet various needs and challenges. We look forward to creating better solutions for users and enterprises. Great value.
The above is the detailed content of Application of algorithms in the construction of 58 portrait platform. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)



 How to execute php code after writing php code? Several common ways to execute php code
May 23, 2025 pm 08:33 PM
How to execute php code after writing php code? Several common ways to execute php code
May 23, 2025 pm 08:33 PM
PHP code can be executed in many ways: 1. Use the command line to directly enter the "php file name" to execute the script; 2. Put the file into the document root directory and access it through the browser through the web server; 3. Run it in the IDE and use the built-in debugging tool; 4. Use the online PHP sandbox or code execution platform for testing.
 How to update Debian Tomcat
May 28, 2025 pm 04:54 PM
How to update Debian Tomcat
May 28, 2025 pm 04:54 PM
Updating the Tomcat version in the Debian system generally includes the following process: Before performing the update operation, be sure to do a complete backup of the existing Tomcat environment. This covers the /opt/tomcat folder and its related configuration documents, such as server.xml, context.xml, and web.xml. The backup task can be completed through the following command: sudocp-r/opt/tomcat/opt/tomcat_backup Get the new version Tomcat Go to ApacheTomcat's official website to download the latest version. According to your Debian system
 What are the Debian Hadoop monitoring tools?
May 23, 2025 pm 09:57 PM
What are the Debian Hadoop monitoring tools?
May 23, 2025 pm 09:57 PM
There are many methods and tools for monitoring Hadoop clusters on Debian systems. The following are some commonly used monitoring tools and their usage methods: Hadoop's own monitoring tool HadoopAdminUI: Access the HadoopAdminUI interface through a browser to intuitively understand the cluster status and resource utilization. HadoopResourceManager: Access the ResourceManager WebUI (usually http://ResourceManager-IP:8088) to monitor cluster resource usage and job status. Hadoop
 What are the SEO optimization techniques for Debian Apache2?
May 28, 2025 pm 05:03 PM
What are the SEO optimization techniques for Debian Apache2?
May 28, 2025 pm 05:03 PM
DebianApache2's SEO optimization skills cover multiple levels. Here are some key methods: Keyword research: Use tools (such as keyword magic tools) to mine the core and auxiliary keywords of the page. High-quality content creation: produce valuable and original content, and the content needs to be conducted in-depth research to ensure smooth language and clear format. Content layout and structure optimization: Use titles and subtitles to guide reading. Write concise and clear paragraphs and sentences. Use the list to display key information. Combining multimedia such as pictures and videos to enhance expression. The blank design improves the readability of text. Technical level SEO improvement: robots.txt file: Specifies the access rights of search engine crawlers. Accelerate web page loading: optimized with the help of caching mechanism and Apache configuration
 Analysis of the reasons why the service cannot start after installing Apache
May 19, 2025 pm 07:24 PM
Analysis of the reasons why the service cannot start after installing Apache
May 19, 2025 pm 07:24 PM
The main reasons why the Apache service cannot be started are configuration file errors, port conflicts and permissions issues. 1. Configuration file error: Check httpd.conf or apache2.conf and use the apachectlconfigtest tool. 2. Port conflict: Change Listen directives, such as Listen8080, and update firewall rules. 3. Permissions issue: Make sure Apache has sufficient permissions, adjust directory permissions or run users.
 Using Oracle Database Integration with Hadoop in Big Data Environment
Jun 04, 2025 pm 10:24 PM
Using Oracle Database Integration with Hadoop in Big Data Environment
Jun 04, 2025 pm 10:24 PM
The main reason for integrating Oracle databases with Hadoop is to leverage Oracle's powerful data management and transaction processing capabilities, as well as Hadoop's large-scale data storage and analysis capabilities. The integration methods include: 1. Export data from OracleBigDataConnector to Hadoop; 2. Use ApacheSqoop for data transmission; 3. Read Hadoop data directly through Oracle's external table function; 4. Use OracleGoldenGate to achieve data synchronization.
 Complete tutorial on configuring an Apache server for PhpStorm
May 20, 2025 pm 07:57 PM
Complete tutorial on configuring an Apache server for PhpStorm
May 20, 2025 pm 07:57 PM
Configuring the Apache server in PhpStorm requires making sure that Apache is installed and running, then set the PHP interpreter path and web server deployment path in PhpStorm, and finally edit the Apache configuration file to add VirtualHost entry and restart Apache. The specific steps include: 1. Make sure Apache is installed and run; 2. Set the PHP interpreter path in PhpStorm; 3. Set the web server deployment path; 4. Edit the Apache configuration file to add VirtualHost entries; 5. Restart the Apache server.
 Configuration and management of multi-version Apache coexistence installation
May 21, 2025 pm 10:51 PM
Configuration and management of multi-version Apache coexistence installation
May 21, 2025 pm 10:51 PM
Multi-version Apache coexistence can be achieved through the following steps: 1. Install different versions of Apache to different directories; 2. Configure independent configuration files and listening ports for each version; 3. Use virtual hosts to further isolate different versions. Through these methods, multiple Apache versions can be run efficiently on the same server to meet the needs of different projects.
