
 Technology peripherals
AI
Exploring the boundaries of agents: AgentQuest, a modular benchmark framework for comprehensively measuring and improving the performance of large language model agents
Technology peripherals
AI
Exploring the boundaries of agents: AgentQuest, a modular benchmark framework for comprehensively measuring and improving the performance of large language model agents
Exploring the boundaries of agents: AgentQuest, a modular benchmark framework for comprehensively measuring and improving the performance of large language model agents
Apr 11, 2024 pm 08:52 PM
Based on the continuous optimization of large models, LLM agents - these powerful algorithmic entities have shown the potential to solve complex multi-step reasoning tasks. From natural language processing to deep learning, LLM agents are gradually becoming the focus of research and industry. They can not only understand and generate human language, but also formulate strategies, perform tasks in diverse environments, and even use API calls and coding to Build solutions.
In this context, the introduction of the AgentQuest framework is a milestone. It not only provides a modular benchmarking platform for the evaluation and progress of LLM agents, but also Its easily extensible API provides researchers with a powerful tool to track and improve the performance of these agents at a more granular level. The core of AgentQuest lies in its innovative evaluation indicators-progress rate and repetition rate, which can reveal the behavior pattern of the agent in solving tasks, thereby guiding the optimization and adjustment of the architecture.
"AgentQuest: A Modular Benchmark Framework to Measure Progress and Improve LLM Agents" was written by a diverse research team from NEC European Laboratories, Politecnico di Torino University and the University of Saint Cyril and Methodius. This paper will be presented at the 2024 conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT 2024), marking the team’s research results in the field of human language technology have been recognized by peers, not only for the value of the AgentQuest framework The recognition is also an affirmation of the future development potential of LLM agents.
The AgentQuest framework is a tool for measuring and improving the capabilities of large language model (LLM) agents. Its main contribution is to provide a modular and scalable benchmark testing platform. This platform can not only evaluate the performance of an agent on a specific task, but also reveal the behavior pattern of the agent in the process of solving the problem by showing the behavior pattern of the agent in the process of solving the problem. The advantage of AgentQuest is its flexibility and openness, which allows researchers to customize benchmarks according to their needs, thereby promoting the development of LLM agent technology.
AgentQuest Framework Overview
The AgentQuest framework is an innovative research tool designed to measure and improve large-scale language model (LLM) agents performance. It enables researchers to systematically track an agent's progress in performing complex tasks and identify potential areas for improvement by providing a modular series of benchmarks and evaluation metrics.
AgentQuest is a modular framework that supports multiple benchmarks and agent architectures. It introduces two new metrics - progress rate and repeat rate - to evaluate the performance of agent architectures. Behavior. This framework defines a standard interface for connecting arbitrary agent architectures to a diverse set of benchmarks and calculating progress and repetition rates from them.
In AgentQuest, four benchmark tests have been included: ALFWorld, Lateral Thinking Puzzles, Mastermind and Digital Solitude. In addition, AgentQuest also introduces new tests. You can easily add additional benchmarks without making changes to the agents under test.
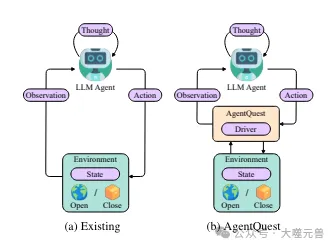 Picture
Picture
Figure 1: Overview of the baseline interaction of agents in the current framework AgentQuest. AgentQuest defines a common interface for interacting with benchmarks and calculating progress metrics, simplifying the addition of new benchmarks and allowing researchers to evaluate and test their agent architectures.
Basic composition and functionality
The core of the AgentQuest framework is its modular design, which allows researchers to add or modify benchmarks as needed. This flexibility is achieved by separating benchmarks and evaluation metrics into independent modules, each of which can be developed and optimized independently. The main components of the framework include:
Benchmark modules: These are predefined tasks that the agent must perform. They range from simple word games to complex logic puzzles.
Evaluation indicator module: Provides a set of tools to quantify agent performance, such as progress rate and repetition rate. These indicators help researchers understand the behavior pattern of agents in tasks.
API interface: allows researchers to connect their own agent architectures with the AgentQuest framework, as well as interact with external data sources and services.
The Importance of Modular Benchmarks and Metrics
A key advantage of modular benchmarks is that they provide a standardized way to evaluate the performance of different agents. performance. This means researchers can compare results from different agents under the same conditions, ensuring consistency and comparability of results. In addition, the modular design also allows researchers to tailor benchmarks to the needs of specific studies, which is often difficult to achieve in traditional benchmarking frameworks.
Evaluation metrics are equally important as they provide deep insights into the agent’s performance. For example, progress rate can show how efficient an agent is in solving a task, while repetition rate reveals whether an agent gets stuck in repetitions on certain steps, which could indicate a need to improve the decision-making process.
The scalability of AgentQuest
The API interface of AgentQuest is the key to its scalability. Through the API, researchers can easily integrate AgentQuest into existing research workflows, whether adding new benchmarks, evaluation metrics, or connecting to external data sources and services. This scalability not only accelerates the iterative process of research, but also promotes interdisciplinary collaboration, as experts from different fields can work together to solve common research questions using the AgentQuest framework.
The AgentQuest framework provides a powerful platform for the research and development of LLM agents through its modular benchmarking and evaluation metrics, as well as its extensibility through APIs. It not only promotes the standardization and replicability of research, but also paves the way for future innovation and collaboration of intelligent agents.
Benchmarking and Evaluation Metrics
In the AgentQuest framework, benchmarking is a key component to evaluate the performance of LLM agents. These tests not only provide a standardized environment to compare the abilities of different agents, but can also reveal the behavior patterns of agents when solving specific problems.
AgentQuest exposes a single unified Python interface, namely the driver and two classes that reflect the components of the agent-environment interaction (i.e. observations and actions). The observation class has two required properties: (i) output, a string reporting information about the state of the environment; (ii) completion, a boolean variable indicating whether the final task is currently completed. Action classes have one required attribute, action value. This is the string output directly by the agent. Once processed and provided to the environment, it triggers changes to the environment. To customize interactions, developers can define optional properties.
Mastermind Benchmark
Mastermind is a classic logic game where players need to guess a hidden color code. In the AgentQuest framework, this game is used as one of the benchmarks, where the agent is tasked with determining the correct code through a series of guesses. After each guess, the environment provides feedback, telling the agent how many were correct in color but in wrong position, and how many were correct in both color and position. This process continues until the agent guesses the correct code or reaches a preset limit of steps.
 Figure 2: Here we provide an example of how Mastermind implements interaction.
Figure 2: Here we provide an example of how Mastermind implements interaction.
Sudoku Benchmark
Sudoku is another popular logic puzzle that requires players to fill in numbers in a 9x9 grid, Make the numbers in each row, column and each 3x3 subgrid unique. In the AgentQuest framework, Sudoku is used as a benchmark to evaluate an agent's capabilities in spatial reasoning and planning. The agent must generate efficient number-filling strategies and solve the puzzle within a limited number of moves.
Evaluation Metrics: Progress Rate and Repeat Rate
AgentQuest introduces two new evaluation metrics: Progress Rate (PR) and Repeat Rate (RR). The progress rate is a value between 0 and 1 that measures the agent's progress in completing a task. It is calculated by dividing the number of milestones reached by the agent by the total number of milestones. For example, in the Mastermind game, if the agent guesses two correct colors and locations out of a total of four guesses, the progress rate is 0.5.
Repetition rate measures the tendency of an agent to repeat the same or similar actions during the execution of a task. When calculating the repetition rate, all previous actions of the agent are taken into account and a similarity function is used to determine whether the current action is similar to previous actions. Repetition rate is calculated by dividing the number of reps by the total number of reps (minus the first step).
Evaluate and improve LLM agent performance through metrics
These metrics provide researchers with a powerful tool for analysis and Improve the performance of LLM agents. By observing progress rates, researchers can understand how efficient an agent is at solving a problem and identify possible bottlenecks. At the same time, the analysis of repetition rates can reveal possible problems in the decision-making process of the agent, such as over-reliance on certain strategies or lack of innovation.
 Table 1: Overview of benchmarks available in AgentQuest.
Table 1: Overview of benchmarks available in AgentQuest.
In general, the benchmark testing and evaluation indicators in the AgentQuest framework provide a comprehensive evaluation system for the development of LLM agents. Through these tools, researchers can not only evaluate the current performance of agents, but also guide future improvement directions, thus promoting the application and development of LLM agents in various complex tasks.
Application Cases of AgentQuest
Practical application cases of the AgentQuest framework provide an in-depth understanding of its functionality and effectiveness, through Mastermind and other benchmarks Testing, we can observe the performance of LLM agents in different scenarios and analyze how to improve their performance through specific strategies.
Mastermind application case
In the Mastermind game, the AgentQuest framework is used to evaluate the logical reasoning ability of the agent. The agent needs to guess a hidden code consisting of numbers, and after each guess, the system provides feedback indicating the number and location of the correct number. Through this process, the agent learns how to adjust its guessing strategy based on feedback to achieve its goals more efficiently.
In practical applications, the initial performance of the agent may not be ideal, and the same or similar guesses are often repeated, resulting in a high repetition rate. However, by analyzing data on progress and repetition rates, researchers can identify shortcomings in the agent's decision-making process and take steps to improve it. For example, by introducing a memory component, the agent can remember previous guesses and avoid repeating ineffective attempts, thereby improving efficiency and accuracy.
Application cases of other benchmarks
In addition to Mastermind, AgentQuest also includes other benchmarks such as Sudoku, word games and logic puzzles, etc. . In these tests, the agent's performance is also affected by progress rate and repetition rate metrics. For example, in the Sudoku test, the agent needs to fill in a 9x9 grid so that the numbers in each row, each column, and each 3x3 subgrid are not repeated. This requires the agent to have spatial reasoning capabilities and strategic planning capabilities.
During these tests, the agent may encounter different challenges. Some agents may be excellent at spatial reasoning but deficient in strategy planning. Through the detailed feedback provided by the AgentQuest framework, researchers can identify problem areas in a targeted manner and improve the overall performance of the agent through algorithm optimization or adjustment of training methods.
The impact of memory components
The addition of memory components has a significant impact on the performance of the agent. In the Mastermind test, after adding the memory component, the agent was able to avoid repeating invalid guesses, thereby significantly reducing the repetition rate. This not only increases the speed at which the agent solves problems, but also increases the success rate. In addition, the memory component also enables the agent to learn and adapt faster when faced with similar problems, thereby improving its learning efficiency in the long term.
Overall, the AgentQuest framework provides a powerful tool for performance evaluation and improvement of LLM agents by providing modular benchmarking and evaluation metrics. Through the analysis of actual application cases, we can see that by adjusting strategies and introducing new components, such as memory modules, the performance of the agent can be significantly improved.
Experimental setup and result analysis
In the experimental setup of the AgentQuest framework, the researchers adopted a reference architecture based on a ready-made chat agent, consisting of Large language model (LLM) drivers such as GPT-4. This architecture was chosen because it is intuitive, easily extensible, and open source, which allows researchers to easily integrate and test different agent strategies.
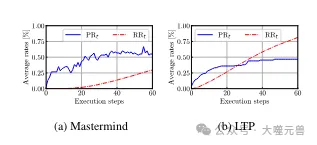 Picture
Picture
Figure 4: Average progress rate PRt and repetition rate RRt for Mastermind and LTP. Mastermind: RRt is low at first, but will increase after step 22, while the progress will also stop at 55%. LTP: Initially, higher RRt allows agents to succeed by making small changes, but later this levels off.
Experimental setup
The experimental setup included multiple benchmarks, such as Mastermind and ALFWorld, each designed to evaluate the agent performance in specific areas. The maximum number of execution steps is set in the experiment, usually 60 steps, to limit the number of attempts the agent can try when solving the problem. This limitation simulates the situation of limited resources in the real world and forces the agent to find the most effective solution in limited attempts.
Experimental result analysis
In the Mastermind benchmark test, the experimental results show that the repetition rate of the agent without a memory component is Relatively high, the rate of progress is also limited. This shows that agents tend to get stuck repeating invalid guesses when trying to solve problems. However, when the memory component was introduced, the agent's performance was significantly improved, with the success rate increasing from 47% to 60% and the repetition rate dropping to 0%. This shows that the memory component is crucial to improve the efficiency and accuracy of the agent.
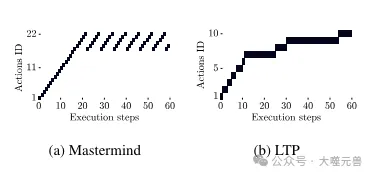 Picture
Picture
Figure 5: Example of repeated operations in Mastermind and LTP. Mastermind: Starts out with a series of unique moves, but then gets stuck repeating the same moves over and over again. LTP: Repeated actions are small variations on the same problem that lead to progress.
In the ALFWorld benchmark, the agent needs to explore a textual world to locate objects. Experimental results show that although the agent limited action repetitions while exploring the solution space (RR60 = 6%), it failed to solve all games (PR60 = 74%). This difference may be due to the fact that the agent requires more exploration steps when discovering objects. When extending the benchmark run time to 120 steps, both success and progress rates improved, further confirming AgentQuest's usefulness in understanding agent failures.
Adjustment of the agent architecture
According to the indicators of AgentQuest, researchers can adjust the agent architecture. For example, if an agent is found to have a high repetition rate on a certain benchmark, its decision-making algorithm may need to be improved to avoid repeating ineffective attempts. Likewise, if the rate of progress is low, the agent's learning process may need to be optimized to more quickly adapt to the environment and find solutions to problems.
The experimental setup and evaluation metrics provided by the AgentQuest framework provide in-depth insights into the performance of LLM agents. By analyzing experimental results, researchers can identify an agent's strengths and weaknesses and adjust the agent's architecture accordingly to improve its performance in a variety of tasks.
Discussion and future work
The proposal of the AgentQuest framework opens up new avenues for the research and development of large language model (LLM) agents. the way. It not only provides a systematic method to measure and improve the performance of LLM agents, but also promotes the research community's in-depth understanding of agent behavior.
AgentQuest’s potential impact in LLM agent research
AgentQuest enables researchers to More accurately measure the progress and efficiency of LLM agents on specific tasks. This precise assessment capability is critical for designing more efficient and intelligent agents. As LLM agents are increasingly used in various fields, from customer service to natural language processing, the in-depth analysis tools provided by AgentQuest will help researchers optimize the agent's decision-making process and improve its performance in practical applications.
AgentQuest’s role in promoting transparency and fairness
Another important contribution of AgentQuest is to increase the transparency of LLM agent research. Through public evaluation metrics and replicable benchmarks, AgentQuest encourages the practice of open science, making research results easier to verify and compare. Additionally, the modular nature of AgentQuest allows researchers to customize benchmarks, meaning tests can be designed for different needs and contexts, promoting diversity and inclusion in research.
Future development of AgentQuest and possible contributions from the research community
Keeping up with the advancement of technology, the AgentQuest framework is expected to continue to be expanded and improved. With the addition of new benchmarks and evaluation indicators, AgentQuest will be able to cover more types of tasks and scenarios, providing a more comprehensive perspective for the evaluation of LLM agents. In addition, with the advancement of artificial intelligence technology, AgentQuest may also integrate more advanced functions, such as the ability to automatically adjust the agent architecture to achieve more efficient performance optimization.
The research community’s contributions to AgentQuest are also integral to its development. The open source nature means researchers can share their improvements and innovations, accelerating the advancement of the AgentQuest framework. At the same time, feedback and practical experience from the research community will help AgentQuest better meet the needs of practical applications and promote the development of LLM agent technology.
Reference: https://arxiv.org/abs/2404.06411
The above is the detailed content of Exploring the boundaries of agents: AgentQuest, a modular benchmark framework for comprehensively measuring and improving the performance of large language model agents. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)



 PHP calls AI intelligent voice assistant PHP voice interaction system construction
Jul 25, 2025 pm 08:45 PM
PHP calls AI intelligent voice assistant PHP voice interaction system construction
Jul 25, 2025 pm 08:45 PM
User voice input is captured and sent to the PHP backend through the MediaRecorder API of the front-end JavaScript; 2. PHP saves the audio as a temporary file and calls STTAPI (such as Google or Baidu voice recognition) to convert it into text; 3. PHP sends the text to an AI service (such as OpenAIGPT) to obtain intelligent reply; 4. PHP then calls TTSAPI (such as Baidu or Google voice synthesis) to convert the reply to a voice file; 5. PHP streams the voice file back to the front-end to play, completing interaction. The entire process is dominated by PHP to ensure seamless connection between all links.
 How to use PHP to build social sharing functions PHP sharing interface integration practice
Jul 25, 2025 pm 08:51 PM
How to use PHP to build social sharing functions PHP sharing interface integration practice
Jul 25, 2025 pm 08:51 PM
The core method of building social sharing functions in PHP is to dynamically generate sharing links that meet the requirements of each platform. 1. First get the current page or specified URL and article information; 2. Use urlencode to encode the parameters; 3. Splice and generate sharing links according to the protocols of each platform; 4. Display links on the front end for users to click and share; 5. Dynamically generate OG tags on the page to optimize sharing content display; 6. Be sure to escape user input to prevent XSS attacks. This method does not require complex authentication, has low maintenance costs, and is suitable for most content sharing needs.
 How to use PHP combined with AI to achieve text error correction PHP syntax detection and optimization
Jul 25, 2025 pm 08:57 PM
How to use PHP combined with AI to achieve text error correction PHP syntax detection and optimization
Jul 25, 2025 pm 08:57 PM
To realize text error correction and syntax optimization with AI, you need to follow the following steps: 1. Select a suitable AI model or API, such as Baidu, Tencent API or open source NLP library; 2. Call the API through PHP's curl or Guzzle and process the return results; 3. Display error correction information in the application and allow users to choose whether to adopt it; 4. Use php-l and PHP_CodeSniffer for syntax detection and code optimization; 5. Continuously collect feedback and update the model or rules to improve the effect. When choosing AIAPI, focus on evaluating accuracy, response speed, price and support for PHP. Code optimization should follow PSR specifications, use cache reasonably, avoid circular queries, review code regularly, and use X
 python seaborn jointplot example
Jul 26, 2025 am 08:11 AM
python seaborn jointplot example
Jul 26, 2025 am 08:11 AM
Use Seaborn's jointplot to quickly visualize the relationship and distribution between two variables; 2. The basic scatter plot is implemented by sns.jointplot(data=tips,x="total_bill",y="tip",kind="scatter"), the center is a scatter plot, and the histogram is displayed on the upper and lower and right sides; 3. Add regression lines and density information to a kind="reg", and combine marginal_kws to set the edge plot style; 4. When the data volume is large, it is recommended to use "hex"
 python list to string conversion example
Jul 26, 2025 am 08:00 AM
python list to string conversion example
Jul 26, 2025 am 08:00 AM
String lists can be merged with join() method, such as ''.join(words) to get "HelloworldfromPython"; 2. Number lists must be converted to strings with map(str, numbers) or [str(x)forxinnumbers] before joining; 3. Any type list can be directly converted to strings with brackets and quotes, suitable for debugging; 4. Custom formats can be implemented by generator expressions combined with join(), such as '|'.join(f"[{item}]"foriteminitems) output"[a]|[
 python pandas melt example
Jul 27, 2025 am 02:48 AM
python pandas melt example
Jul 27, 2025 am 02:48 AM
pandas.melt() is used to convert wide format data into long format. The answer is to define new column names by specifying id_vars retain the identification column, value_vars select the column to be melted, var_name and value_name, 1.id_vars='Name' means that the Name column remains unchanged, 2.value_vars=['Math','English','Science'] specifies the column to be melted, 3.var_name='Subject' sets the new column name of the original column name, 4.value_name='Score' sets the new column name of the original value, and finally generates three columns including Name, Subject and Score.
 Optimizing Python for Memory-Bound Operations
Jul 28, 2025 am 03:22 AM
Optimizing Python for Memory-Bound Operations
Jul 28, 2025 am 03:22 AM
Pythoncanbeoptimizedformemory-boundoperationsbyreducingoverheadthroughgenerators,efficientdatastructures,andmanagingobjectlifetimes.First,usegeneratorsinsteadofliststoprocesslargedatasetsoneitematatime,avoidingloadingeverythingintomemory.Second,choos
 python connect to sql server pyodbc example
Jul 30, 2025 am 02:53 AM
python connect to sql server pyodbc example
Jul 30, 2025 am 02:53 AM
Install pyodbc: Use the pipinstallpyodbc command to install the library; 2. Connect SQLServer: Use the connection string containing DRIVER, SERVER, DATABASE, UID/PWD or Trusted_Connection through the pyodbc.connect() method, and support SQL authentication or Windows authentication respectively; 3. Check the installed driver: Run pyodbc.drivers() and filter the driver name containing 'SQLServer' to ensure that the correct driver name is used such as 'ODBCDriver17 for SQLServer'; 4. Key parameters of the connection string
