
 Software Tutorial
Computer Software
Zhihu releases the latest large-scale model application 'Search Aggregation' and starts internal testing today
Software Tutorial
Computer Software
Zhihu releases the latest large-scale model application 'Search Aggregation' and starts internal testing today
Zhihu releases the latest large-scale model application 'Search Aggregation' and starts internal testing today
Mar 06, 2024 pm 10:00 PM
Zhihu released the latest large-scale model application "Search Aggregation" and started internal testing today. This new feature will provide users with more intelligent and personalized search results, helping users find the information they need faster. PHP editor Strawberry will take you to understand the characteristics and usage of this function, so that you can make better use of this new function and obtain more valuable information.

As previously reported, at the "2023 Zhihu Discovery Conference" in April, Zhihu released the large language model "Zhihaitu AI" and internally tested the "Hot List Summary" of the large model application function on the site. A month later, Zhihu has brought another large model application function "search aggregation" on the site. This product applies large model capabilities to Zhihu search. Whenever a user triggers a search, the system will aggregate opinions from a large number of questions and answers, improving the efficiency of users in obtaining information and forming decisions. Li Dahai said that "search aggregation" will start internal testing today.
At the press conference, Face Wall Intelligence teamed up with the OpenBMB community to open source the self-developed CPM-Bee 10b model. Li Dahai introduced that the model is trained independently from scratch, based on Transformer architecture, excellent bilingual performance in Chinese and English, with tens of billions of parameters and trillions of high-quality corpus. In the ZeroCLUE review, the CPM-Bee 10b scored an overall score of 78.18 On the English common sense knowledge reasoning list, CPM-Bee 10b received an average score of 67 points, which is comparable to the English open source model LLaMA. "CPM-Bee10b It will be fully open source and allowed for commercial use. "Li Dahai said that Wall-Facing Intelligence has always adhered to the open source route and will continue to embrace open source in the future to promote the prosperity of technology and ecology in the field of large models.
The conference also brought the dialogue model product "Luca" developed by Wallface Intelligence. This product has further improved performance on the open source basic model and can perform intelligent interaction and support multiple rounds of dialogue. During the live demonstration at the press conference, "Luca" demonstrated a number of capabilities. It can not only help people understand world knowledge, process mathematical logic, write program codes, and inspire creative inspiration; it can also use massive amounts of knowledge data to help people better obtain Information, planning, problem solving. The press conference also demonstrated the multi-modal understanding ability of "Luca". It can not only analyze picture information such as landscapes and geography, but also understand the emotional meaning conveyed by human pictures. In addition, "Luca" can also find papers and generate abstracts. Li Dahai introduced that "Luka" has now started internal testing.
For more information, please pay attention to this site.
The above is the detailed content of Zhihu releases the latest large-scale model application 'Search Aggregation' and starts internal testing today. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)



 Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
On May 30, Tencent announced a comprehensive upgrade of its Hunyuan model. The App "Tencent Yuanbao" based on the Hunyuan model was officially launched and can be downloaded from Apple and Android app stores. Compared with the Hunyuan applet version in the previous testing stage, Tencent Yuanbao provides core capabilities such as AI search, AI summary, and AI writing for work efficiency scenarios; for daily life scenarios, Yuanbao's gameplay is also richer and provides multiple features. AI application, and new gameplay methods such as creating personal agents are added. "Tencent does not strive to be the first to make large models." Liu Yuhong, vice president of Tencent Cloud and head of Tencent Hunyuan large model, said: "In the past year, we continued to promote the capabilities of Tencent Hunyuan large model. In the rich and massive Polish technology in business scenarios while gaining insights into users’ real needs
 Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Tan Dai, President of Volcano Engine, said that companies that want to implement large models well face three key challenges: model effectiveness, inference costs, and implementation difficulty: they must have good basic large models as support to solve complex problems, and they must also have low-cost inference. Services allow large models to be widely used, and more tools, platforms and applications are needed to help companies implement scenarios. ——Tan Dai, President of Huoshan Engine 01. The large bean bag model makes its debut and is heavily used. Polishing the model effect is the most critical challenge for the implementation of AI. Tan Dai pointed out that only through extensive use can a good model be polished. Currently, the Doubao model processes 120 billion tokens of text and generates 30 million images every day. In order to help enterprises implement large-scale model scenarios, the beanbao large-scale model independently developed by ByteDance will be launched through the volcano
 GPT Store can't even open its doors. How dare this domestic platform take this path? ?
Apr 19, 2024 pm 09:30 PM
GPT Store can't even open its doors. How dare this domestic platform take this path? ?
Apr 19, 2024 pm 09:30 PM
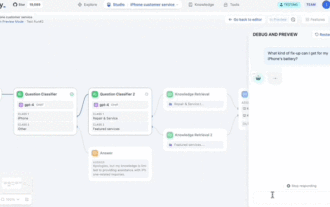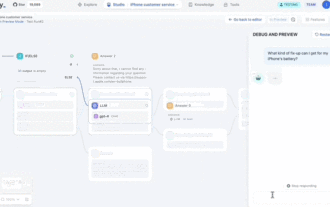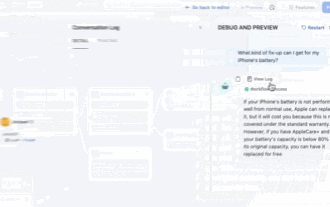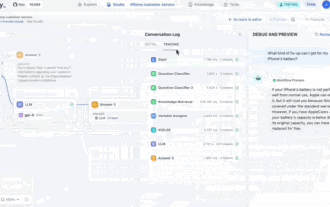
Pay attention, this man has connected more than 1,000 large models, allowing you to plug in and switch seamlessly. Recently, a visual AI workflow has been launched: giving you an intuitive drag-and-drop interface, you can drag, pull, and drag to arrange your own workflow on an infinite canvas. As the saying goes, war costs speed, and Qubit heard that within 48 hours of this AIWorkflow going online, users had already configured personal workflows with more than 100 nodes. Without further ado, what I want to talk about today is Dify, an LLMOps company, and its CEO Zhang Luyu. Zhang Luyu is also the founder of Dify. Before joining the business, he had 11 years of experience in the Internet industry. I am engaged in product design, understand project management, and have some unique insights into SaaS. Later he
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Benchmark GPT-4! China Mobile's Jiutian large model passed dual registration
Apr 04, 2024 am 09:31 AM
Benchmark GPT-4! China Mobile's Jiutian large model passed dual registration
Apr 04, 2024 am 09:31 AM
According to news on April 4, the Cyberspace Administration of China recently released a list of registered large models, and China Mobile’s “Jiutian Natural Language Interaction Large Model” was included in it, marking that China Mobile’s Jiutian AI large model can officially provide generative artificial intelligence services to the outside world. . China Mobile stated that this is the first large-scale model developed by a central enterprise to have passed both the national "Generative Artificial Intelligence Service Registration" and the "Domestic Deep Synthetic Service Algorithm Registration" dual registrations. According to reports, Jiutian’s natural language interaction large model has the characteristics of enhanced industry capabilities, security and credibility, and supports full-stack localization. It has formed various parameter versions such as 9 billion, 13.9 billion, 57 billion, and 100 billion, and can be flexibly deployed in Cloud, edge and end are different situations
 Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
1. Background Introduction First, let’s introduce the development history of Yunwen Technology. Yunwen Technology Company...2023 is the period when large models are prevalent. Many companies believe that the importance of graphs has been greatly reduced after large models, and the preset information systems studied previously are no longer important. However, with the promotion of RAG and the prevalence of data governance, we have found that more efficient data governance and high-quality data are important prerequisites for improving the effectiveness of privatized large models. Therefore, more and more companies are beginning to pay attention to knowledge construction related content. This also promotes the construction and processing of knowledge to a higher level, where there are many techniques and methods that can be explored. It can be seen that the emergence of a new technology does not necessarily defeat all old technologies. It is also possible that the new technology and the old technology will be integrated with each other.
 The computer I spent 300 yuan to assemble successfully ran through the local large model
Apr 12, 2024 am 08:07 AM
The computer I spent 300 yuan to assemble successfully ran through the local large model
Apr 12, 2024 am 08:07 AM
If 2023 is recognized as the first year of AI, then 2024 is likely to be a key year for the popularization of large AI models. In the past year, a large number of large AI models and a large number of AI applications have emerged. Manufacturers such as Meta and Google have also begun to launch their own online/local large models to the public, similar to "AI artificial intelligence" that is out of reach. The concept suddenly came to people. Nowadays, people are increasingly exposed to artificial intelligence in their lives. If you look carefully, you will find that almost all of the various AI applications you have access to are deployed on the "cloud". If you want to build a device that can run large models locally, then the hardware is a brand-new AIPC priced at more than 5,000 yuan. For ordinary people,
 New test benchmark released, the most powerful open source Llama 3 is embarrassed
Apr 23, 2024 pm 12:13 PM
New test benchmark released, the most powerful open source Llama 3 is embarrassed
Apr 23, 2024 pm 12:13 PM
If the test questions are too simple, both top students and poor students can get 90 points, and the gap cannot be widened... With the release of stronger models such as Claude3, Llama3 and even GPT-5 later, the industry is in urgent need of a more difficult and differentiated model Benchmarks. LMSYS, the organization behind the large model arena, launched the next generation benchmark, Arena-Hard, which attracted widespread attention. There is also the latest reference for the strength of the two fine-tuned versions of Llama3 instructions. Compared with MTBench, which had similar scores before, the Arena-Hard discrimination increased from 22.6% to 87.4%, which is stronger and weaker at a glance. Arena-Hard is built using real-time human data from the arena and has a consistency rate of 89.1% with human preferences.
