
 Technology peripherals
AI
Distillation can also be Step-by-Step: the new method allows small models to be comparable to large models 2000 times the size
Technology peripherals
AI
Distillation can also be Step-by-Step: the new method allows small models to be comparable to large models 2000 times the size
Distillation can also be Step-by-Step: the new method allows small models to be comparable to large models 2000 times the size
May 18, 2023 pm 06:31 PM
Although large-scale language models have amazing capabilities, due to their large scale, the costs required for their deployment are often huge. The University of Washington, together with the Google Cloud Computing Artificial Intelligence Research Institute and Google Research, further solved this problem and proposed the Distilling Step-by-Step paradigm to help model training. Compared with LLM, this method is more effective in training small models and applying them to specific tasks, and requires less training data than traditional fine-tuning and distillation. On a benchmark task, their 770M T5 model outperformed the 540B PaLM model. Impressively, their model only used 80% of the available data.

While large language models (LLMs) have demonstrated impressive Few-shot learning capability, but it is difficult to deploy such a large-scale model in real applications. Dedicated infrastructure serving a 175 billion parameter scale LLM requires at least 350GB of GPU memory. What's more, today's state-of-the-art LLM is composed of more than 500 billion parameters, which means it requires more memory and computing resources. Such computing requirements are out of reach for most manufacturers, let alone applications that require low latency.
In order to solve this problem of large models, deployers often use smaller specific models instead. These smaller models are trained using common paradigms - fine-tuning or distillation. Fine-tuning upgrades a small pre-trained model using downstream human annotated data. Distillation trains an equally smaller model using the labels produced by the larger LLM. Unfortunately, these paradigms come at a cost while reducing model size: to achieve comparable performance to LLM, fine-tuning requires expensive human labels, while distillation requires large amounts of unlabeled data that is difficult to obtain.
In a paper titled "Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes", researchers from the University of Washington and Google A new simple mechanism, Distilling step-bystep, is introduced for training smaller models using less training data. This mechanism reduces the amount of training data required to fine-tune and distill the LLM, resulting in a smaller model size.

Paper link: https://arxiv.org/pdf/2305.02301 v1.pdf
#The core of this mechanism is to change the perspective and regard LLM as an agent that can reason, rather than as a source of noise labels. LLM can generate natural language rationales that can be used to explain and support the labels predicted by the model. For example, when asked "A gentleman carries golf equipment, what might he have? (a) clubs, (b) auditorium, (c) meditation center, (d) conference, (e) church" , LLM can answer "(a) club" through chain of thought (CoT) reasoning, and rationalize this label by explaining that "the answer must be something used to play golf." Of the above choices, only clubs are used for golf. We use these justifications as additional, richer information to train smaller models in a multi-task training setting and perform label prediction and justification prediction.
As shown in Figure 1, stepwise distillation can learn task-specific small models with less than 1/500 the number of parameters of LLM. Stepwise distillation also uses far fewer training examples than traditional fine-tuning or distillation.

Experimental results show that among the 4 NLP benchmarks, there are three promising experiments in conclusion.
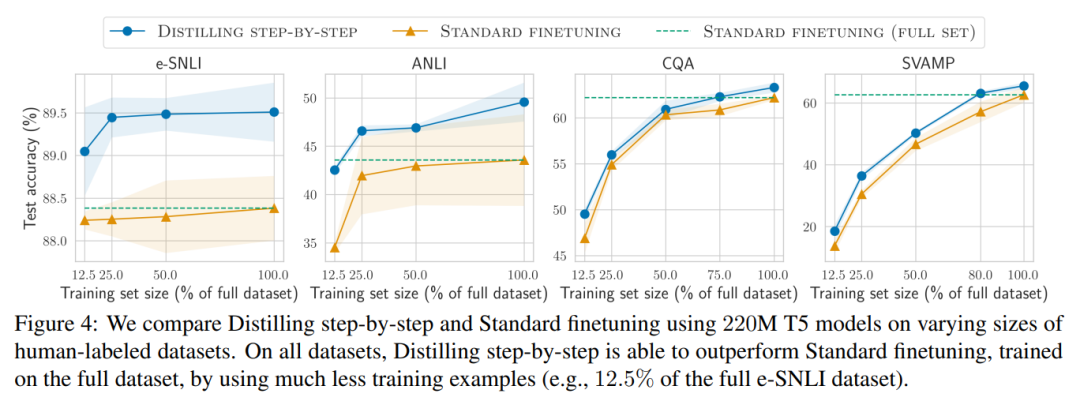
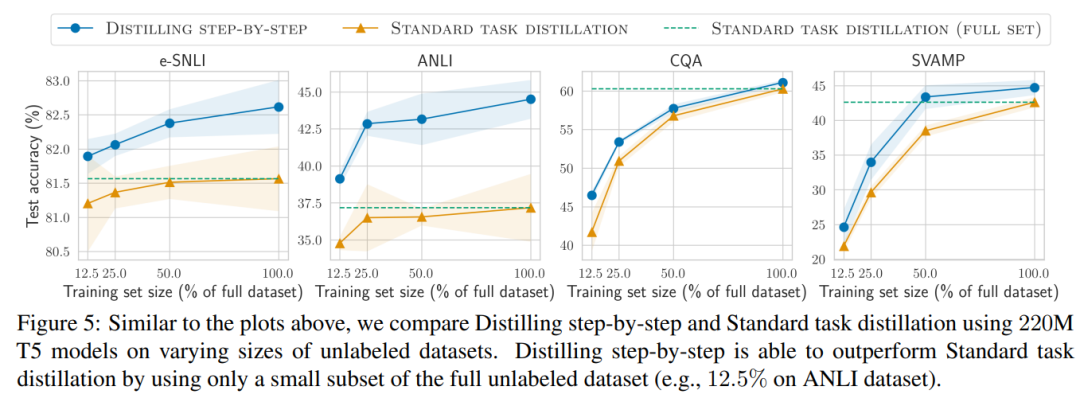
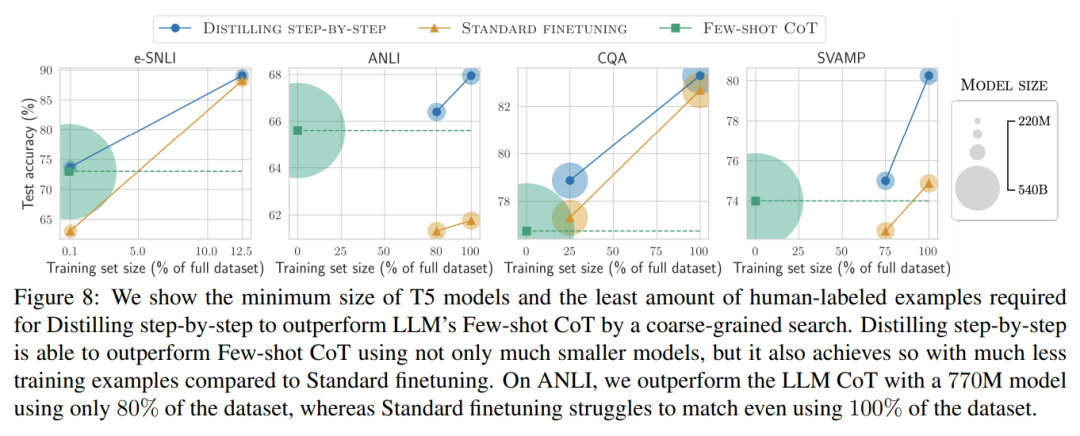
- First, compared to fine-tuning and distillation, the stepwise distillation model achieves better performance on each data set, reducing the number of training instances by more than 50% on average (up to more than 85%) .
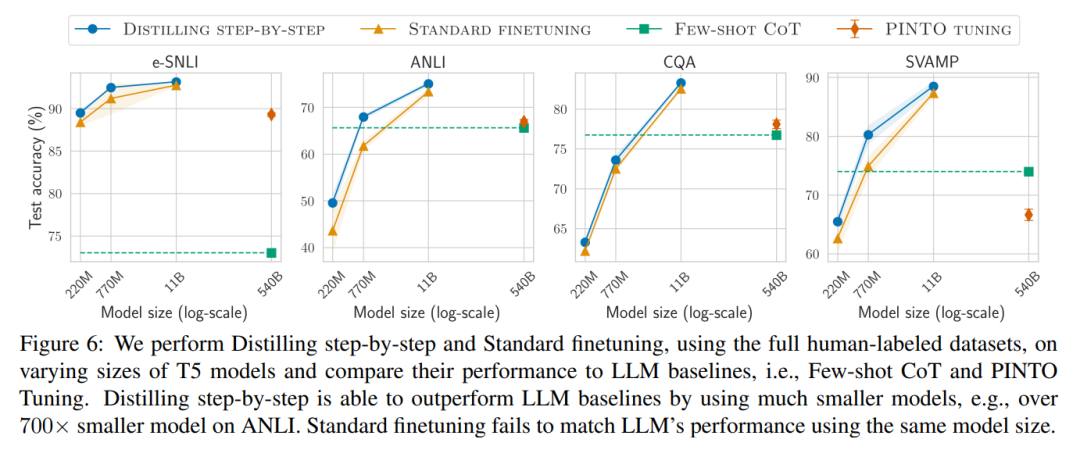
- Second, our model outperforms LLM when the model size is smaller (up to 2000 times smaller), greatly reducing the computational cost required for model deployment .
- Third, this research reduces the size of the model while also reducing the amount of data required to go beyond LLM. The researchers surpassed the performance of LLM with 540B parameters using a 770M T5 model. This smaller model uses only 80% of the labeled data set of existing fine-tuning methods.
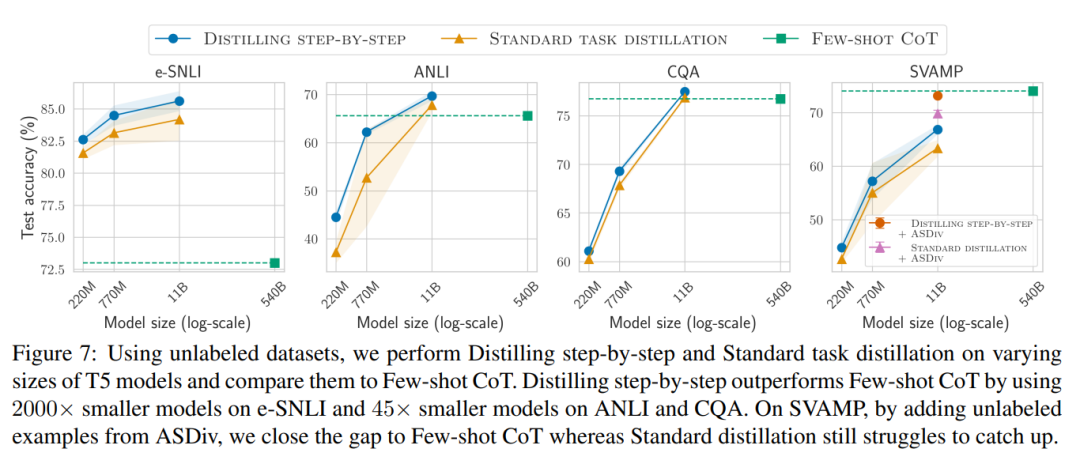
When there is only unlabeled data, the performance of the small model is still better than that of LLM - only using a 11B T5 model exceeds The performance of PaLM of 540B has been improved.
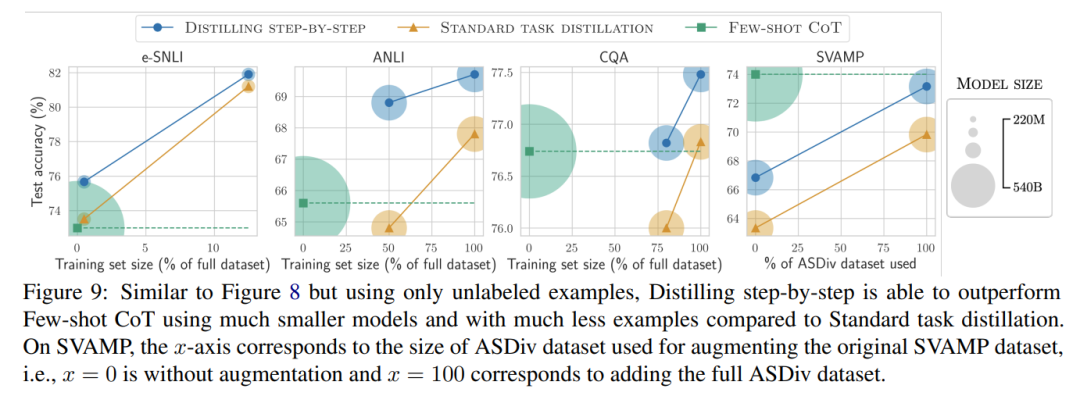
The study further shows that when a smaller model performs worse than LLM, stepwise distillation can more effectively utilize additional unlabeled data than standard distillation methods. Make smaller models comparable to the performance of LLM.
Stepwise Distillation
The researchers proposed a new paradigm of stepwise distillation, which uses the reasoning ability of LLM to predict its predictions to train smaller models in a data-efficient manner. Model. The overall framework is shown in Figure 2.
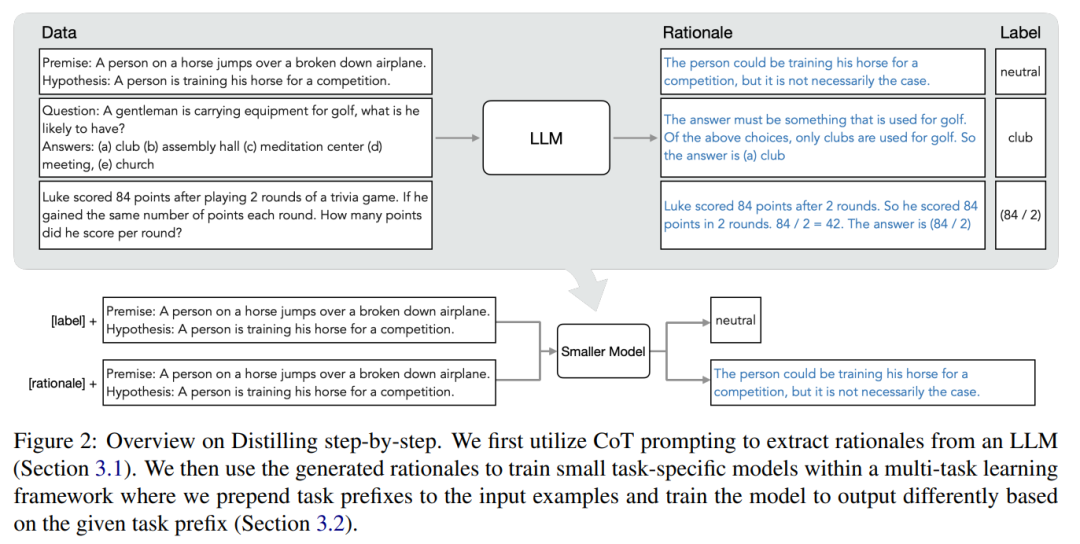
The paradigm has two simple steps: first, given an LLM and an An unlabeled data set prompts LLM to generate an output label and a justification for the label. The rationale is explained in natural language and provides support for the label predicted by the model (see Figure 2). Justification is an emergent behavioral property of current self-supervised LLMs.
Then, in addition to task labels, use these reasons to train smaller downstream models. To put it bluntly, reasons can provide richer and more detailed information to explain why an input is mapped to a specific output label.
Experimental results
The researchers verified the effectiveness of stepwise distillation in the experiment. First, compared to standard fine-tuning and task distillation methods, stepwise distillation helps achieve better performance with a much smaller number of training examples, significantly improving the data efficiency of learning small task-specific models.
#Secondly, Studies show that the stepwise distillation method surpasses the performance of LLM with smaller model sizes, significantly reducing deployment costs compared to llm.
The above is the detailed content of Distillation can also be Step-by-Step: the new method allows small models to be comparable to large models 2000 times the size. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)



 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!
Apr 15, 2024 am 09:01 AM
The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!
Apr 15, 2024 am 09:01 AM
Ollama is a super practical tool that allows you to easily run open source models such as Llama2, Mistral, and Gemma locally. In this article, I will introduce how to use Ollama to vectorize text. If you have not installed Ollama locally, you can read this article. In this article we will use the nomic-embed-text[2] model. It is a text encoder that outperforms OpenAI text-embedding-ada-002 and text-embedding-3-small on short context and long context tasks. Start the nomic-embed-text service when you have successfully installed o
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
