


In many real-world applications, data is not purely textual—it may include images, tables, and charts that help reinforce the narrative. A multimodal report generator allows you to incorporate both text and images into a final output, making your reports more dynamic and visually rich.
This article outlines how to build such a pipeline using:
- LlamaIndex for orchestrating document parsing and query engines,
- OpenAI language models for textual analysis,
- LlamaParse to extract both text and images from PDF documents,
- An observability setup using Arize Phoenix (via LlamaTrace) for logging and debugging.
The end result is a pipeline that can process an entire PDF slide deck—both text and visuals—and generate a structured report containing both text and images.
Learning Objectives
- Understand how to integrate text and visuals for effective financial report generation using multimodal pipelines.
- Learn to utilize LlamaIndex and LlamaParse for enhanced financial report generation with structured outputs.
- Explore LlamaParse for extracting both text and images from PDF documents effectively.
- Set up observability using Arize Phoenix (via LlamaTrace) for logging and debugging complex pipelines.
- Create a structured query engine to generate reports that interleave text summaries with visual elements.
This article was published as a part of theData Science Blogathon.
Table of contents
- Overview of the Process
- Step-by-Step Implementation
- Step 1: Install and Import Dependencies
- Step 2: Set Up Observability
- Step 3: Load the data – Obtain Your Slide Deck
- Step 4: Set Up Models
- Step 5: Parse the Document with LlamaParse
- Step 6: Associate Text and Images
- Step 7: Build a Summary Index
- Step 8: Define a Structured Output Schema
- Step 9: Create a Structured Query Engine
- Conclusion
- Frequently Asked Questions
Overview of the Process
Building a multimodal report generator involves creating a pipeline that seamlessly integrates textual and visual elements from complex documents like PDFs. The process starts with installing the necessary libraries, such as LlamaIndex for document parsing and query orchestration, and LlamaParse for extracting both text and images. Observability is established using Arize Phoenix (via LlamaTrace) to monitor and debug the pipeline.
Once the setup is complete, the pipeline processes a PDF document, parsing its content into structured text and rendering visual elements like tables and charts. These parsed elements are then associated, creating a unified dataset. A SummaryIndex is built to enable high-level insights, and a structured query engine is developed to generate reports that blend textual analysis with relevant visuals. The result is a dynamic and interactive report generator that transforms static documents into rich, multimodal outputs tailored for user queries.
Step-by-Step Implementation
Follow this detailed guide to build a multimodal report generator, from setting up dependencies to generating structured outputs with integrated text and images. Each step ensures a seamless integration of LlamaIndex, LlamaParse, and Arize Phoenix for an efficient and dynamic pipeline.
Step 1: Install and Import Dependencies
You’ll need the following libraries running on Python 3.9.9 :
- llama-index
- llama-parse (for text image parsing)
- llama-index-callbacks-arize-phoenix (for observability/logging)
- nest_asyncio (to handle async event loops in notebooks)
!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
Step 2: Set Up Observability
We integrate with LlamaTrace – LlamaCloud API (Arize Phoenix). First, obtain an API key from llamatrace.com, then set up environment variables to send traces to Phoenix.
Phoenix API key can be obtained by signing up for LlamaTrace here , then navigate to the bottom left panel and click on ‘Keys’ where you should find your API key.
For example:
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
)
Step 3: Load the data – Obtain Your Slide Deck
For demonstration, we use ConocoPhillips’ 2023 investor meeting slide deck. We download the PDF:
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")
Check if the pdf slide deck is in the data folder, if not place it in the data folder and name it as you want.
Step 4: Set Up Models
You need an embedding model and an LLM. In this example:
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
Next, you register these as the default for LlamaIndex:
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm
Step 5: Parse the Document with LlamaParse
LlamaParse can extract text and images (via a multimodal large model). For each PDF page, it returns:
- Markdown text (with tables, headings, bullet points, etc.)
- A rendered image (saved locally)
print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"]

print(md_json_list[10]["md"])
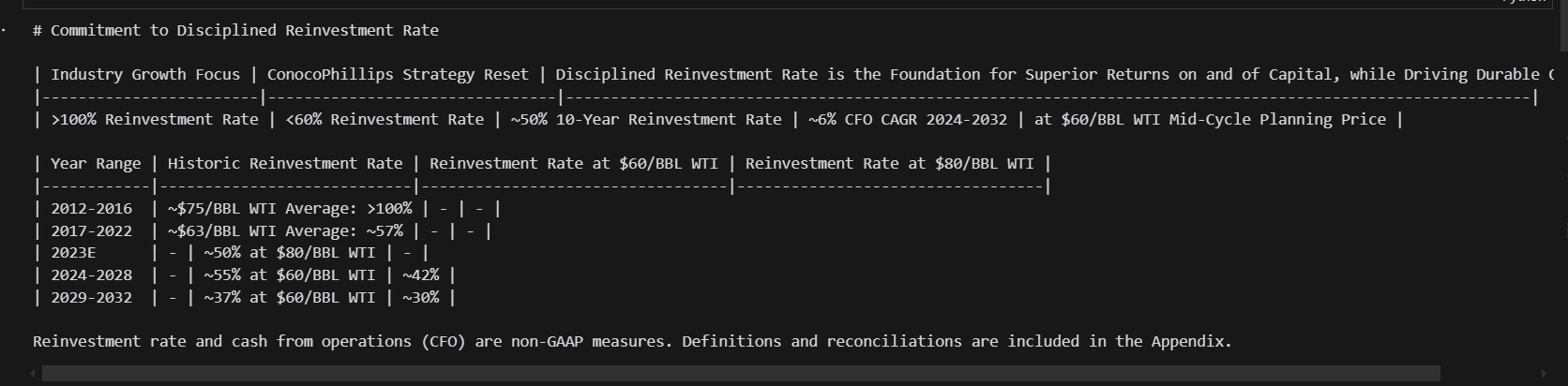
print(md_json_list[1].keys())

!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
Step 6: Associate Text and Images
We create a list of TextNode objects (LlamaIndex’s data structure) for each page. Each node has metadata about the page number and the corresponding image file path:
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
)

Step 7: Build a Summary Index
With these text nodes in hand, you can create a SummaryIndex:
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")
The SummaryIndex ensures you can easily retrieve or generate high-level summaries over the entire document.
Step 8: Define a Structured Output Schema
Our pipeline aims to produce a final output with interleaved text blocks and image blocks. For that, we create a custom Pydantic model (using Pydantic v2 or ensuring compatibility) with two block types—TextBlock and ImageBlock—and a parent model ReportOutput:
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
The key point: ReportOutput requires at least one image block, ensuring the final answer is multimodal.
Step 9: Create a Structured Query Engine
LlamaIndex allows you to use a “structured LLM” (i.e., an LLM whose output is automatically parsed into a specific schema). Here’s how:
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm

print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"]

print(md_json_list[10]["md"])

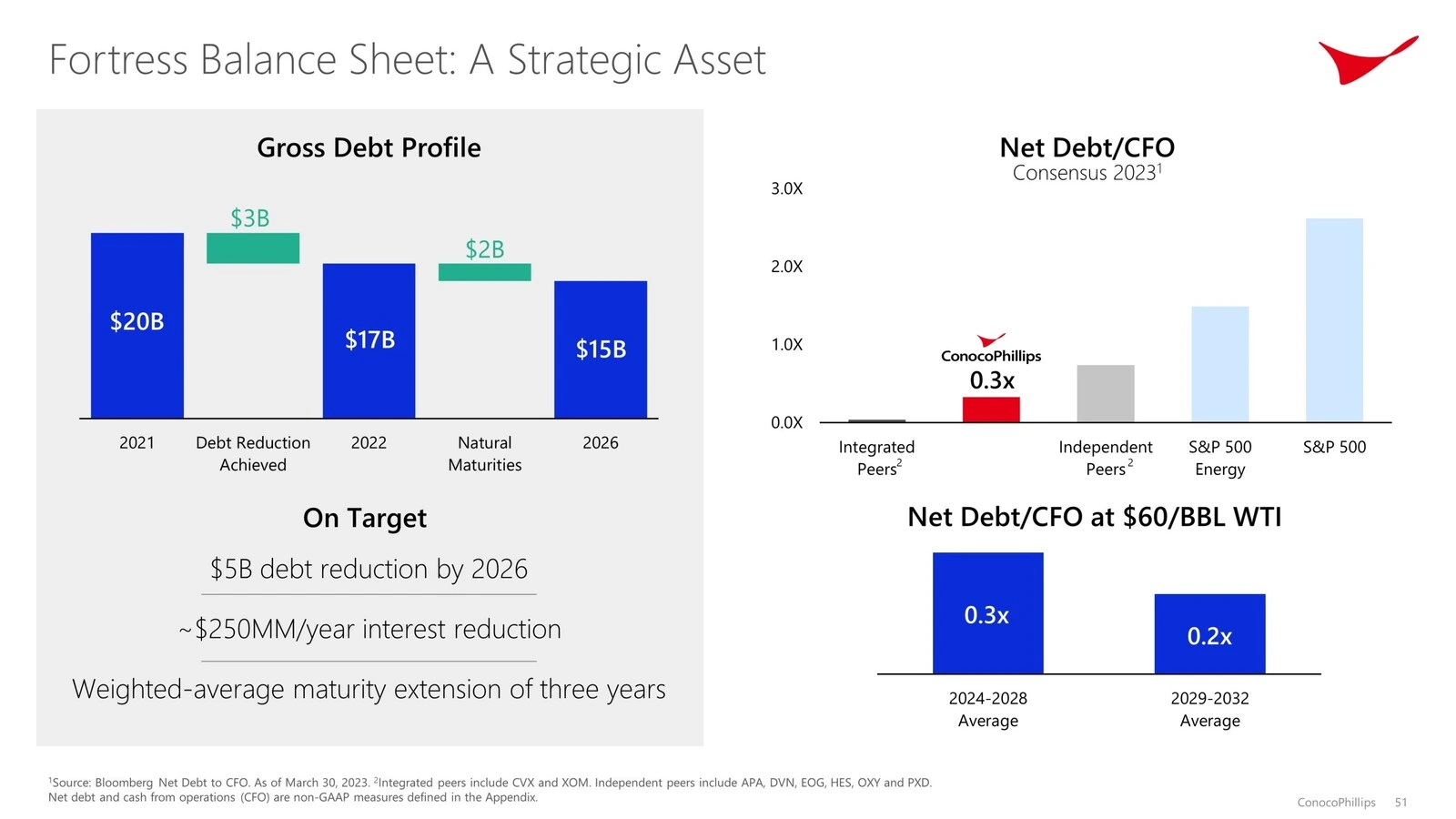
Conclusion
By combining LlamaIndex, LlamaParse, and OpenAI, you can build a multimodal report generator that processes an entire PDF (with text, tables, and images) into a structured output. This approach delivers richer, more visually informative results—exactly what stakeholders need to glean critical insights from complex corporate or technical documents.
Feel free to adapt this pipeline to your own documents, add a retrieval step for large archives, or integrate domain-specific models for analyzing the underlying images. With the foundations laid out here, you can create dynamic, interactive, and visually rich reports that go far beyond simple text-based queries.
A big thanks to Jerry Liu from LlamaIndex for developing this amazing pipeline.
Key Takeaways
- Transform PDFs with text and visuals into structured formats while preserving the integrity of original content using LlamaParse and LlamaIndex.
- Generate visually enriched reports that interweave textual summaries and images for better contextual understanding.
- Financial report generation can be enhanced by integrating both text and visual elements for more insightful and dynamic outputs.
- Leveraging LlamaIndex and LlamaParse streamlines the process of financial report generation, ensuring accurate and structured results.
- Retrieve relevant documents before processing to optimize report generation for large archives.
- Improve visual parsing, incorporate chart-specific analytics, and combine models for text and image processing for deeper insights.
Frequently Asked Questions
Q1. What is a “multimodal report generator”?A. A multimodal report generator is a system that produces reports containing multiple types of content—primarily text and images—in one cohesive output. In this pipeline, you parse a PDF into both textual and visual elements, then combine them into a single final report.
Q2. Why do I need to install llama-index-callbacks-arize-phoenix and set up observability?A. Observability tools like Arize Phoenix (via LlamaTrace) let you monitor and debug model behavior, track queries and responses, and identify issues in real time. It’s especially useful when dealing with large or complex documents and multiple LLM-based steps.
Q3. Why use LlamaParse instead of a standard PDF text extractor?A. Most PDF text extractors only handle raw text, often losing formatting, images, and tables. LlamaParse is capable of extracting both text and images (rendered page images), which is crucial for building multimodal pipelines where you need to refer back to tables, charts, or other visuals.
Q4. What is the advantage of using a SummaryIndex?A. SummaryIndex is a LlamaIndex abstraction that organizes your content (e.g., pages of a PDF) so it can quickly generate comprehensive summaries. It helps gather high-level insights from long documents without having to chunk them manually or run a retrieval query for each piece of data.
Q5. How do I ensure the final report includes at least one image block?A. In the ReportOutput Pydantic model, enforce that the blocks list requires at least one ImageBlock. This is stated in your system prompt and schema. The LLM must follow these rules, or it will not produce valid structured output.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
The above is the detailed content of Multimodal Financial Report Generation using Llamaindex. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 From Adoption To Advantage: 10 Trends Shaping Enterprise LLMs In 2025
Jun 20, 2025 am 11:13 AM
From Adoption To Advantage: 10 Trends Shaping Enterprise LLMs In 2025
Jun 20, 2025 am 11:13 AM
Here are ten compelling trends reshaping the enterprise AI landscape.Rising Financial Commitment to LLMsOrganizations are significantly increasing their investments in LLMs, with 72% expecting their spending to rise this year. Currently, nearly 40% a
 AI Investor Stuck At A Standstill? 3 Strategic Paths To Buy, Build, Or Partner With AI Vendors
Jul 02, 2025 am 11:13 AM
AI Investor Stuck At A Standstill? 3 Strategic Paths To Buy, Build, Or Partner With AI Vendors
Jul 02, 2025 am 11:13 AM
Investing is booming, but capital alone isn’t enough. With valuations rising and distinctiveness fading, investors in AI-focused venture funds must make a key decision: Buy, build, or partner to gain an edge? Here’s how to evaluate each option—and pr
 New Gallup Report: AI Culture Readiness Demands New Mindsets
Jun 19, 2025 am 11:16 AM
New Gallup Report: AI Culture Readiness Demands New Mindsets
Jun 19, 2025 am 11:16 AM
The gap between widespread adoption and emotional preparedness reveals something essential about how humans are engaging with their growing array of digital companions. We are entering a phase of coexistence where algorithms weave into our daily live
 The Unstoppable Growth Of Generative AI (AI Outlook Part 1)
Jun 21, 2025 am 11:11 AM
The Unstoppable Growth Of Generative AI (AI Outlook Part 1)
Jun 21, 2025 am 11:11 AM
Disclosure: My company, Tirias Research, has consulted for IBM, Nvidia, and other companies mentioned in this article.Growth driversThe surge in generative AI adoption was more dramatic than even the most optimistic projections could predict. Then, a
 These Startups Are Helping Businesses Show Up In AI Search Summaries
Jun 20, 2025 am 11:16 AM
These Startups Are Helping Businesses Show Up In AI Search Summaries
Jun 20, 2025 am 11:16 AM
Those days are numbered, thanks to AI. Search traffic for businesses like travel site Kayak and edtech company Chegg is declining, partly because 60% of searches on sites like Google aren’t resulting in users clicking any links, according to one stud
 AGI And AI Superintelligence Are Going To Sharply Hit The Human Ceiling Assumption Barrier
Jul 04, 2025 am 11:10 AM
AGI And AI Superintelligence Are Going To Sharply Hit The Human Ceiling Assumption Barrier
Jul 04, 2025 am 11:10 AM
Let’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI, including identifying and explaining various impactful AI complexities (see the link here). Heading Toward AGI And
 Cisco Charts Its Agentic AI Journey At Cisco Live U.S. 2025
Jun 19, 2025 am 11:10 AM
Cisco Charts Its Agentic AI Journey At Cisco Live U.S. 2025
Jun 19, 2025 am 11:10 AM
Let’s take a closer look at what I found most significant — and how Cisco might build upon its current efforts to further realize its ambitions.(Note: Cisco is an advisory client of my firm, Moor Insights & Strategy.)Focusing On Agentic AI And Cu
 Build Your First LLM Application: A Beginner's Tutorial
Jun 24, 2025 am 10:13 AM
Build Your First LLM Application: A Beginner's Tutorial
Jun 24, 2025 am 10:13 AM
Have you ever tried to build your own Large Language Model (LLM) application? Ever wondered how people are making their own LLM application to increase their productivity? LLM applications have proven to be useful in every aspect
