


Beginner of Astro Content Collection: Building a Powerful Content Model
This article is excerpted from the now-released book "Unlocking the Power of Astro" on SitePoint Premium. We will learn how to build flexible and scalable content models using Astro's content collection capabilities.

Astro uses special src/content folders to manage content collections. You can create subfolders to organize different collections of content, such as src/content/dev-blog and src/content/corporate-blog.
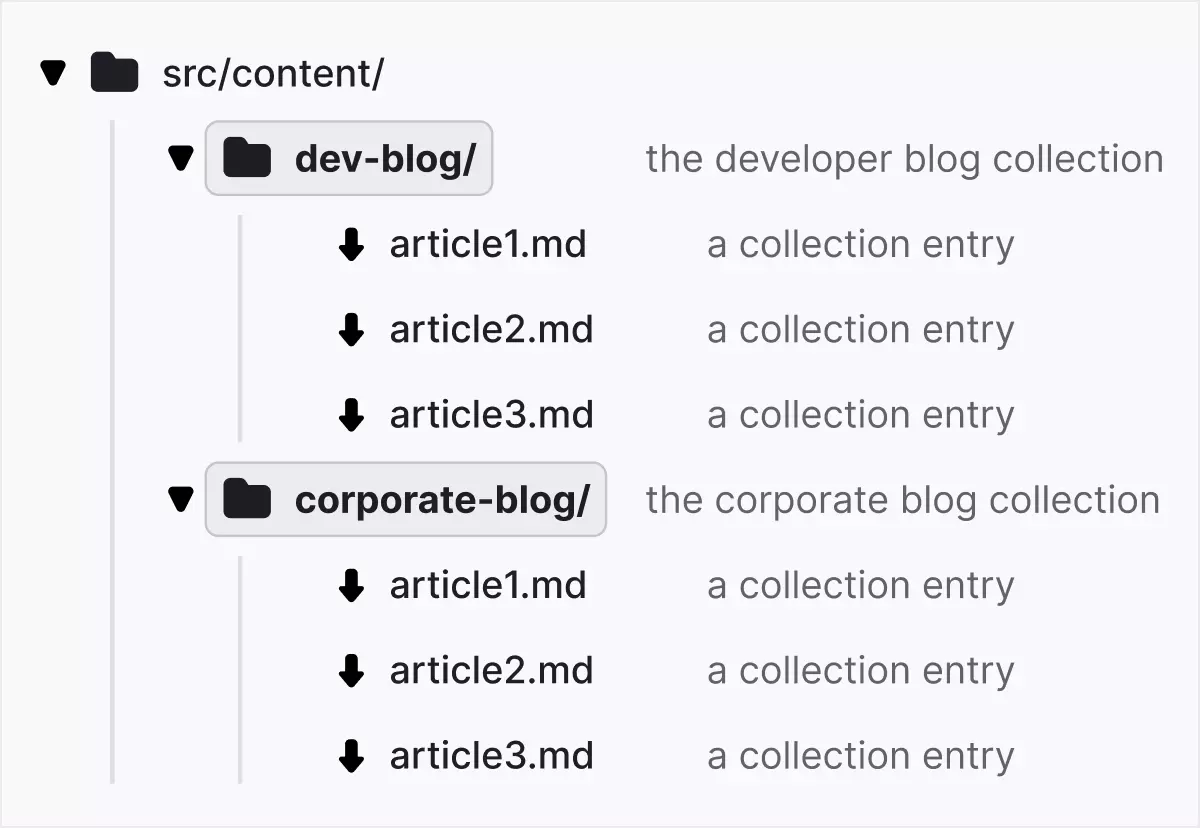
Each content collection can be configured in a configuration file (for example, /src/content/config.js or .ts) and uses Zod to define the collection pattern. Zod is a "TypeScript-based schema verification tool with static type inference" that has been integrated into Astro.
The following is a configuration example:
// src/content/config.js
import { z, defineCollection } from 'astro:content';
const devBlogCollection = defineCollection({
schema: z.object({
title: z.string(),
author: z.string().default('The Dev Team'),
tags: z.array(z.string()),
date: z.date(),
draft: z.boolean().default(true),
description: z.string(),
}),
});
const corporateBlogCollection = defineCollection({
schema: z.object({
title: z.string(),
author: z.string(),
date: z.date(),
featured: z.boolean(),
language: z.enum(['en', 'es']),
}),
});
export const collections = {
devblog: devBlogCollection,
corporateblog: corporateBlogCollection,
};
The code defines two content collections: "Developer Blog" and "Enterprise Blog". The defineCollection method allows you to create patterns for each collection.
Markdown files and front-end content
The example content collection in this tutorial assumes that the .md file contains front-end content that matches the pattern specified in the configuration file. For example, a "Company Blog" article might look like this:
--- title: 'Buy!!' author: 'Jack from Marketing' date: 2023-07-19 featured: true language: 'en' --- # Some Marketing Promo This is the best product!
Slug Generation
Astro will automatically generate slugs for articles based on file name. For example, the slug of first-post.md is first-post. If the slug field is provided in the front-end content, Astro will use a custom slug.
Note that the properties specified in the export const collections object must match (and be case sensitive) the folder name where the content is located.
Data query
When you prepare the Markdown file (located in src/content/devblog and src/content/corporateblog) and config.js files, you can start querying the data in the collection:
---
import { getCollection } from 'astro:content';
const allDevPosts = await getCollection('devblog');
const allCorporatePosts = await getCollection('corporateblog');
---
{JSON.stringify(allDevPosts)}
{JSON.stringify(allCorporatePosts)}
The getCollection method can be used to retrieve all entries in a given set. All articles in "Developer Blog" (devblog) and "Company Blog" (corporateblog) are retrieved in the example. Use JSON.stringify() in the template to return the original data.
In addition to front-end content data, the returned data also includes id, slug and body attributes (the body attributes contain article content).
You can also filter drafts or language-specific articles by iterating over all articles:
import { getCollection } from 'astro:content';
const spanishEntries = await getCollection('corporateblog', ({ data }) => {
return data.language === 'es';
});
getCollection Returns all posts, but you can also use getEntry to return a single entry in the collection:
import { getEntry } from 'astro:content';
const singleEntry = await getEntry('corporateblog', 'pr-article-1');
getCollection vs getEntries
While there are two ways to return multiple articles from a collection, there are slight differences between the two. getCollection() Retrieves a list of content collection entries based on the collection name, while getEntries() retrieves multiple collection entries from the same collection.
Examples of getEntries() for retrieving content are given in the
Content display
render()Now we know how to query data, let's discuss how to display data in a formatted way. Astro provides a convenient method called <content></content> for rendering the entire content of Markdown into the built-in Astro component
getStaticPaths()For pre-rendering, you can use
// src/content/config.js
import { z, defineCollection } from 'astro:content';
const devBlogCollection = defineCollection({
schema: z.object({
title: z.string(),
author: z.string().default('The Dev Team'),
tags: z.array(z.string()),
date: z.date(),
draft: z.boolean().default(true),
description: z.string(),
}),
});
const corporateBlogCollection = defineCollection({
schema: z.object({
title: z.string(),
author: z.string(),
date: z.date(),
featured: z.boolean(),
language: z.enum(['en', 'es']),
}),
});
export const collections = {
devblog: devBlogCollection,
corporateblog: corporateBlogCollection,
};
getStaticPaths() is used in the Astro.props code. Then rely on id to capture the entry, which will be an object containing the metadata, slug, render(), and <content></content> methods about the entry. This method is responsible for rendering the Markdown entry to HTML in the Astro template, which is implemented by creating a <content></content> component. Amazingly, now you just need to add the
The above is the detailed content of Getting Started with Content Collections in Astro. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to work with dates and times in js?
Jul 01, 2025 am 01:27 AM
How to work with dates and times in js?
Jul 01, 2025 am 01:27 AM
The following points should be noted when processing dates and time in JavaScript: 1. There are many ways to create Date objects. It is recommended to use ISO format strings to ensure compatibility; 2. Get and set time information can be obtained and set methods, and note that the month starts from 0; 3. Manually formatting dates requires strings, and third-party libraries can also be used; 4. It is recommended to use libraries that support time zones, such as Luxon. Mastering these key points can effectively avoid common mistakes.
 Why should you place tags at the bottom of the ?
Jul 02, 2025 am 01:22 AM
Why should you place tags at the bottom of the ?
Jul 02, 2025 am 01:22 AM
PlacingtagsatthebottomofablogpostorwebpageservespracticalpurposesforSEO,userexperience,anddesign.1.IthelpswithSEObyallowingsearchenginestoaccesskeyword-relevanttagswithoutclutteringthemaincontent.2.Itimprovesuserexperiencebykeepingthefocusonthearticl
 What is event bubbling and capturing in the DOM?
Jul 02, 2025 am 01:19 AM
What is event bubbling and capturing in the DOM?
Jul 02, 2025 am 01:19 AM
Event capture and bubble are two stages of event propagation in DOM. Capture is from the top layer to the target element, and bubble is from the target element to the top layer. 1. Event capture is implemented by setting the useCapture parameter of addEventListener to true; 2. Event bubble is the default behavior, useCapture is set to false or omitted; 3. Event propagation can be used to prevent event propagation; 4. Event bubbling supports event delegation to improve dynamic content processing efficiency; 5. Capture can be used to intercept events in advance, such as logging or error processing. Understanding these two phases helps to accurately control the timing and how JavaScript responds to user operations.
 How can you reduce the payload size of a JavaScript application?
Jun 26, 2025 am 12:54 AM
How can you reduce the payload size of a JavaScript application?
Jun 26, 2025 am 12:54 AM
If JavaScript applications load slowly and have poor performance, the problem is that the payload is too large. Solutions include: 1. Use code splitting (CodeSplitting), split the large bundle into multiple small files through React.lazy() or build tools, and load it as needed to reduce the first download; 2. Remove unused code (TreeShaking), use the ES6 module mechanism to clear "dead code" to ensure that the introduced libraries support this feature; 3. Compress and merge resource files, enable Gzip/Brotli and Terser to compress JS, reasonably merge files and optimize static resources; 4. Replace heavy-duty dependencies and choose lightweight libraries such as day.js and fetch
 A definitive JS roundup on JavaScript modules: ES Modules vs CommonJS
Jul 02, 2025 am 01:28 AM
A definitive JS roundup on JavaScript modules: ES Modules vs CommonJS
Jul 02, 2025 am 01:28 AM
The main difference between ES module and CommonJS is the loading method and usage scenario. 1.CommonJS is synchronously loaded, suitable for Node.js server-side environment; 2.ES module is asynchronously loaded, suitable for network environments such as browsers; 3. Syntax, ES module uses import/export and must be located in the top-level scope, while CommonJS uses require/module.exports, which can be called dynamically at runtime; 4.CommonJS is widely used in old versions of Node.js and libraries that rely on it such as Express, while ES modules are suitable for modern front-end frameworks and Node.jsv14; 5. Although it can be mixed, it can easily cause problems.
 How to make an HTTP request in Node.js?
Jul 13, 2025 am 02:18 AM
How to make an HTTP request in Node.js?
Jul 13, 2025 am 02:18 AM
There are three common ways to initiate HTTP requests in Node.js: use built-in modules, axios, and node-fetch. 1. Use the built-in http/https module without dependencies, which is suitable for basic scenarios, but requires manual processing of data stitching and error monitoring, such as using https.get() to obtain data or send POST requests through .write(); 2.axios is a third-party library based on Promise. It has concise syntax and powerful functions, supports async/await, automatic JSON conversion, interceptor, etc. It is recommended to simplify asynchronous request operations; 3.node-fetch provides a style similar to browser fetch, based on Promise and simple syntax
 What are best practices for writing clean and maintainable JavaScript code?
Jun 23, 2025 am 12:35 AM
What are best practices for writing clean and maintainable JavaScript code?
Jun 23, 2025 am 12:35 AM
To write clean and maintainable JavaScript code, the following four points should be followed: 1. Use clear and consistent naming specifications, variable names are used with nouns such as count, function names are started with verbs such as fetchData(), and class names are used with PascalCase such as UserProfile; 2. Avoid excessively long functions and side effects, each function only does one thing, such as splitting update user information into formatUser, saveUser and renderUser; 3. Use modularity and componentization reasonably, such as splitting the page into UserProfile, UserStats and other widgets in React; 4. Write comments and documents until the time, focusing on explaining the key logic and algorithm selection
 How does garbage collection work in JavaScript?
Jul 04, 2025 am 12:42 AM
How does garbage collection work in JavaScript?
Jul 04, 2025 am 12:42 AM
JavaScript's garbage collection mechanism automatically manages memory through a tag-clearing algorithm to reduce the risk of memory leakage. The engine traverses and marks the active object from the root object, and unmarked is treated as garbage and cleared. For example, when the object is no longer referenced (such as setting the variable to null), it will be released in the next round of recycling. Common causes of memory leaks include: ① Uncleared timers or event listeners; ② References to external variables in closures; ③ Global variables continue to hold a large amount of data. The V8 engine optimizes recycling efficiency through strategies such as generational recycling, incremental marking, parallel/concurrent recycling, and reduces the main thread blocking time. During development, unnecessary global references should be avoided and object associations should be promptly decorated to improve performance and stability.
