


GraphQL is a query language for getting deeply nested structured data from a website's backend, similar to MongoDB queries.
The request is usually a POST to some general /graphql endpoint with a body like this:

However, with large data structures, this becomes inefficient - you are sending a large query in a POST request body, which is (almost always) the same and only changes on website updates; POST requests can’t be cached, etc. Therefore, an extension called “persisted queries” was developed. This isn’t an anti-scraping secret; you can read the public documentation about it here.
TLDR: the client computes the sha256 hash of the query text and only sends that hash. In addition, you can possibly fit all of this into the query string of a GET request, making it easily cachable. Below is an example request from Zillow

As you can see, it’s just some metadata about the persistedQuery extension, the hash of the query, and variables to be embedded in the query.
Here’s another request from expedia.com, sent as a POST, but with the same extension:

This primarily optimizes website performance, but it creates several challenges for web scraping:
- GET requests are usually more prone to being blocked.
- Hidden Query Parameters: We don’t know the full query, so if the website responds with a “Persisted query not found” error (asking us to send the query in full, not just the hash), we can’t send it.
- Once the website changes even a little bit and the clients start asking for a new query - even though the old one might still work, the server will very soon forget its ID/hash, and your request with this hash will never work again, since you can’t “remind” the server of the full query text.
Therefore, for different reasons, you might find yourself in the need to extract the whole query text. You could dig through the website JavaScript, and if you’re lucky, you might find the query text there in full, but often, it is somehow dynamically constructed from multiple fragments, etc.
Therefore, we figured out a better way: we will not touch the client-side JavaScript at all. Instead, we will try to simulate the situation where the client tries to use a hash that the server does not know. Therefore, we need to intercept the (valid) request sent by the browser in-flight and modify the hash to a bogus one before passing it to the server.
For exactly this use case, a perfect tool exists: mitmproxy, an open-source Python library that intercepts requests made by your own devices, websites, or apps and allows you to modify them with simple Python scripts.
Download mitmproxy, and prepare a Python script like this:
import json
def request(flow):
try:
dat = json.loads(flow.request.text)
dat[0]["extensions"]["persistedQuery"]["sha256Hash"] = "0d9e" # any bogus hex string here
flow.request.text = json.dumps(dat)
except:
pass
This defines a hook that mitmproxy will run on every request: it tries to load the request's JSON body, modifies the hash to an arbitrary value, and writes the updated JSON as a new body of the request.
We also need to make sure we reroute our browser requests to mitmproxy. For this purpose we are going to use a browser extension called FoxyProxy. It is available in both Firefox and Chrome.
Just add a route with these settings:

Now we can run mitmproxy with this script: mitmweb -s script.py
This will open a browser tab where you can watch all the intercepted requests in real-time.

If you go to the particular path and see the query in the request section, you will see some garbage value has replaced the hash.
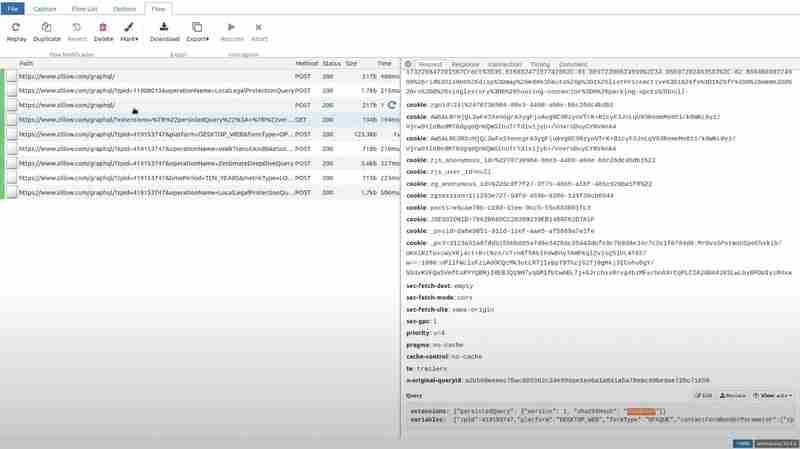
Now, if you visit Zillow and open that particular path that we tried for the extension, and go to the response section, the client-side receives the PersistedQueryNotFound error.

The front end of Zillow reacts with sending the whole query as a POST request.

We extract the query and hash directly from this POST request. To ensure that the Zillow server does not forget about this hash, we periodically run this POST request with the exact same query and hash. This will ensure that the scraper continues to work even when the server's cache is cleaned or reset or the website changes.
Conclusion
Persisted queries are a powerful optimization tool for GraphQL APIs, enhancing website performance by minimizing payload sizes and enabling GET request caching. However, they also pose significant challenges for web scraping, primarily due to the reliance on server-stored hashes and the potential for those hashes to become invalid.
Using mitmproxy to intercept and manipulate GraphQL requests gives an efficient approach to reveal the full query text without delving into complex client-side JavaScript. By forcing the server to respond with a PersistedQueryNotFound error, we can capture the full query payload and utilize it for scraping purposes. Periodically running the extracted query ensures the scraper remains functional, even when server-side cache resets occur or the website evolves.
The above is the detailed content of Reverse engineering GraphQL persistedQuery extension. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Java vs. JavaScript: Clearing Up the Confusion
Jun 20, 2025 am 12:27 AM
Java vs. JavaScript: Clearing Up the Confusion
Jun 20, 2025 am 12:27 AM
Java and JavaScript are different programming languages, each suitable for different application scenarios. Java is used for large enterprise and mobile application development, while JavaScript is mainly used for web page development.
 Javascript Comments: short explanation
Jun 19, 2025 am 12:40 AM
Javascript Comments: short explanation
Jun 19, 2025 am 12:40 AM
JavaScriptcommentsareessentialformaintaining,reading,andguidingcodeexecution.1)Single-linecommentsareusedforquickexplanations.2)Multi-linecommentsexplaincomplexlogicorprovidedetaileddocumentation.3)Inlinecommentsclarifyspecificpartsofcode.Bestpractic
 How to work with dates and times in js?
Jul 01, 2025 am 01:27 AM
How to work with dates and times in js?
Jul 01, 2025 am 01:27 AM
The following points should be noted when processing dates and time in JavaScript: 1. There are many ways to create Date objects. It is recommended to use ISO format strings to ensure compatibility; 2. Get and set time information can be obtained and set methods, and note that the month starts from 0; 3. Manually formatting dates requires strings, and third-party libraries can also be used; 4. It is recommended to use libraries that support time zones, such as Luxon. Mastering these key points can effectively avoid common mistakes.
 Why should you place tags at the bottom of the ?
Jul 02, 2025 am 01:22 AM
Why should you place tags at the bottom of the ?
Jul 02, 2025 am 01:22 AM
PlacingtagsatthebottomofablogpostorwebpageservespracticalpurposesforSEO,userexperience,anddesign.1.IthelpswithSEObyallowingsearchenginestoaccesskeyword-relevanttagswithoutclutteringthemaincontent.2.Itimprovesuserexperiencebykeepingthefocusonthearticl
 JavaScript vs. Java: A Comprehensive Comparison for Developers
Jun 20, 2025 am 12:21 AM
JavaScript vs. Java: A Comprehensive Comparison for Developers
Jun 20, 2025 am 12:21 AM
JavaScriptispreferredforwebdevelopment,whileJavaisbetterforlarge-scalebackendsystemsandAndroidapps.1)JavaScriptexcelsincreatinginteractivewebexperienceswithitsdynamicnatureandDOMmanipulation.2)Javaoffersstrongtypingandobject-orientedfeatures,idealfor
 JavaScript: Exploring Data Types for Efficient Coding
Jun 20, 2025 am 12:46 AM
JavaScript: Exploring Data Types for Efficient Coding
Jun 20, 2025 am 12:46 AM
JavaScripthassevenfundamentaldatatypes:number,string,boolean,undefined,null,object,andsymbol.1)Numbersuseadouble-precisionformat,usefulforwidevaluerangesbutbecautiouswithfloating-pointarithmetic.2)Stringsareimmutable,useefficientconcatenationmethodsf
 What is event bubbling and capturing in the DOM?
Jul 02, 2025 am 01:19 AM
What is event bubbling and capturing in the DOM?
Jul 02, 2025 am 01:19 AM
Event capture and bubble are two stages of event propagation in DOM. Capture is from the top layer to the target element, and bubble is from the target element to the top layer. 1. Event capture is implemented by setting the useCapture parameter of addEventListener to true; 2. Event bubble is the default behavior, useCapture is set to false or omitted; 3. Event propagation can be used to prevent event propagation; 4. Event bubbling supports event delegation to improve dynamic content processing efficiency; 5. Capture can be used to intercept events in advance, such as logging or error processing. Understanding these two phases helps to accurately control the timing and how JavaScript responds to user operations.
 How can you reduce the payload size of a JavaScript application?
Jun 26, 2025 am 12:54 AM
How can you reduce the payload size of a JavaScript application?
Jun 26, 2025 am 12:54 AM
If JavaScript applications load slowly and have poor performance, the problem is that the payload is too large. Solutions include: 1. Use code splitting (CodeSplitting), split the large bundle into multiple small files through React.lazy() or build tools, and load it as needed to reduce the first download; 2. Remove unused code (TreeShaking), use the ES6 module mechanism to clear "dead code" to ensure that the introduced libraries support this feature; 3. Compress and merge resource files, enable Gzip/Brotli and Terser to compress JS, reasonably merge files and optimize static resources; 4. Replace heavy-duty dependencies and choose lightweight libraries such as day.js and fetch
