


Error Metrics for Regression Algorithms
When we create a regression algorithm and want to know how efficient this model was, we use error metrics to obtain values ??that represent the error of our machine learning model. The metrics in this article are important when we want to measure the error of prediction models for numerical values ??(real, integers).
In this article we will cover the main error metrics for regression algorithms, performing the calculations manually in Python and measuring the error of the machine learning model on a dollar quote dataset.
Metrics Addressed
- SE — Sum of error
- ME — Mean error
- MAE — Mean Absolute error
- MPE — Mean Percentage error
- MAPAE — Mean Absolute Percentage error
Both metrics are a little similar, where we have metrics for average and percentage of error and metrics for average and absolute percentage of error, differentiated so only that one group obtains the real value of the difference and the other obtains the absolute value of the difference. difference. It is important to remember that in both metrics, the lower the value, the better our forecast.
SE — Sum of error
The SE metric is the simplest among all in this article, where its formula is:
SE = εR — P
Therefore, it is the sum of the difference between the real value (target variable of the model) and the predicted value. This metric has some negative points, such as not treating values ??as absolute, which will consequently result in a false value.
ME — Mean of error
The ME metric is a "complement" of the SE, where we basically have the difference that we will obtain an average of the SE given the number of elements:
ME = ε(R-P)/N
Unlike SE, we just divide the SE result by the number of elements. This metric, like SE, depends on scale, that is, we must use the same set of data and can compare with different forecasting models.
MAE — Mean absolute error

The MAE metric is the ME but considering only absolute (non-negative) values. When we are calculating the difference between actual and predicted, we may have negative results and this negative difference is applied to previous metrics. In this metric, we have to transform the difference into positive values ??and then take the average based on the number of elements.
MPE — Mean Percentage error
The MPE metric is the average error as a percentage of the sum of each difference. Here we have to take the percentage of the difference, add it and then divide it by the number of elements to obtain the average. Therefore, the difference between the actual value and the predicted value is made, divided by the actual value, multiplied by 100, we add up all this percentage and divide by the number of elements. This metric is independent of scale (%).
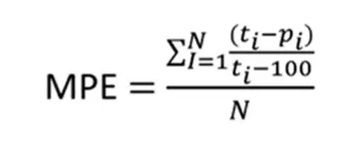
MAPAE — Mean Absolute Percentage error
The MAPAE metric is very similar to the previous metric, but the difference between the predicted x actual is made absolutely, that is, you calculate it with positive values. Therefore, this metric is the absolute difference in the percentage of error. This metric is also scale independent.

Using metrics in practice
Given an explanation of each metric, we will calculate both manually in Python based on a prediction from a dollar exchange rate machine learning model. Currently, most of the regression metrics exist in ready-made functions in the Sklearn package, however here we will calculate them manually for teaching purposes only.

We will use the RandomForest and Decision Tree algorithms only to compare results between the two models.
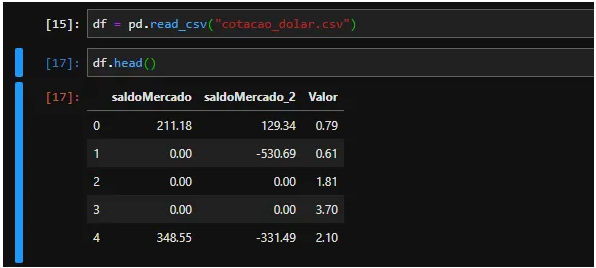
Data Analysis
In our dataset, we have a column of SaldoMercado and saldoMercado_2 which are information that influence the Value column (our dollar quote). As we can see, the MercadoMercado balance has a closer relationship to the quote than theMerado_2 balance. It is also possible to observe that we do not have missing values ??(infinite or Nan values) and that the balanceMercado_2 column has many non-absolute values.
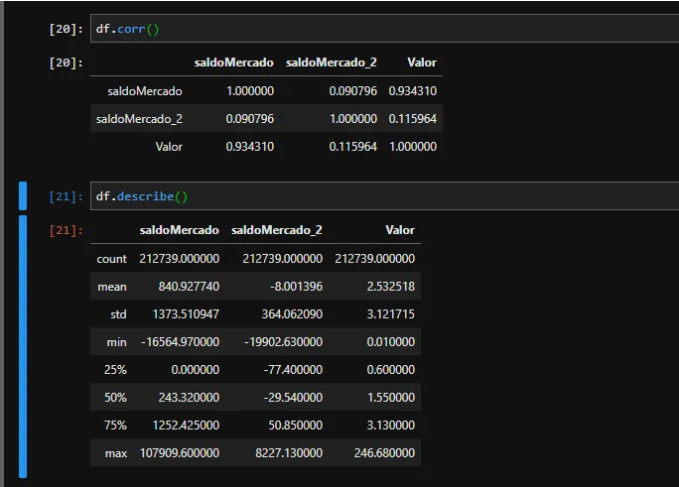

Model Preparation
We prepare our values ??for the machine learning model by defining the predictor variables and the variable we want to predict. We use train_test_split to randomly divide the data into 30% for testing and 70% for training.
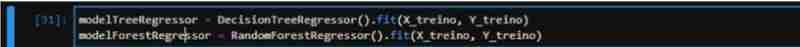

Finally, we initialize both algorithms (RandomForest and DecisionTree), fit the data and measure the score of both with the test data. We obtained a score of 83% for TreeRegressor and 90% for ForestRegressor, which in theory indicates that ForestRegressor performed better.
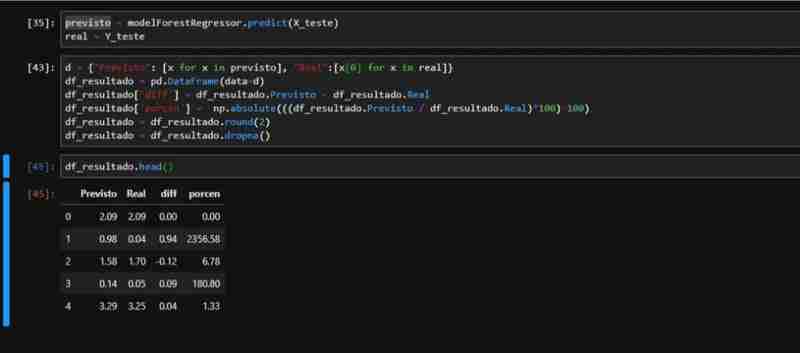
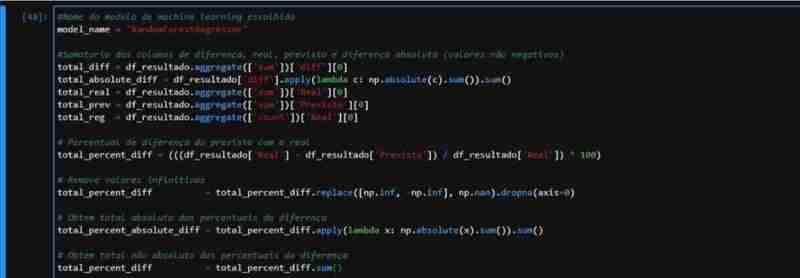
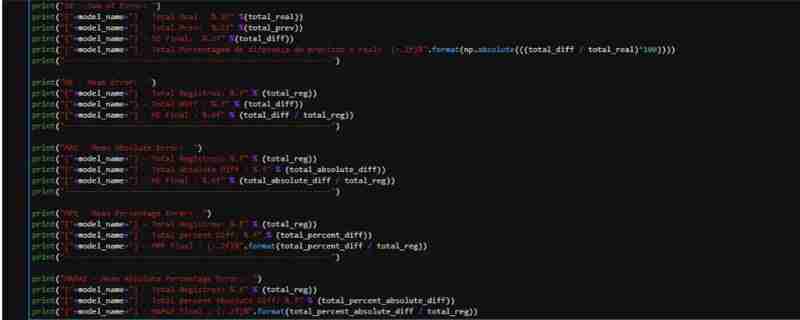
Results and Analysis
Given the partially observed performance of ForestRegressor, we created a dataset with the necessary data to apply the metrics. We perform the prediction on the test data and create a DataFrame with the actual and predicted values, including columns for difference and percentage.

We can observe that in relation to the real total of the dollar rate vs the rate that our model predicted:
- We had a total difference of R$578.00
- This represents 0.36% difference between predicted x Actual (not considered absolute values)
- In terms of the average error (ME) we had a low value, an average of R$0.009058
- For absolute average, this value increases a little, since we have negative values ??in our dataset
I reinforce that here we perform the calculation manually for teaching purposes. However, it is recommended to use the metrics functions from the Sklearn package due to better performance and low chance of error in the calculation.
The complete code is available on my GitHub: github.com/AirtonLira/artigo_metricasregressao
Author: Airton Lira Junior
LinkedIn: linkedin.com/in/airton-lira-junior-6b81a661/
The above is the detailed content of Metrics for regression algorithms. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Polymorphism in python classes
Jul 05, 2025 am 02:58 AM
Polymorphism in python classes
Jul 05, 2025 am 02:58 AM
Polymorphism is a core concept in Python object-oriented programming, referring to "one interface, multiple implementations", allowing for unified processing of different types of objects. 1. Polymorphism is implemented through method rewriting. Subclasses can redefine parent class methods. For example, the spoke() method of Animal class has different implementations in Dog and Cat subclasses. 2. The practical uses of polymorphism include simplifying the code structure and enhancing scalability, such as calling the draw() method uniformly in the graphical drawing program, or handling the common behavior of different characters in game development. 3. Python implementation polymorphism needs to satisfy: the parent class defines a method, and the child class overrides the method, but does not require inheritance of the same parent class. As long as the object implements the same method, this is called the "duck type". 4. Things to note include the maintenance
 How do I write a simple 'Hello, World!' program in Python?
Jun 24, 2025 am 12:45 AM
How do I write a simple 'Hello, World!' program in Python?
Jun 24, 2025 am 12:45 AM
The "Hello,World!" program is the most basic example written in Python, which is used to demonstrate the basic syntax and verify that the development environment is configured correctly. 1. It is implemented through a line of code print("Hello,World!"), and after running, the specified text will be output on the console; 2. The running steps include installing Python, writing code with a text editor, saving as a .py file, and executing the file in the terminal; 3. Common errors include missing brackets or quotes, misuse of capital Print, not saving as .py format, and running environment errors; 4. Optional tools include local text editor terminal, online editor (such as replit.com)
 How do I generate random strings in Python?
Jun 21, 2025 am 01:02 AM
How do I generate random strings in Python?
Jun 21, 2025 am 01:02 AM
To generate a random string, you can use Python's random and string module combination. The specific steps are: 1. Import random and string modules; 2. Define character pools such as string.ascii_letters and string.digits; 3. Set the required length; 4. Call random.choices() to generate strings. For example, the code includes importrandom and importstring, set length=10, characters=string.ascii_letters string.digits and execute ''.join(random.c
 What are algorithms in Python, and why are they important?
Jun 24, 2025 am 12:43 AM
What are algorithms in Python, and why are they important?
Jun 24, 2025 am 12:43 AM
AlgorithmsinPythonareessentialforefficientproblem-solvinginprogramming.Theyarestep-by-stepproceduresusedtosolvetaskslikesorting,searching,anddatamanipulation.Commontypesincludesortingalgorithmslikequicksort,searchingalgorithmslikebinarysearch,andgrap
 What is list slicing in python?
Jun 29, 2025 am 02:15 AM
What is list slicing in python?
Jun 29, 2025 am 02:15 AM
ListslicinginPythonextractsaportionofalistusingindices.1.Itusesthesyntaxlist[start:end:step],wherestartisinclusive,endisexclusive,andstepdefinestheinterval.2.Ifstartorendareomitted,Pythondefaultstothebeginningorendofthelist.3.Commonusesincludegetting
 Python `@classmethod` decorator explained
Jul 04, 2025 am 03:26 AM
Python `@classmethod` decorator explained
Jul 04, 2025 am 03:26 AM
A class method is a method defined in Python through the @classmethod decorator. Its first parameter is the class itself (cls), which is used to access or modify the class state. It can be called through a class or instance, which affects the entire class rather than a specific instance; for example, in the Person class, the show_count() method counts the number of objects created; when defining a class method, you need to use the @classmethod decorator and name the first parameter cls, such as the change_var(new_value) method to modify class variables; the class method is different from the instance method (self parameter) and static method (no automatic parameters), and is suitable for factory methods, alternative constructors, and management of class variables. Common uses include:
 How do I use the csv module for working with CSV files in Python?
Jun 25, 2025 am 01:03 AM
How do I use the csv module for working with CSV files in Python?
Jun 25, 2025 am 01:03 AM
Python's csv module provides an easy way to read and write CSV files. 1. When reading a CSV file, you can use csv.reader() to read line by line and return each line of data as a string list; if you need to access the data through column names, you can use csv.DictReader() to map each line into a dictionary. 2. When writing to a CSV file, use csv.writer() and call writerow() or writerows() methods to write single or multiple rows of data; if you want to write dictionary data, use csv.DictWriter(), you need to define the column name first and write the header through writeheader(). 3. When handling edge cases, the module automatically handles them
 Python Function Arguments and Parameters
Jul 04, 2025 am 03:26 AM
Python Function Arguments and Parameters
Jul 04, 2025 am 03:26 AM
Parameters are placeholders when defining a function, while arguments are specific values ??passed in when calling. 1. Position parameters need to be passed in order, and incorrect order will lead to errors in the result; 2. Keyword parameters are specified by parameter names, which can change the order and improve readability; 3. Default parameter values ??are assigned when defined to avoid duplicate code, but variable objects should be avoided as default values; 4. args and *kwargs can handle uncertain number of parameters and are suitable for general interfaces or decorators, but should be used with caution to maintain readability.
