
 Technologie-Peripherieger?te
KI
Beschleunigen Sie das Diffusionsmodell und generieren Sie Bilder auf SOTA-Ebene im schnellsten Schritt. Byte Hyper-SD ist Open Source
Technologie-Peripherieger?te
KI
Beschleunigen Sie das Diffusionsmodell und generieren Sie Bilder auf SOTA-Ebene im schnellsten Schritt. Byte Hyper-SD ist Open Source
Beschleunigen Sie das Diffusionsmodell und generieren Sie Bilder auf SOTA-Ebene im schnellsten Schritt. Byte Hyper-SD ist Open Source
Apr 25, 2024 pm 05:25 PM
Vor kurzem hat das Diffusionsmodell erhebliche Fortschritte im Bereich der Bildgenerierung gemacht und beispiellose Entwicklungsm?glichkeiten für Bildgenerierungs- und Videogenerierungsaufgaben er?ffnet. Trotz der beeindruckenden Ergebnisse führen die mehrstufigen iterativen Entrauschungseigenschaften, die dem Inferenzprozess von Diffusionsmodellen innewohnen, zu hohen Rechenkosten. Kürzlich wurde eine Reihe von Diffusionsmodell-Destillationsalgorithmen entwickelt, um den Inferenzprozess von Diffusionsmodellen zu beschleunigen. Diese Methoden lassen sich grob in zwei Kategorien einteilen: i) bahnerhaltende Destillation; ii) bahnenerhaltende Destillation. Diese beiden Arten von Methoden werden jedoch durch die begrenzte Effektobergrenze oder ?nderungen im Ausgabebereich eingeschr?nkt.
Um diese Probleme zu l?sen, schlug das technische Team von ByteDance ein Konsistenzmodell für die Trajektoriensegmentierung namens Hyper-SD vor. Die Open Source von Hyper-SD wurde auch von Clem Delangue, CEO von Huggingface, gewürdigt.
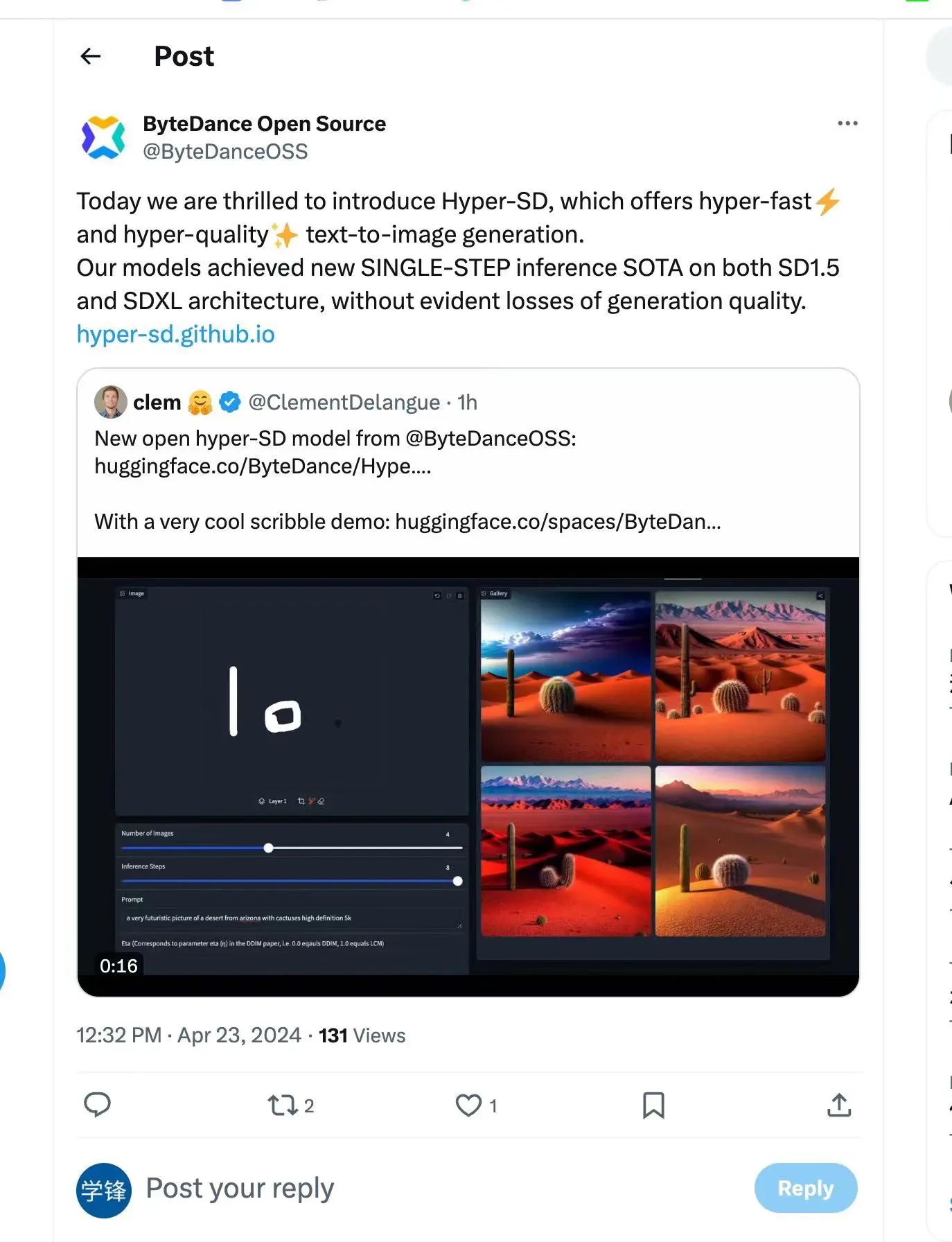
Bei diesem Modell handelt es sich um ein neuartiges Diffusionsmodell-Destillationsframework, das die Vorteile der Trajektorien-erhaltenden Destillation und der Trajektorien-Rekonstruktionsdestillation kombiniert, um die Anzahl der Entrauschungsschritte zu komprimieren und gleichzeitig eine nahezu verlustfreie Leistung aufrechtzuerhalten. Im Vergleich zu bestehenden Diffusionsmodell-Beschleunigungsalgorithmen erzielt diese Methode hervorragende Beschleunigungsergebnisse. Nach umfangreichen Experimenten und Benutzerbewertungen kann Hyper-SD+ sowohl auf SDXL- als auch auf SD1.5-Architekturen eine Bildgenerierungsleistung auf SOTA-Niveau in 1 bis 8 Schritten erreichen.

Projekthomepage: https://hyper-sd.github.io/
Papierlink: https://arxiv.org/abs/2404.13686
Huggingface-Link: https:/ // /huggingface.co/ByteDance/Hyper-SD
Demo-Link zur Einzelschrittgenerierung: https://huggingface.co/spaces/ByteDance/Hyper-SDXL-1Step-T2I
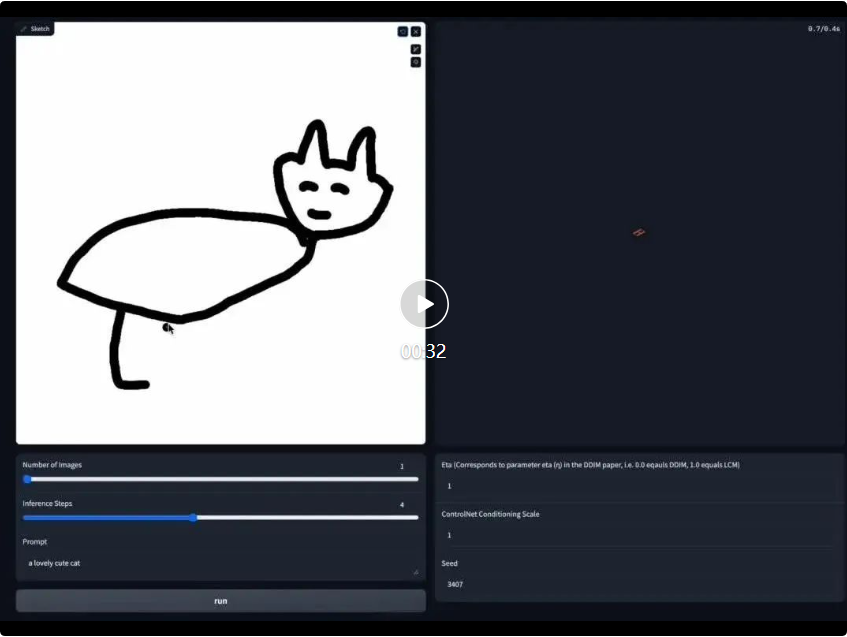
Echtzeitzeichnen Board-Demo-Link: https://huggingface.co/spaces/ByteDance/Hyper-SD15-Scribble

Bestehende Destillationsmethoden zur Diffusionsmodellbeschleunigung k?nnen grob in zwei Kategorien unterteilt werden: Flugbahnerhaltende Destillation und Flugbahnrekonstruktionsdestillation. Die bahnerhaltende Destillationstechnik zielt darauf ab, die ursprüngliche Bahn der gew?hnlichen Differentialgleichung (ODE) entsprechend der Diffusion beizubehalten. Das Prinzip besteht darin, Inferenzschritte zu reduzieren, indem das destillierte Modell und das Originalmodell gezwungen werden, ?hnliche Ergebnisse zu erzeugen. Es ist jedoch zu beachten, dass zwar eine Beschleunigung erreicht werden kann, solche Methoden jedoch aufgrund der begrenzten Modellkapazit?t und unvermeidlicher Fehler beim Training und Anpassen zu einer Verschlechterung der Generierungsqualit?t führen k?nnen. Im Gegensatz dazu verwenden Trajektorienrekonstruktionsmethoden direkt die Endpunkte auf der Trajektorie oder reale Bilder als Hauptquelle der überwachung und ignorieren die Zwischenschritte der Trajektorie. Sie k?nnen die Anzahl der Inferenzschritte reduzieren, indem sie effektivere Trajektorien rekonstruieren und diese innerhalb einer begrenzten Zeitspanne durchführen Erkunden Sie innerhalb von Schritten das Potenzial Ihres Modells und befreien Sie es von den Einschr?nkungen der ursprünglichen Flugbahn. Dies führt jedoch h?ufig dazu, dass der Ausgabebereich des beschleunigten Modells nicht mit dem Originalmodell übereinstimmt, was zu suboptimalen Ergebnissen führt.
In diesem Artikel wird ein Trajektoriensegmentierungskonsistenzmodell (kurz Hyper-SD) vorgeschlagen, das die Vorteile von Trajektorienerhaltungs- und Rekonstruktionsstrategien kombiniert. Konkret führt der Algorithmus zun?chst die Konsistenzdestillation der Trajektoriensegmentierung ein, um die Konsistenz innerhalb jedes Segments zu erzwingen, und reduziert schrittweise die Anzahl der Segmente, um eine Vollzeitkonsistenz zu erreichen. Diese Strategie l?st das Problem der suboptimalen Leistung konsistenter Modelle aufgrund unzureichender Modellanpassungsf?higkeiten und der Anh?ufung von Inferenzfehlern. Anschlie?end verwendet der Algorithmus menschliches Feedback-Lernen (RLHF), um den Modellgenerierungseffekt zu verbessern, um den Verlust des Modellgenerierungseffekts w?hrend des Beschleunigungsprozesses auszugleichen und ihn besser an Low-Step-Argumentation anzupassen. Schlie?lich verwendet der Algorithmus eine fraktionierte Destillation, um die Leistung der einstufigen Erzeugung zu verbessern, und erreicht durch einheitliches LORA ein idealisiertes, konsistentes Vollzeitschritt-Diffusionsmodell, wodurch hervorragende Ergebnisse bei den Erzeugungseffekten erzielt werden.
Methode
1. Trajektoriensegmentierung, Konsistenzdestillation
Consistent Distillation (CD) [24] und Consistent Trajectory Model (CTM) [4] zielen beide darauf ab, das Diffusionsmodell durch One-Shot-Destillation in ein konsistentes Modell für den gesamten Zeitschrittbereich [0, T] umzuwandeln. Diese Destillationsmodelle erreichen jedoch h?ufig nicht die optimale Leistung, da die M?glichkeiten zur Modellanpassung eingeschr?nkt sind. Inspiriert durch das in CTM eingeführte Ziel der weichen Konsistenz verfeinern wir den Trainingsprozess, indem wir den gesamten Zeitschrittbereich [0, T] in k Segmente unterteilen und Schritt für Schritt eine stückweise konsistente Modelldestillation durchführen.
In der ersten Stufe setzen wir k=8 und verwenden das ursprüngliche Diffusionsmodell, um 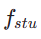 und
und 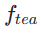 zu initialisieren. Der Startzeitschritt
zu initialisieren. Der Startzeitschritt 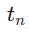 wird einheitlich zuf?llig aus
wird einheitlich zuf?llig aus  ausgew?hlt. Dann proben wir den Endzeitschritt
ausgew?hlt. Dann proben wir den Endzeitschritt 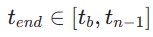 , wobei
, wobei  wie folgt berechnet wird:
wie folgt berechnet wird:
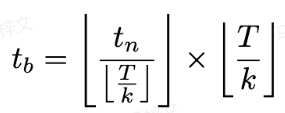
Der Trainingsverlust wird wie folgt berechnet:
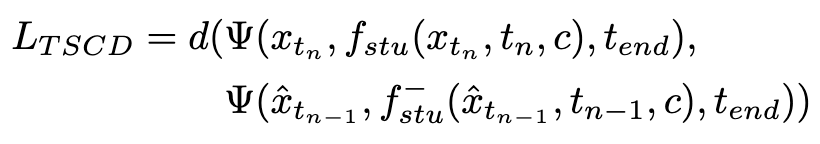
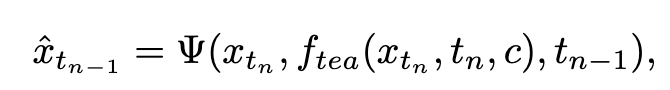
wobei 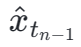 durch Gleichung 3 berechnet wird und
durch Gleichung 3 berechnet wird und 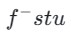 die Exponentialfunktion darstellt gleitender Durchschnitt des Studentenmodells (EMA).
die Exponentialfunktion darstellt gleitender Durchschnitt des Studentenmodells (EMA).
Anschlie?end stellen wir die Modellgewichte aus der vorherigen Stufe wieder her und trainieren weiter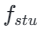 , wobei wir k schrittweise auf [4,2,1] reduzieren. Es ist erw?hnenswert, dass k=1 dem Standard-CTM-Trainingsschema entspricht. Für die Distanzmetrik d verwenden wir eine Mischung aus kontradiktorischem Verlust und mittlerem quadratischem Fehler (MSE). In Experimenten haben wir beobachtet, dass der MSE-Verlust effektiver ist, wenn der vorhergesagte Wert und der Zielwert nahe beieinander liegen (z. B. für k = 8, 4), w?hrend der gegnerische Verlust mit zunehmender Differenz zwischen dem vorhergesagten Wert und dem Zielwert zunimmt . wird pr?ziser (zum Beispiel für k=2, 1). Daher erh?hen wir w?hrend der gesamten Trainingsphase dynamisch das Gewicht des gegnerischen Verlusts und verringern das Gewicht des MSE-Verlusts. Darüber hinaus integrieren wir einen Ger?uschst?rungsmechanismus, um die Trainingsstabilit?t zu verbessern. Nehmen Sie als Beispiel den zweistufigen Trajectory Segment Consensus Distillation (TSCD)-Prozess. Wie in der Abbildung unten gezeigt, führt unsere erste Stufe eine unabh?ngige Konsistenzdestillation in den Zeitr?umen
, wobei wir k schrittweise auf [4,2,1] reduzieren. Es ist erw?hnenswert, dass k=1 dem Standard-CTM-Trainingsschema entspricht. Für die Distanzmetrik d verwenden wir eine Mischung aus kontradiktorischem Verlust und mittlerem quadratischem Fehler (MSE). In Experimenten haben wir beobachtet, dass der MSE-Verlust effektiver ist, wenn der vorhergesagte Wert und der Zielwert nahe beieinander liegen (z. B. für k = 8, 4), w?hrend der gegnerische Verlust mit zunehmender Differenz zwischen dem vorhergesagten Wert und dem Zielwert zunimmt . wird pr?ziser (zum Beispiel für k=2, 1). Daher erh?hen wir w?hrend der gesamten Trainingsphase dynamisch das Gewicht des gegnerischen Verlusts und verringern das Gewicht des MSE-Verlusts. Darüber hinaus integrieren wir einen Ger?uschst?rungsmechanismus, um die Trainingsstabilit?t zu verbessern. Nehmen Sie als Beispiel den zweistufigen Trajectory Segment Consensus Distillation (TSCD)-Prozess. Wie in der Abbildung unten gezeigt, führt unsere erste Stufe eine unabh?ngige Konsistenzdestillation in den Zeitr?umen 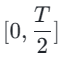 und
und 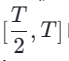 durch und führt dann eine globale Konsistenzverlaufsdestillation basierend auf den Ergebnissen der Konsistenzdestillation der beiden vorherigen Perioden durch.
durch und führt dann eine globale Konsistenzverlaufsdestillation basierend auf den Ergebnissen der Konsistenzdestillation der beiden vorherigen Perioden durch.
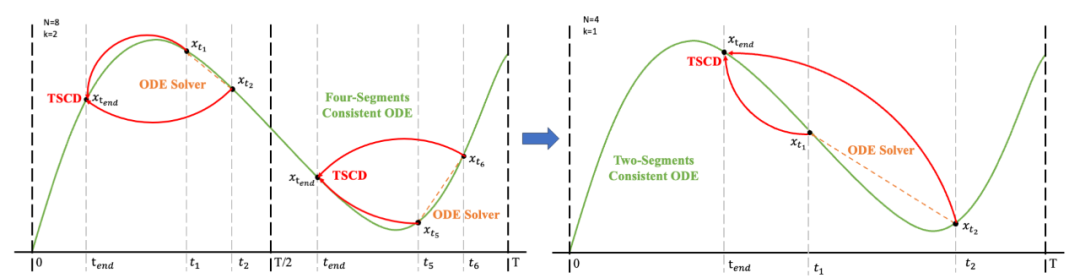
Der vollst?ndige Algorithmusprozess ist wie folgt:

2. Menschliches Feedback-Lernen
Zus?tzlich zur Destillation kombinieren wir Feedback-Lernen, um die Leistung des beschleunigten Diffusionsmodells zu verbessern. Insbesondere verbessern wir die Generierungsqualit?t beschleunigter Modelle, indem wir das Feedback menschlicher ?sthetischer Vorlieben und bestehender visueller Wahrnehmungsmodelle nutzen. Für ?sthetisches Feedback nutzen wir den LAION-?sthetikpr?diktor und das in ImageReward bereitgestellte Belohnungsmodell für ?sthetische Pr?ferenzen, um das Modell bei der Generierung ?sthetischerer Bilder anzuleiten, wie unten gezeigt:
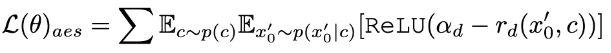
wobei 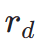 das ?sthetische Belohnungsmodell ist, einschlie?lich des ?sthetischen Pr?diktors des LAION-Datensatzes und des ImageReward-Modells, c die Textaufforderung ist und
das ?sthetische Belohnungsmodell ist, einschlie?lich des ?sthetischen Pr?diktors des LAION-Datensatzes und des ImageReward-Modells, c die Textaufforderung ist und 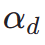 zusammen mit der ReLU-Funktion als Scharnierverlust verwendet wird. Zus?tzlich zum Feedback aus ?sthetischen Pr?ferenzen stellen wir fest, dass auch bestehende visuelle Wahrnehmungsmodelle, die umfangreiches Vorwissen über Bilder einbetten, als gute Feedbackgeber dienen k?nnen. Empirisch stellen wir fest, dass Instanzsegmentierungsmodelle das Modell dabei unterstützen k?nnen, gut strukturierte Objekte zu generieren. Konkret diffundieren wir zun?chst das Rauschen auf dem Bild
zusammen mit der ReLU-Funktion als Scharnierverlust verwendet wird. Zus?tzlich zum Feedback aus ?sthetischen Pr?ferenzen stellen wir fest, dass auch bestehende visuelle Wahrnehmungsmodelle, die umfangreiches Vorwissen über Bilder einbetten, als gute Feedbackgeber dienen k?nnen. Empirisch stellen wir fest, dass Instanzsegmentierungsmodelle das Modell dabei unterstützen k?nnen, gut strukturierte Objekte zu generieren. Konkret diffundieren wir zun?chst das Rauschen auf dem Bild 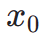 bis
bis 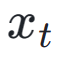 im latenten Raum. Anschlie?end führen wir, ?hnlich wie bei ImageReward, eine iterative Rauschunterdrückung bis zu einem bestimmten Zeitschritt
im latenten Raum. Anschlie?end führen wir, ?hnlich wie bei ImageReward, eine iterative Rauschunterdrückung bis zu einem bestimmten Zeitschritt 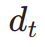 durch und sagen direkt voraus
durch und sagen direkt voraus 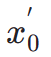 . Anschlie?end nutzen wir das perzeptive Instanzsegmentierungsmodell, um die Leistung der Strukturgenerierung zu bewerten, indem wir den Unterschied zwischen Instanzsegmentierungsanmerkungen für reale Bilder und Instanzsegmentierungsvorhersagen für entrauschte Bilder wie folgt untersuchen:
. Anschlie?end nutzen wir das perzeptive Instanzsegmentierungsmodell, um die Leistung der Strukturgenerierung zu bewerten, indem wir den Unterschied zwischen Instanzsegmentierungsanmerkungen für reale Bilder und Instanzsegmentierungsvorhersagen für entrauschte Bilder wie folgt untersuchen:
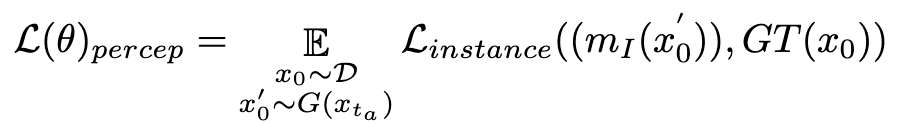
wobei 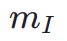 das Instanzsegmentierungsmodell ist (z. B. SOLO). Instanzsegmentierungsmodelle k?nnen die strukturellen M?ngel generierter Bilder genauer erfassen und gezieltere Rückmeldungssignale liefern. Es ist erw?hnenswert, dass neben Instanzsegmentierungsmodellen auch andere Wahrnehmungsmodelle anwendbar sind. Diese Wahrnehmungsmodelle k?nnen als erg?nzendes Feedback zur subjektiven ?sthetik dienen und sich st?rker auf die objektive generative Qualit?t konzentrieren. Daher kann unser optimiertes Diffusionsmodell mit Rückkopplungssignalen wie folgt definiert werden:
das Instanzsegmentierungsmodell ist (z. B. SOLO). Instanzsegmentierungsmodelle k?nnen die strukturellen M?ngel generierter Bilder genauer erfassen und gezieltere Rückmeldungssignale liefern. Es ist erw?hnenswert, dass neben Instanzsegmentierungsmodellen auch andere Wahrnehmungsmodelle anwendbar sind. Diese Wahrnehmungsmodelle k?nnen als erg?nzendes Feedback zur subjektiven ?sthetik dienen und sich st?rker auf die objektive generative Qualit?t konzentrieren. Daher kann unser optimiertes Diffusionsmodell mit Rückkopplungssignalen wie folgt definiert werden:
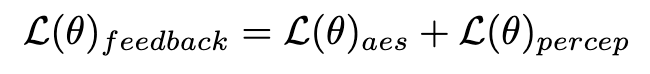
3. Verbesserung der einstufigen Generierung
Aufgrund der inh?renten Einschr?nkungen des Konsistenzverlusts ist eine einstufige Generierung innerhalb des Konsistenzmodellrahmens nicht m?glich Ideal. Wie in CM analysiert, zeigt das konsistente Destillationsmodell eine hervorragende Genauigkeit bei der Führung des Trajektorienendpunkts  an der Position
an der Position  . Daher ist die fraktionierte Destillation eine geeignete und effektive Methode, um den einstufigen Erzeugungseffekt unseres TSCD-Modells weiter zu verbessern. Insbesondere treiben wir die weitere Erzeugung durch eine optimierte DMD-Technik (Distribution Matching Destillation) voran. DMD verbessert die Ausgabe des Modells, indem es zwei verschiedene Bewertungsfunktionen nutzt: die Verteilung
. Daher ist die fraktionierte Destillation eine geeignete und effektive Methode, um den einstufigen Erzeugungseffekt unseres TSCD-Modells weiter zu verbessern. Insbesondere treiben wir die weitere Erzeugung durch eine optimierte DMD-Technik (Distribution Matching Destillation) voran. DMD verbessert die Ausgabe des Modells, indem es zwei verschiedene Bewertungsfunktionen nutzt: die Verteilung 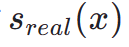 aus dem Lehrermodell und die
aus dem Lehrermodell und die 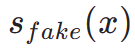 aus dem Fake-Modell. Wir kombinieren den Verlust des mittleren quadratischen Fehlers (MSE) mit einer punktebasierten Destillation, um die Trainingsstabilit?t zu verbessern. In diesem Prozess werden auch die oben genannten menschlichen Feedback-Lerntechniken integriert, um unser Modell so zu optimieren, dass Bilder mit hoher Wiedergabetreue effektiv generiert werden.
aus dem Fake-Modell. Wir kombinieren den Verlust des mittleren quadratischen Fehlers (MSE) mit einer punktebasierten Destillation, um die Trainingsstabilit?t zu verbessern. In diesem Prozess werden auch die oben genannten menschlichen Feedback-Lerntechniken integriert, um unser Modell so zu optimieren, dass Bilder mit hoher Wiedergabetreue effektiv generiert werden.
Durch die Integration dieser Strategien erzielt unsere Methode nicht nur hervorragende Low-Step-Inferenzergebnisse sowohl für SD1.5 als auch für SDXL (und erfordert keine Klassifikatorführung), sondern erreicht auch ein ideales globales Konsistenzmodell, ohne dass für jede eine bestimmte Zahl erforderlich ist Die Anzahl der Schritte wird verwendet, um UNet oder LoRA zu trainieren, um ein einheitliches Low-Step-Argumentationsmodell zu erreichen.
Experimente
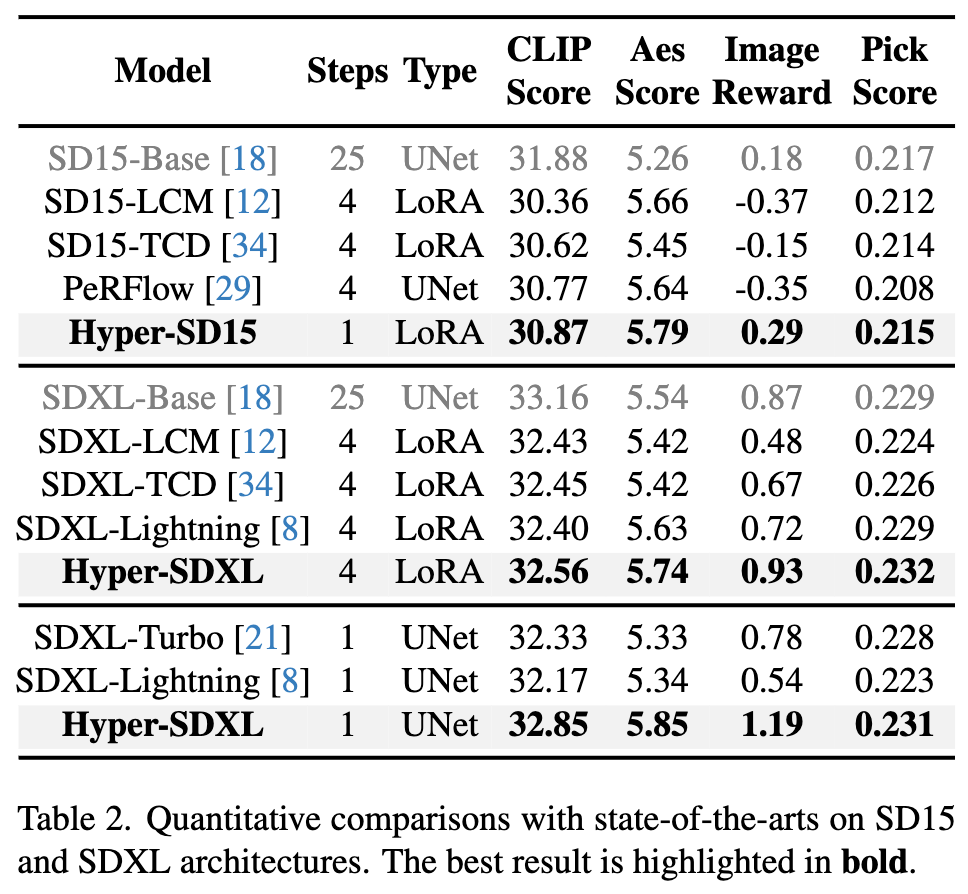
Quantitativer Vergleich verschiedener bestehender Beschleunigungsalgorithmen auf SD1.5 und SDXL zeigt, dass Hyper-SD deutlich besser ist als die aktuellen State-of-the-Art-Methoden
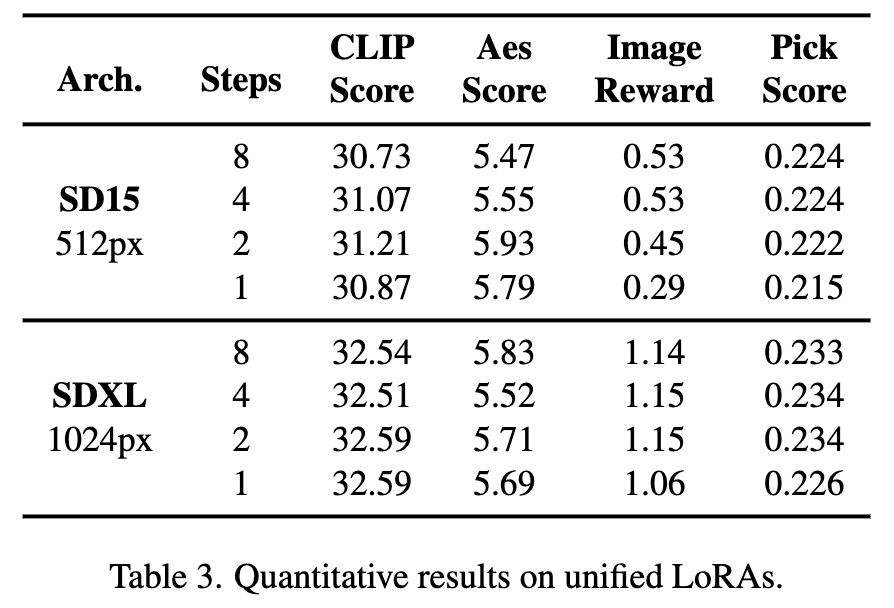
Darüber hinaus kann Hyper-SD ein Modell verwenden, um verschiedene Low-Step-Schlussfolgerungen zu erzielen. Die oben genannten quantitativen Indikatoren zeigen auch die Wirkung unserer Methode, wenn ein einheitliches Modell für die Schlussfolgerung verwendet wird.


Die Visualisierung des Beschleunigungseffekts auf SD1.5 und SDXL zeigt intuitiv die überlegenheit von Hyper-SD bei der Beschleunigung der Diffusionsmodellinferenz.
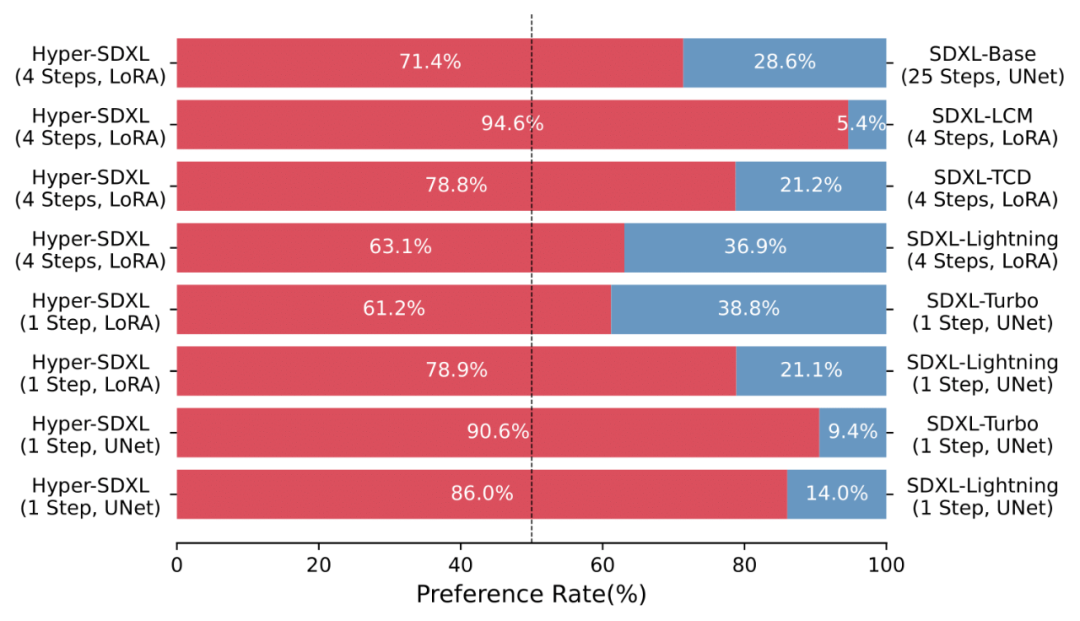
Eine Vielzahl von Anwenderstudien zeigt auch die überlegenheit von Hyper-SD gegenüber verschiedenen bestehenden Beschleunigungsalgorithmen.

Das von Hyper-SD trainierte beschleunigte LoRA ist gut kompatibel mit verschiedenen Stilen von Vincent-Figurenbasismodellen.
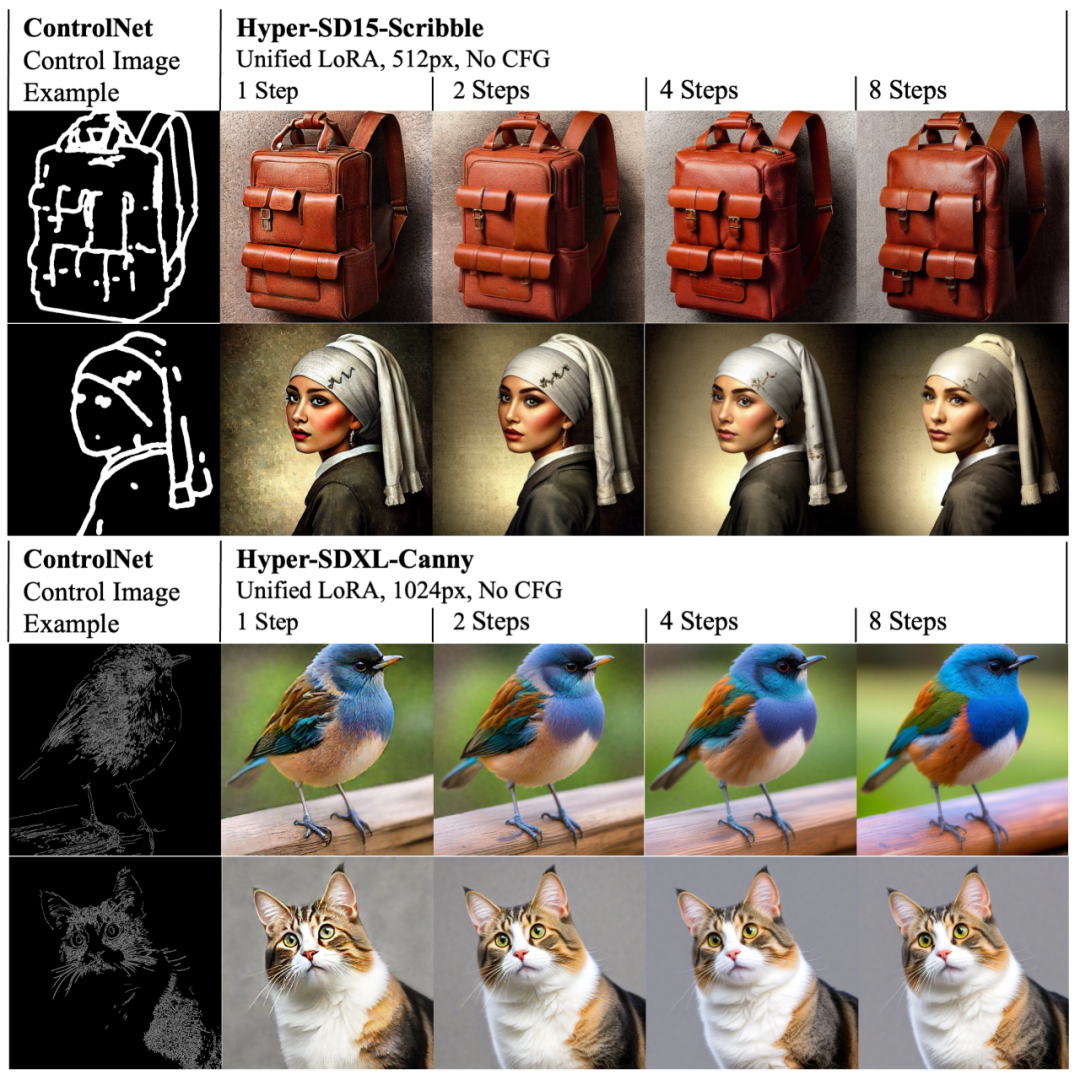
Gleichzeitig kann sich LoRA von Hyper-SD auch an das bestehende ControlNet anpassen, um eine qualitativ hochwertige, steuerbare Bilderzeugung mit einer geringen Anzahl von Schritten zu erreichen.
Zusammenfassung
Das Papier schl?gt Hyper-SD vor, ein einheitliches Framework zur Beschleunigung von Diffusionsmodellen, das die Generierungsf?higkeit von Diffusionsmodellen in Low-Step-Situationen erheblich verbessern und eine neue SOTA-Leistung basierend auf SDXL und SD15 erreichen kann. Diese Methode nutzt die Trajektoriensegmentierungskonsistenzdestillation, um die F?higkeit zur Trajektorienkonservierung w?hrend des Destillationsprozesses zu verbessern und einen Erzeugungseffekt zu erzielen, der dem ursprünglichen Modell nahe kommt. Anschlie?end wird das Potenzial des Modells bei extrem niedrigen Schrittzahlen durch die weitere Nutzung des menschlichen Feedback-Lernens und der Variationsfraktionellestillation verbessert, was zu einer optimierteren und effizienteren Modellgenerierung führt. Das Papier stellte auch das Lora-Plug-in für SDXL und SD15 mit 1- bis 8-stufiger Inferenz sowie ein spezielles einstufiges SDXL-Modell als Open-Source-L?sung zur Verfügung, um die Entwicklung der generativen KI-Community weiter voranzutreiben.
Das obige ist der detaillierte Inhalt vonBeschleunigen Sie das Diffusionsmodell und generieren Sie Bilder auf SOTA-Ebene im schnellsten Schritt. Byte Hyper-SD ist Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Wie sehe ich die Commit -Geschichte meines Git -Repositorys?
Jul 13, 2025 am 12:07 AM
Wie sehe ich die Commit -Geschichte meines Git -Repositorys?
Jul 13, 2025 am 12:07 AM
Verwenden Sie den Befehl gitlogs, um Git -Commit -Geschichte anzuzeigen. 1. Die grundlegende Nutzung ist Gitlog, mit dem die Einreichungs -Hash-, Autor-, Datums- und Einreichungsinformationen angezeigt werden k?nnen. 2. Verwenden Sie Gitlog-Eingang, um eine kurze Ansicht zu erhalten. 3.. Filter durch Autor- oder Einreichungsinformationen durch -autor und --grep; 4. Fügen Sie -p hinzu, um Code?nderungen anzuzeigen, -stat, um ?nderungsstatistiken anzuzeigen. 5. Verwenden Sie -Graph und -alle, um den Zweig -Verlauf anzuzeigen oder Visualisierungstools wie Gitkraken und VSCODE zu verwenden.
 Wie l?sche ich einen Git -Zweig?
Jul 13, 2025 am 12:02 AM
Wie l?sche ich einen Git -Zweig?
Jul 13, 2025 am 12:02 AM
Um einen Git -Zweig zu l?schen, stellen Sie zun?chst sicher, dass er zusammengeführt wurde oder keine Aufbewahrung erforderlich ist. Verwenden Sie Gitbranch-D, um die lokale zusammengeführte Niederlassung zu l?schen. Wenn Sie l?schende, nicht vererdigte Zweige erzwingen müssen, verwenden Sie den Parameter -d. Remote Branch Deletion verwendet den Befehl gitpushorigin-deleteBranch-name und kann die lokalen Repositorys anderer Personen über Gitfetch-Prune synchronisieren. 1. Um die lokale Niederlassung zu l?schen, müssen Sie best?tigen, ob sie zusammengeführt wurde. 2. Um den Remotezweig zu l?schen, müssen Sie den Parameter -Delete verwenden. 3. Nach dem L?schen sollten Sie überprüfen, ob der Zweig erfolgreich entfernt wird. V. 5. Reinigen Sie nutzlose Zweige regelm??ig, um das Lagerhaus sauber zu halten.
 Kann ich Dogecoin im W?hrungskreis kaufen? Wie identifiziere ich Betrugselemente?
Jul 10, 2025 pm 09:54 PM
Kann ich Dogecoin im W?hrungskreis kaufen? Wie identifiziere ich Betrugselemente?
Jul 10, 2025 pm 09:54 PM
Das "Hundcoin" im W?hrungskreis bezieht sich normalerweise auf neu ausgestellte Kryptow?hrungen mit extrem geringem Marktwert, undurchsichtigem Projektinformationen, schwacher technischer Grundlage oder sogar nicht praktischen Anwendungsszenarien. Diese Token erscheinen oft mit Hochrisikonarrativen.
 Wie füge ich meinem Git -Repository einen Unterbaum hinzu?
Jul 16, 2025 am 01:48 AM
Wie füge ich meinem Git -Repository einen Unterbaum hinzu?
Jul 16, 2025 am 01:48 AM
Um einem Git-Repository ein Subtree hinzuzufügen, fügen Sie zuerst das Remote-Repository hinzu und holen Sie sich seinen Verlauf und fusionieren Sie es dann mit den Befehlen gitmerge und gitread tree in ein Unterverzeichnis. Die Schritte sind wie folgt: 1. Verwenden Sie den Befehl gitremoteadd-f, um ein Remote-Repository hinzuzufügen; 2. Führen Sie Gitmerge-Screcursive-No-Commit aus, um Zweiginhalte zu erhalten. 3.. Verwenden Sie GitRead-Tree-Prefix =, um das Verzeichnis anzugeben, um das Projekt als Subtree zusammenzuführen; V. 5. Bei der Aktualisierung zuerst Gitfetch und wiederholen Sie die Verschmelzung und Schritte, um das Update einzureichen. Diese Methode h?lt die externe Projekthistorie vollst?ndig und leicht zu warten.
 Wie identifiziere ich gef?lschte Altcoins? Lehre dich, Kryptow?hrungsbetrug zu vermeiden
Jul 15, 2025 pm 10:36 PM
Wie identifiziere ich gef?lschte Altcoins? Lehre dich, Kryptow?hrungsbetrug zu vermeiden
Jul 15, 2025 pm 10:36 PM
Um gef?lschte Altcoins zu identifizieren, müssen Sie von sechs Aspekten ausgehen. 1. überprüfen und überprüfen Sie den Hintergrund der Materialien und des Projekts, einschlie?lich wei?er Papiere, offizieller Websites, Code Open Source -Adressen und Teamtransparenz; 2. Beobachten Sie die Online -Plattform und geben Sie dem Mainstream -Austausch Priorit?t. 3.. Achten Sie vor hohen Renditen und Personenverpackungsmodi, um Fondsfallen zu vermeiden. 4. Analysieren Sie den Vertragscode und den Token -Mechanismus, um zu überprüfen, ob es b?swillige Funktionen gibt. 5. überprüfen Sie Community- und Medienoperationen, um falsche Popularit?t zu identifizieren. 6. Befolgen Sie die praktischen Vorschl?ge gegen das Strand, z. B. nicht an Empfehlungen zu glauben oder professionelle Geldb?rsen zu verwenden. Die obigen Schritte k?nnen Betrugsbetrug effektiv vermeiden und die Sicherheit der Verm?genswerte schützen.
 Wie lautet die Codenummer von Bitcoin? Welcher Codestil ist Bitcoin?
Jul 22, 2025 pm 09:51 PM
Wie lautet die Codenummer von Bitcoin? Welcher Codestil ist Bitcoin?
Jul 22, 2025 pm 09:51 PM
Als Pionier in der digitalen Welt standen der einzigartige Codename und die zugrunde liegende Technologie immer im Mittelpunkt der Aufmerksamkeit der Menschen. Sein Standardcode ist BTC, auch als XBT auf bestimmten Plattformen bekannt, die internationale Standards entsprechen. Aus technischer Sicht ist Bitcoin kein einziger Codestil, sondern ein riesiges und ausgeklügeltes Open -Source -Softwareprojekt. Sein Kerncode ist haupts?chlich in C geschrieben und enth?lt Kryptographie, verteilte Systeme und Wirtschaftsgrunds?tze, damit jeder seinen Code anzeigen, überprüfen und beitragen kann.
 Was ist nutzlose Münze? überblick über nutzlose W?hrungsnutzung, herausragende Merkmale und zukünftiges Wachstumspotenzial
Jul 24, 2025 pm 11:54 PM
Was ist nutzlose Münze? überblick über nutzlose W?hrungsnutzung, herausragende Merkmale und zukünftiges Wachstumspotenzial
Jul 24, 2025 pm 11:54 PM
Was sind die wichtigsten Punkte des Katalogs? UNSELESSCOIN: übersicht und wichtige Funktionen von nutzloser Funktionen von nutzlosen nutzlosen Nutzlosen (nutzlos) zukünftige Preisaussichten: Was wirkt sich auf den Preis von nutzloser Coin im Jahr 2025 und darüber hinaus aus? Zukünftige Preisausblicke Kernfunktionen und Wichtigkeiten von nutzlosen (nutzlos) Wie nutzlos (nutzlos) funktioniert und wie er nützt, wie nutzlos die wesentlichen Vorteile für die Unternehmens -Partnerschaften von Nutzelesscoin wie sie zusammenarbeiten
 So setzen Sie Umgebungsvariablen in der PHP -Umgebung Beschreibung des Hinzufügens von PHP -Ausführungsumgebungsvariablen
Jul 25, 2025 pm 08:33 PM
So setzen Sie Umgebungsvariablen in der PHP -Umgebung Beschreibung des Hinzufügens von PHP -Ausführungsumgebungsvariablen
Jul 25, 2025 pm 08:33 PM
Es gibt drei Hauptmethoden, um Umgebungsvariablen in PHP festzulegen: 1. Globale Konfiguration über php.ini; 2. durch einen Webserver (z. B. SetEnv von Apache oder FastCGI_Param von Nginx); 3. Verwenden Sie die Funktion Putenv () in PHP -Skripten. Unter ihnen eignet sich Php.ini für globale und selten ?ndernde Konfigurationen. Die Webserverkonfiguration eignet sich für Szenarien, die isoliert werden müssen, und Putenv () ist für tempor?re Variablen geeignet. Die Persistenz -Richtlinien umfassen Konfigurationsdateien (z. B. Php.ini oder Webserverkonfiguration), .env -Dateien werden mit der DOTENV -Bibliothek und dynamische Injektion von Variablen in CI/CD -Prozessen geladen. Sicherheitsmanagement sensible Informationen sollten hart codiert werden, und es wird empfohlen.
