
 Technologie-Peripherieger?te
KI
KI unterstützt die Forschung an Gehirn-Computer-Schnittstellen, die bahnbrechende neuronale Sprachdekodierungstechnologie der New York University, ver?ffentlicht in der Unterzeitschrift ?Nature'.
Technologie-Peripherieger?te
KI
KI unterstützt die Forschung an Gehirn-Computer-Schnittstellen, die bahnbrechende neuronale Sprachdekodierungstechnologie der New York University, ver?ffentlicht in der Unterzeitschrift ?Nature'.
KI unterstützt die Forschung an Gehirn-Computer-Schnittstellen, die bahnbrechende neuronale Sprachdekodierungstechnologie der New York University, ver?ffentlicht in der Unterzeitschrift ?Nature'.
Apr 17, 2024 am 08:40 AM

Autor |. Chen Xupeng
In den letzten Jahren hat die rasante Entwicklung des Deep Learning und der Brain-Computer-Interface-Technologie (BCI) die M?glichkeit er?ffnet, Neurosprachprothesen zu entwickeln, die aphasischen Menschen bei der Kommunikation helfen k?nnen. Die Sprachdekodierung neuronaler Signale steht jedoch vor Herausforderungen.
Kürzlich haben Forscher von VideoLab und Flinker Lab an der Universit?t von Jordanien einen neuen Typ eines differenzierbaren Sprachsynthesizers entwickelt, der ein leichtes Faltungs-Neuronales Netzwerk verwenden kann, um Sprache in eine Reihe interpretierbarer Sprachparameter (wie Tonh?he, Lautst?rke, Formant) zu kodieren Frequenz usw.) und diese Parameter werden über ein differenzierbares neuronales Netzwerk in Sprache synthetisiert. Dieser Synthesizer kann auch Sprachparameter (wie Tonh?he, Lautst?rke, Formantenfrequenzen usw.) über ein leichtes Faltungs-Neuronales Netzwerk analysieren und Sprache über einen differenzierbaren Sprachsynthesizer neu synthetisieren.
Die Forscher haben ein System zur Decodierung neuronaler Signale entwickelt, das gut interpretierbar und auf Situationen mit kleinen Datenmengen anwendbar ist, indem neuronale Signale diesen Sprachparametern zugeordnet werden, ohne die Bedeutung des ursprünglichen Inhalts zu ?ndern.
Die Forschung trug den Titel ?
Ein neuronales Sprachdekodierungs-Framework, das Deep Learning und Sprachsynthese nutzt“ und wurde am 8. April 2024 in der Zeitschrift ?Nature Machine Intelligence“ ver?ffentlicht.
 Link zum Papier:
Link zum Papier:
Forschungshintergrund
Die meisten Versuche, Decoder für neuronale Sprache zu entwickeln, basieren auf einem A-Special Art der Daten: Daten von Patienten, die sich einer Epilepsieoperation unterzogen, mittels Elektrokortikographie (ECoG)-Aufzeichnungen. Mithilfe von Elektroden, die Patienten mit Epilepsie implantiert werden, um w?hrend der Sprachproduktion Daten aus der Gro?hirnrinde zu sammeln, haben diese Daten eine hohe r?umlich-zeitliche Aufl?sung und haben Forschern dabei geholfen, eine Reihe bemerkenswerter Ergebnisse auf dem Gebiet der Sprachdekodierung zu erzielen und so die Entwicklung von Gehirn-Computer-Schnittstellen voranzutreiben Feld.
Die Sprachdekodierung neuronaler Signale steht vor zwei gro?en Herausforderungen.
Erstens sind die Daten, die zum Trainieren personalisierter neuronaler Sprachdekodierungsmodelle verwendet werden, zeitlich sehr begrenzt, normalerweise nur etwa zehn Minuten, w?hrend Deep-Learning-Modelle oft eine gro?e Menge an Trainingsdaten ben?tigen, um zu fahren.
Zweitens ist die menschliche Aussprache sehr unterschiedlich. Selbst wenn dieselbe Person wiederholt dasselbe Wort spricht, ?ndern sich die Sprechgeschwindigkeit, die Intonation und die Tonh?he, was den vom Modell erstellten Darstellungsraum komplexer macht.
Frühe Versuche, neuronale Signale in Sprache zu dekodieren, stützten sich haupts?chlich auf lineare Modelle. Die Modelle erforderten normalerweise keine gro?en Trainingsdatens?tze und waren gut interpretierbar, aber die Genauigkeit war sehr gering.
Neuere Forschungen, die auf tiefen neuronalen Netzen basieren, insbesondere die Verwendung von Faltungs- und wiederkehrenden neuronalen Netzarchitekturen, werden in zwei Schlüsseldimensionen entwickelt: der latenten Zwischendarstellung simulierter Sprache und der Qualit?t synthetisierter Sprache. Beispielsweise gibt es Studien, die die Aktivit?t der Gro?hirnrinde in Mundbewegungsr?ume dekodieren und diese dann in Sprache umwandeln. Obwohl die Dekodierungsleistung leistungsstark ist, klingt die rekonstruierte Stimme unnatürlich.
Andererseits rekonstruieren einige Methoden erfolgreich natürlich klingende Sprache mithilfe von Wavenet-Vocoder, Generative Adversarial Network (GAN) usw., ihre Genauigkeit ist jedoch begrenzt. Kürzlich wurden in einer Studie an Patienten mit implantierten Ger?ten sowohl genaue als auch natürliche Sprachwellenformen erzielt, indem quantisierte HuBERT-Merkmale als Zwischendarstellungsraum und ein vortrainierter Sprachsynthesizer zur Umwandlung dieser Merkmale in Sprache verwendet wurden.
Allerdings k?nnen die HuBERT-Funktionen keine sprecherspezifischen akustischen Informationen darstellen und nur feste und einheitliche Sprechert?ne erzeugen. Daher sind zus?tzliche Modelle erforderlich, um diesen universellen Klang in die Stimme eines bestimmten Patienten umzuwandeln. Darüber hinaus wurde in dieser Studie und den meisten früheren Versuchen eine nicht-kausale Architektur verwendet, was ihre Verwendung in praktischen Anwendungen von Gehirn-Computer-Schnittstellen, die zeitliche kausale Operationen erfordern, m?glicherweise einschr?nkt.
Hauptmodellrahmen
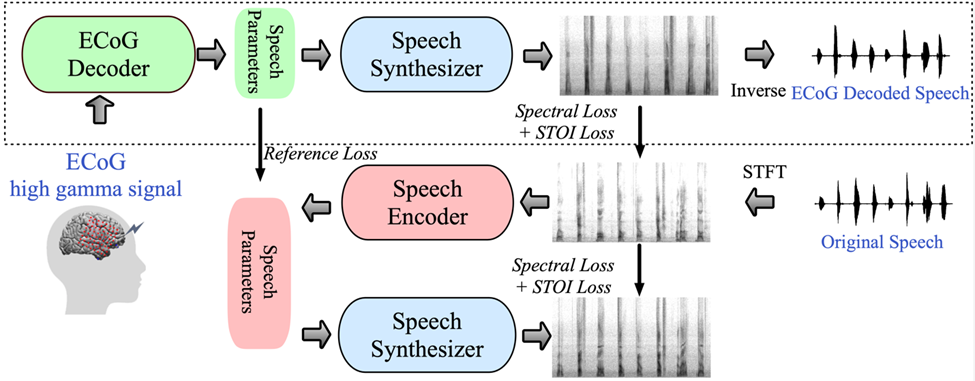 Abbildung 1: Vorgeschlagener Rahmen für die neuronale Sprachdekodierung. (Quelle: Papier)
Abbildung 1: Vorgeschlagener Rahmen für die neuronale Sprachdekodierung. (Quelle: Papier)
Das von der Forschung vorgeschlagene Framework besteht aus zwei Teilen: Der eine ist der ECoG-Decoder, der das ECoG-Signal in akustische Sprachparameter umwandelt, die wir verstehen k?nnen (wie Tonh?he, ob es ausgesprochen wird, Lautst?rke und Formantenfrequenz usw.). ); der andere Teil ist ein Sprachsynthesizer, der diese Sprachparameter in ein Spektrogramm umwandelt.
Die Forscher haben einen differenzierbaren Sprachsynthesizer entwickelt, der es dem Sprachsynthesizer erm?glicht, w?hrend des Trainings des ECoG-Decoders auch am Training teilzunehmen und gemeinsam zu optimieren, um den Fehler bei der Spektrogrammrekonstruktion zu reduzieren. Dieser niedrigdimensionale latente Raum verfügt über eine starke Interpretierbarkeit, gepaart mit einem leichten vorab trainierten Sprachkodierer zur Generierung von Referenz-Sprachparametern, was Forschern hilft, ein effizientes neuronales Sprachdekodierungs-Framework aufzubauen und das Problem der Datenknappheit zu überwinden.
Dieses Framework kann natürliche Sprache erzeugen, die der eigenen Stimme des Sprechers sehr nahe kommt, und der ECoG-Decoder-Teil kann in verschiedene Deep-Learning-Modellarchitekturen eingebunden werden und unterstützt auch kausale Operationen. Die Forscher sammelten und verarbeiteten ECoG-Daten von 48 neurochirurgischen Patienten und verwendeten dabei mehrere Deep-Learning-Architekturen (einschlie?lich Faltung, rekurrentes neuronales Netzwerk und Transformer) als ECoG-Decoder.
Das Framework hat bei verschiedenen Modellen eine hohe Genauigkeit bewiesen, wobei die Faltungsarchitektur (ResNet) die beste Leistung erzielte, wobei der Pearson-Korrelationskoeffizient (PCC) zwischen dem ursprünglichen und dem dekodierten Spektrogramm 0,806 erreichte. Das von den Forschern vorgeschlagene Framework kann nur durch kausale Operationen und eine relativ niedrige Abtastrate (niedrige Dichte, 10 mm Abstand) eine hohe Genauigkeit erreichen.
Die Forscher zeigten au?erdem, dass eine effektive Sprachdekodierung sowohl von der linken als auch von der rechten Gehirnh?lfte aus durchgeführt werden kann, wodurch die Anwendung der neuronalen Sprachdekodierung auf die rechte Gehirnh?lfte ausgeweitet wurde.
Forschungsbezogener Code Open Source: https://github.com/flinkerlab/neural_speech_decoding
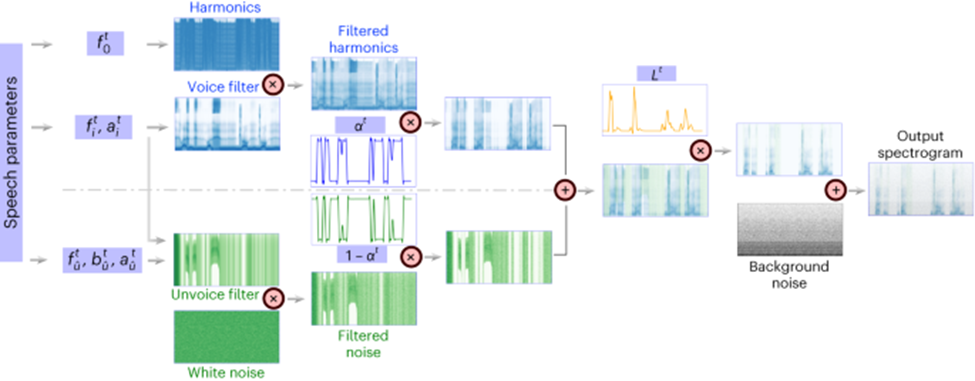
Die wichtige Innovation dieser Forschung besteht darin, einen differenzierbaren Sprachsynthesizer (Sprachsynthesizer) vorzuschlagen, der die Aufgabe der Sprachneusynthese sehr effizient macht und hochaufl?sende Aufkleber mit sehr kleiner Sprachanpassung synthetisieren kann Audio.
Das Prinzip des differenzierbaren Sprachsynthesizers basiert auf dem Prinzip des menschlichen generativen Systems und unterteilt die Sprache in zwei Teile: Stimme (zur Modellierung von Vokalen) und Unvoice (zur Modellierung von Konsonanten):
Der Sprachteil kann zun?chst mit dem verwendet werden Basis Das Frequenzsignal erzeugt Harmonische, und der Filter, der aus den Formantenspitzen von F1-F6 besteht, wird gefiltert, um die spektralen Eigenschaften des Vokalteils zu erhalten. Der Forscher filtert das wei?e Rauschen mit dem entsprechenden Filter, um das entsprechende zu erhalten Spektrum, das mit den erlernten Parametern das Mischungsverh?ltnis der beiden Teile zu jedem Zeitpunkt steuern kann. Anschlie?end wird das Lautst?rkesignal verst?rkt und Hintergrundger?usche hinzugefügt, um das endgültige Sprachspektrum zu erhalten. Basierend auf diesem Sprachsynthesizer entwirft dieser Artikel ein effizientes Sprachresynthese-Framework und ein neuronales Sprachdecodierungs-Framework.
Forschungsergebnisse
Ergebnisse der Sprachdekodierung mit zeitlicher Kausalit?t
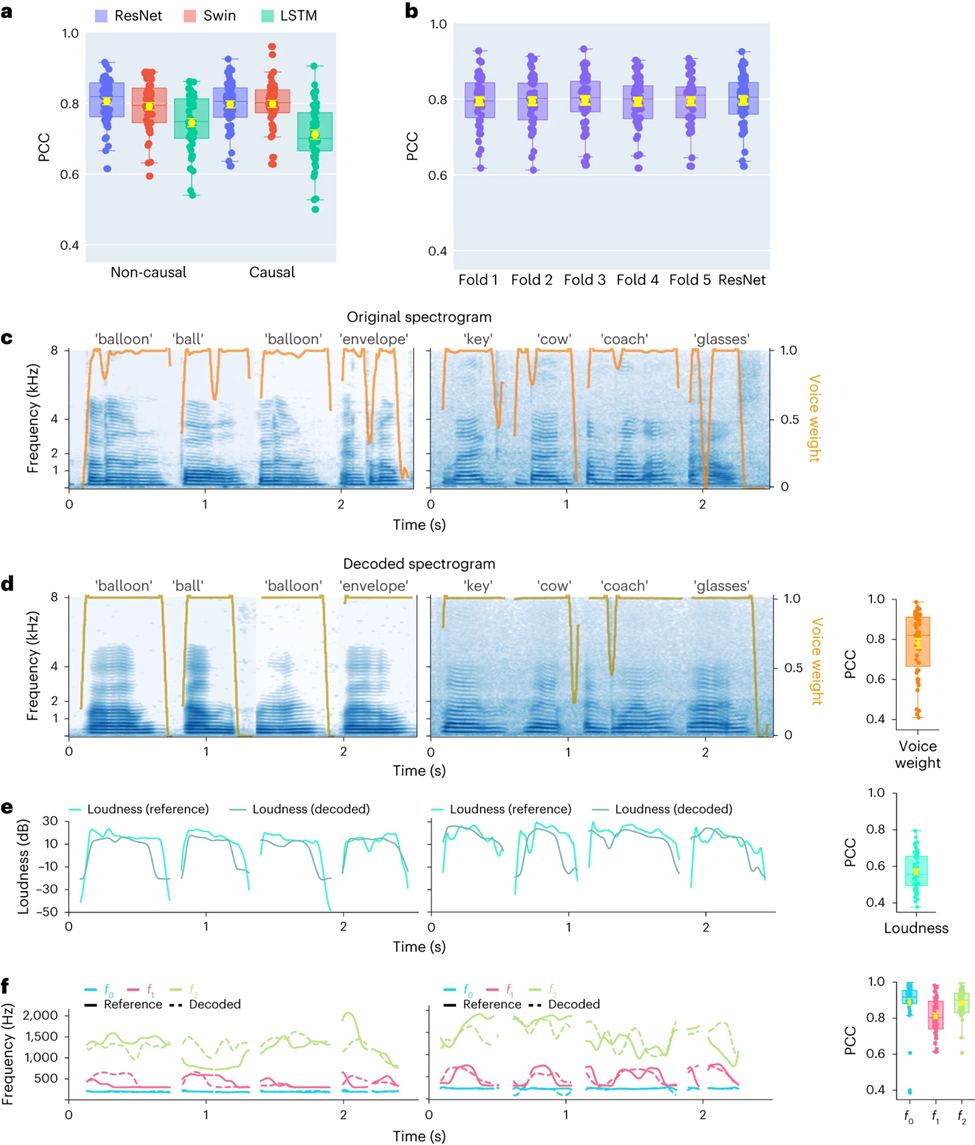
Zun?chst verglichen die Forscher direkt die Unterschiede in der Sprachdekodierungsleistung verschiedener Modellarchitekturen (Convolution (ResNet), Recurrent (LSTM) und Transformer (3D Swin). Es ist erw?hnenswert, dass diese Modelle keine Leistung erbringen k?nnen -kausale oder kausale Operationen auf Zeit
Die Ergebnisse zeigen, dass das ResNet-Modell unter allen Modellen den h?chsten Pearson-Korrelationskoeffizienten (PCC) erreicht. Der durchschnittliche PCC für kausal und kausal betr?gt 0,806 bzw. 0,797. gefolgt vom Swin-Modell (der durchschnittliche PCC für nicht-kausal und 0,798) (Abbildung 2a)
Ein ?hnliches Ergebnis wurde durch die Auswertung des STOI+-Indikators erzielt Dies hat erhebliche Auswirkungen auf Brain-Computer-Interface-Anwendungen (BCI): Kausale Modelle verwenden nur vergangene und aktuelle neuronale Signale, um Sprache zu erzeugen, w?hrend akausale Modelle auch zukünftige neuronale Signale verwenden. Bei Verwendung eines nicht-kausalen Modells ist dies in Echtzeitanwendungen nicht m?glich Daher konzentrierten sich die Forscher auf den Vergleich der Leistung desselben Modells bei der Durchführung nicht-kausaler und kausaler Operationen.
Die Studie ergab, dass sogar die kausale Version des ResNet-Modells vergleichbar ist. und es gibt keinen signifikanten Unterschied zwischen ihnen. Ebenso ist die Leistung der kausalen und nicht-kausalen Version des Swin-Modells ?hnlich, aber die Leistung der kausalen Version des LSTM-Modells ist deutlich geringer als die der nicht-kausalen Version Daher werden sich die Forscher in Zukunft auf die Modelle ResNet und Swin konzentrieren.
Um sicherzustellen, dass sich das in diesem Artikel vorgeschlagene Framework gut auf unbekannte W?rter übertragen l?sst, führten die Forscher eine strengere Kreuzvalidierung auf Wortebene durch, was bedeutet, dass verschiedene Versuche durchgeführt werden Das gleiche Wort wird nicht gleichzeitig im Trainingssatz und im Test angezeigt. Wie in Abbildung 2b gezeigt, ist die Leistung bei nicht sichtbaren W?rtern mit der experimentellen Standardmethode im Artikel vergleichbar, was darauf hinweist, dass das Modell gut dekodieren kann Auch wenn es w?hrend des Trainings nicht gesehen wurde, was haupts?chlich auf diesen Artikel zurückzuführen ist, führt das gebaute Modell eine Sprachdekodierung auf Phonem- oder ?hnlicher Ebene durch.
Darüber hinaus demonstrieren die Forscher die Leistung des ResNet-Kausaldecoders auf Einzelwortebene und zeigen Daten von zwei Teilnehmern (EKoG mit niedriger Abtastrate). Das dekodierte Spektrogramm beh?lt die spektral-zeitliche Struktur der ursprünglichen Sprache genau bei (Abbildung 2c, d).
Die Forscher verglichen auch die vom neuronalen Decoder vorhergesagten Sprachparameter mit den vom Sprachcodierer codierten Parametern (als Referenzwerte). Die Forscher zeigten den durchschnittlichen PCC-Wert (N=48) mehrerer wichtiger Sprachparameter, einschlie?lich der Klanggewichtung (). Wird zur Unterscheidung von Vokalen und Konsonanten verwendet), Lautst?rke, Tonh?he f0, erster Formant f1 und zweiter Formant f2. Eine genaue Rekonstruktion dieser Sprachparameter, insbesondere Tonh?he, Klanggewicht und die ersten beiden Formanten, ist entscheidend für eine genaue Sprachdekodierung und -rekonstruktion, die die Stimme des Teilnehmers auf natürliche Weise nachahmt.
Die Forschungsergebnisse zeigen, dass sowohl nicht-kausale als auch kausale Modelle vernünftige Dekodierungsergebnisse erzielen k?nnen, was eine positive Orientierung für zukünftige Forschung und Anwendungen bietet.
Studie zur Sprachdekodierung neuronaler Signale der linken und rechten Gehirnh?lfte und zur r?umlichen Abtastrate
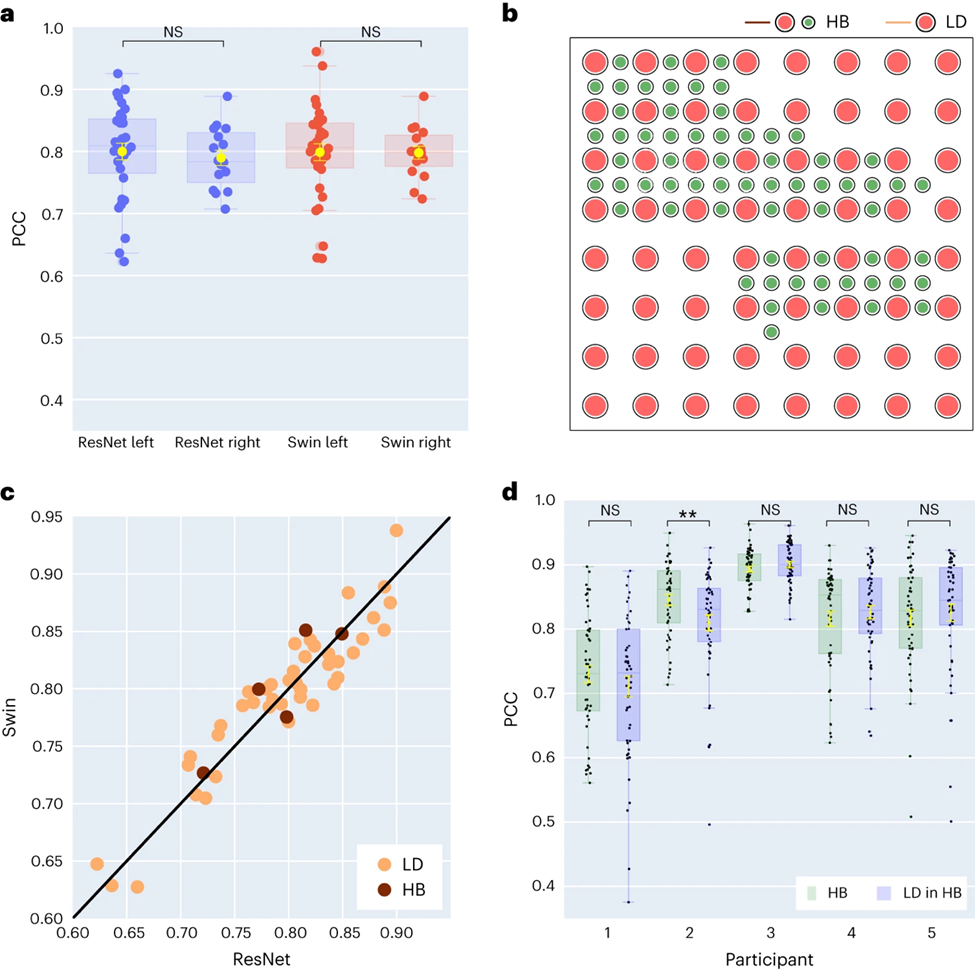
Die Forscher verglichen au?erdem die Ergebnisse der Sprachdekodierung der linken und rechten Gehirnh?lfte. Die meisten Studien konzentrieren sich auf die linke Gehirnh?lfte, die für Sprache und Sprachfunktionen verantwortlich ist. Allerdings ist wenig darüber bekannt, wie Sprachinformationen aus der rechten Gehirnh?lfte entschlüsselt werden. Als Reaktion darauf verglichen die Forscher die Dekodierungsleistung der linken und rechten Gehirnh?lfte der Teilnehmer, um die M?glichkeit zu überprüfen, die rechte Gehirnh?lfte zur Sprachwiederherstellung zu nutzen.
Von den 48 in der Studie erfassten Probanden wurden die ECoG-Signale von 16 Probanden aus der rechten Gehirnh?lfte erfasst. Durch den Vergleich der Leistung von ResNet- und Swin-Dekodierern stellten die Forscher fest, dass die rechte Hemisph?re auch Sprache stabil dekodieren kann (der PCC-Wert von ResNet betr?gt 0,790, der PCC-Wert von Swin betr?gt 0,798), was sich weniger vom Dekodierungseffekt der linken Hemisph?re unterscheidet ( As (siehe Abbildung 3a).
Diese Erkenntnis gilt auch für die Bewertung von STOI+. Dies bedeutet, dass für Patienten mit einer Sch?digung der linken Hemisph?re und einem Verlust der Sprachf?higkeit die Verwendung neuronaler Signale der rechten Hemisph?re zur Wiederherstellung der Sprache eine praktikable L?sung sein kann.
Dann untersuchten die Forscher den Einfluss der Elektroden-Abtastdichte auf den Sprachdekodierungseffekt. Frühere Studien verwendeten meist Elektrodengitter mit h?herer Dichte (0,4 mm), w?hrend die Dichte der in der klinischen Praxis üblicherweise verwendeten Elektrodengitter geringer ist (LD 1 cm).
Fünf Teilnehmer verwendeten Hybrid-Elektrodengitter (HB) (siehe Abbildung 3b), bei denen es sich haupts?chlich um Probenentnahme mit niedriger Dichte handelt, in die jedoch zus?tzliche Elektroden integriert sind. Die restlichen 43 Teilnehmer wurden in geringer Dichte beprobt. Die Dekodierungsleistung dieser Hybrid-Samples (HB) ist ?hnlich wie bei herk?mmlichen Low-Density-Samples (LD), schneidet jedoch bei STOI+ etwas besser ab.
Die Forscher verglichen die Wirkung der ausschlie?lichen Verwendung von Elektroden mit geringer Dichte mit der Verwendung aller gemischten Elektroden zur Dekodierung und stellten fest, dass der Unterschied zwischen beiden nicht signifikant war (siehe Abbildung 3d), was darauf hindeutet, dass das Modell in der Lage ist, Proben aus der Gro?hirnrinde zu entnehmen Es werden unterschiedliche r?umliche Dichten erlernt, was auch impliziert, dass die in der klinischen Praxis üblicherweise verwendete Abtastdichte für zukünftige Gehirn-Computer-Schnittstellenanwendungen ausreichend sein k?nnte.
Untersuchung des Beitrags verschiedener Gehirnbereiche der linken und rechten Gehirnh?lfte zur Sprachdekodierung
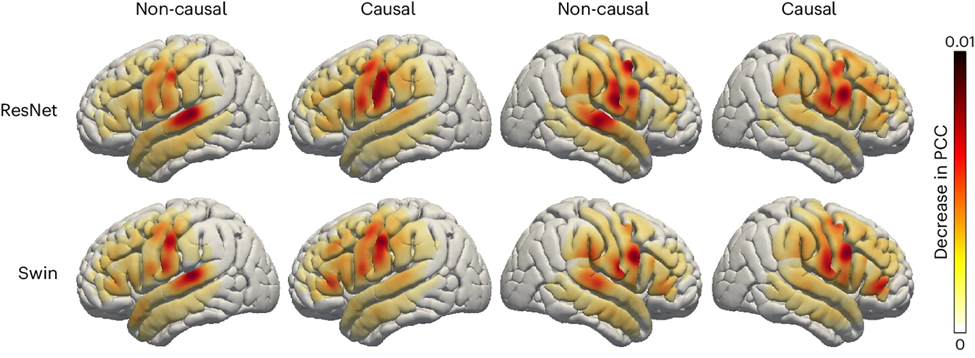
Abschlie?end untersuchten die Forscher den Beitrag sprachbezogener Bereiche des Gehirns beim Sprachdekodierungsprozess, der eine wichtige Referenz für die zukünftige Implantation von Sprachwiederherstellungsger?ten in die linke und rechte Gehirnh?lfte liefert . Die Forscher nutzten die Okklusionsanalyse, um den Beitrag verschiedener Gehirnregionen zur Sprachdekodierung zu bewerten.
Kurz gesagt: Wenn ein bestimmter Bereich für die Decodierung entscheidend ist, verringert das Blockieren des Elektrodensignals in diesem Bereich (d. h. das Setzen des Signals auf Null) die Genauigkeit der rekonstruierten Sprache (PCC-Wert).
Mit dieser Methode haben die Forscher die Verringerung des PCC-Werts gemessen, wenn jeder Bereich verschlossen war. Durch den Vergleich der kausalen und nicht-kausalen Modelle von ResNet- und Swin-Dekodierern wird festgestellt, dass der auditorische Kortex einen gr??eren Beitrag zum nicht-kausalen Modell leistet. Dies unterstreicht, dass in Echtzeit-Sprachdekodierungsanwendungen kausale Modelle verwendet werden müssen Durch die Echtzeit-Sprachdekodierung k?nnen wir Neurofeedback-Signale nicht nutzen.
Darüber hinaus ist der Beitrag des sensomotorischen Kortex, insbesondere des Bauchbereichs, sowohl in der rechten als auch in der linken Hemisph?re ?hnlich, was darauf hindeutet, dass es m?glich sein k?nnte, Nervenprothesen in der rechten Hemisph?re zu implantieren.
Schlussfolgerungen und inspirierender Ausblick
Forscher haben einen neuen Typ eines differenzierbaren Sprachsynthesizers entwickelt, der ein leichtes Faltungs-Neuronales Netzwerk verwenden kann, um Sprache in eine Reihe interpretierbarer Sprachparameter (wie Tonh?he, Lautst?rke, Formantenfrequenzen usw.) zu kodieren. ) und synthetisieren Sie die Sprache durch einen differenzierbaren Sprachsynthesizer neu.
Durch die Zuordnung neuronaler Signale zu diesen Sprachparametern haben die Forscher ein neuronales Sprachdekodierungssystem entwickelt, das gut interpretierbar und auf Situationen mit geringem Datenvolumen anwendbar ist und natürlich klingende Sprache erzeugen kann. Diese Methode ist bei allen Teilnehmern (insgesamt 48 Personen) in hohem Ma?e reproduzierbar, und die Forscher haben erfolgreich die Wirksamkeit der kausalen Dekodierung mithilfe von Faltungs- und Transformer-Architekturen (3D Swin) demonstriert, die beide rekurrenten Architekturen (LSTM) überlegen sind.
Dieses Framework kann hohe und niedrige r?umliche Abtastdichten verarbeiten und EEG-Signale aus der linken und rechten Hemisph?re verarbeiten, was ein starkes Potenzial für die Sprachdekodierung zeigt.
Die meisten früheren Studien berücksichtigten nicht die zeitliche Kausalit?t von Dekodierungsvorg?ngen in Echtzeit-Gehirn-Computer-Schnittstellenanwendungen. Viele nichtkausale Modelle basieren auf akustischen Rückmeldungssignalen. Die Analyse der Forscher zeigte, dass das nicht-kausale Modell haupts?chlich auf dem Beitrag des oberen Schl?fengyrus beruhte, w?hrend das kausale Modell diesen im Wesentlichen eliminierte. Forscher glauben, dass die Vielseitigkeit nicht-kausaler Modelle in Echtzeit-BCI-Anwendungen aufgrund der überm??igen Abh?ngigkeit von Rückkopplungssignalen begrenzt ist.
Einige Methoden versuchen, Feedback im Training zu vermeiden, beispielsweise die Dekodierung der imagin?ren Sprache des Probanden. Trotzdem verwenden die meisten Studien immer noch akausale Modelle und k?nnen Rückkopplungseffekte w?hrend des Trainings und der Schlussfolgerung nicht ausschlie?en. Darüber hinaus sind in der Literatur h?ufig verwendete rekurrente neuronale Netze in der Regel bidirektional, was zu nicht-kausalem Verhalten und Vorhersageverz?gerungen führt, w?hrend unsere Experimente zeigen, dass unidirektional trainierte rekurrente Netze die schlechteste Leistung erbringen.
Obwohl in der Studie keine Echtzeitdekodierung getestet wurde, erreichten die Forscher eine Latenz von weniger als 50 Millisekunden bei der Synthese von Sprache aus neuronalen Signalen, was die H?rverz?gerung kaum beeintr?chtigte und eine normale Sprachproduktion erm?glichte.
In der Studie wurde untersucht, ob eine h?here Abdeckungsdichte die Decodierungsleistung verbessern kann. Die Forscher fanden heraus, dass sowohl eine Gitterabdeckung mit niedriger als auch hoher Dichte eine hohe Decodierungsleistung erzielte (siehe Abbildung 3c). Darüber hinaus stellten die Forscher fest, dass sich die Decodierungsleistung bei Verwendung aller Elektroden nicht wesentlich von der Leistung bei Verwendung nur von Elektroden mit geringer Dichte unterschied (Abbildung 3d).
Dies beweist, dass der von den Forschern vorgeschlagene ECoG-Decoder Sprachparameter aus neuronalen Signalen für die Sprachrekonstruktion extrahieren kann, solange die peritemporale Abdeckung ausreichend ist, selbst bei Teilnehmern mit geringer Teilnehmerdichte. Ein weiterer bemerkenswerter Befund war die kortikale Struktur der rechten Hemisph?re und der Beitrag des rechten peritemporalen Kortex zur Sprachdekodierung. Obwohl einige frühere Studien einen m?glichen Beitrag der rechten Hemisph?re zur Dekodierung von Vokalen und S?tzen gezeigt haben, liefern unsere Ergebnisse Hinweise auf eine robuste phonologische Repr?sentation in der rechten Hemisph?re.
Die Forscher erw?hnten auch einige Einschr?nkungen des aktuellen Modells, wie z. B. den Decodierungsprozess, der Sprachtrainingsdaten gepaart mit ECoG-Aufzeichnungen erfordert, was m?glicherweise nicht auf Aphasiker anwendbar ist. In Zukunft hoffen die Forscher auch, Modellarchitekturen zu entwickeln, die mit Nicht-Grid-Daten umgehen und multimodale EEG-Daten mehrerer Patienten besser nutzen k?nnen.
Der erste Autor dieses Artikels: Xupeng Chen, Ran Wang, korrespondierender Autor: Adeen Flinker.
Finanzielle Unterstützung: National Science Foundation unter Grant No. IIS-1912286, 2309057 (Y.W., A.F.) und National Institute of Health R01NS109367, R01NS115929, R01DC018805 (A.F.).
Weitere Informationen zur Kausalit?t bei der Dekodierung neuronaler Sprache finden Sie in einem anderen Artikel der Autoren ?Distributed Feedforward and Feedback Cortical Processing Supports Human Language Production“: https://www.pnas.org/doi /10.1073 /pnas.2300255120
Quelle: Brain Computer Interface Community
Das obige ist der detaillierte Inhalt vonKI unterstützt die Forschung an Gehirn-Computer-Schnittstellen, die bahnbrechende neuronale Sprachdekodierungstechnologie der New York University, ver?ffentlicht in der Unterzeitschrift ?Nature'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Wie lautet die Codenummer von Bitcoin? Welcher Codestil ist Bitcoin?
Jul 22, 2025 pm 09:51 PM
Wie lautet die Codenummer von Bitcoin? Welcher Codestil ist Bitcoin?
Jul 22, 2025 pm 09:51 PM
Als Pionier in der digitalen Welt standen der einzigartige Codename und die zugrunde liegende Technologie immer im Mittelpunkt der Aufmerksamkeit der Menschen. Sein Standardcode ist BTC, auch als XBT auf bestimmten Plattformen bekannt, die internationale Standards entsprechen. Aus technischer Sicht ist Bitcoin kein einziger Codestil, sondern ein riesiges und ausgeklügeltes Open -Source -Softwareprojekt. Sein Kerncode ist haupts?chlich in C geschrieben und enth?lt Kryptographie, verteilte Systeme und Wirtschaftsgrunds?tze, damit jeder seinen Code anzeigen, überprüfen und beitragen kann.
 Was ist nutzlose Münze? überblick über nutzlose W?hrungsnutzung, herausragende Merkmale und zukünftiges Wachstumspotenzial
Jul 24, 2025 pm 11:54 PM
Was ist nutzlose Münze? überblick über nutzlose W?hrungsnutzung, herausragende Merkmale und zukünftiges Wachstumspotenzial
Jul 24, 2025 pm 11:54 PM
Was sind die wichtigsten Punkte des Katalogs? UNSELESSCOIN: übersicht und wichtige Funktionen von nutzloser Funktionen von nutzlosen nutzlosen Nutzlosen (nutzlos) zukünftige Preisaussichten: Was wirkt sich auf den Preis von nutzloser Coin im Jahr 2025 und darüber hinaus aus? Zukünftige Preisausblicke Kernfunktionen und Wichtigkeiten von nutzlosen (nutzlos) Wie nutzlos (nutzlos) funktioniert und wie er nützt, wie nutzlos die wesentlichen Vorteile für die Unternehmens -Partnerschaften von Nutzelesscoin wie sie zusammenarbeiten
 So setzen Sie Umgebungsvariablen in der PHP -Umgebung Beschreibung des Hinzufügens von PHP -Ausführungsumgebungsvariablen
Jul 25, 2025 pm 08:33 PM
So setzen Sie Umgebungsvariablen in der PHP -Umgebung Beschreibung des Hinzufügens von PHP -Ausführungsumgebungsvariablen
Jul 25, 2025 pm 08:33 PM
Es gibt drei Hauptmethoden, um Umgebungsvariablen in PHP festzulegen: 1. Globale Konfiguration über php.ini; 2. durch einen Webserver (z. B. SetEnv von Apache oder FastCGI_Param von Nginx); 3. Verwenden Sie die Funktion Putenv () in PHP -Skripten. Unter ihnen eignet sich Php.ini für globale und selten ?ndernde Konfigurationen. Die Webserverkonfiguration eignet sich für Szenarien, die isoliert werden müssen, und Putenv () ist für tempor?re Variablen geeignet. Die Persistenz -Richtlinien umfassen Konfigurationsdateien (z. B. Php.ini oder Webserverkonfiguration), .env -Dateien werden mit der DOTENV -Bibliothek und dynamische Injektion von Variablen in CI/CD -Prozessen geladen. Sicherheitsmanagement sensible Informationen sollten hart codiert werden, und es wird empfohlen.
 Abgeschlossener Python Blockbuster Online -Eingang Python Free Fertig -Website -Sammlung
Jul 23, 2025 pm 12:36 PM
Abgeschlossener Python Blockbuster Online -Eingang Python Free Fertig -Website -Sammlung
Jul 23, 2025 pm 12:36 PM
Dieser Artikel hat mehrere "Fertig" -Projekt-Websites von Python und "Blockbuster" -Portalen "Blockbuster" für Sie ausgew?hlt. Egal, ob Sie nach Entwicklungsinspiration suchen, den Quellcode auf Master-Ebene beobachten und lernen oder Ihre praktischen F?higkeiten systematisch verbessern, diese Plattformen sind nicht zu übersehen und k?nnen Ihnen helfen, schnell zu einem Python-Meister zu werden.
 So erstellen Sie eine PHP NGINX -Umgebung mit macOS, um die Kombination von NGINX- und PHP -Diensten zu konfigurieren
Jul 25, 2025 pm 08:24 PM
So erstellen Sie eine PHP NGINX -Umgebung mit macOS, um die Kombination von NGINX- und PHP -Diensten zu konfigurieren
Jul 25, 2025 pm 08:24 PM
Die Kernrolle von Homebrew bei der Konstruktion der Mac -Umgebung besteht darin, die Installation und Verwaltung der Software zu vereinfachen. 1. Homebrew verarbeitet automatisch Abh?ngigkeiten und verkapselt komplexe Kompilierungs- und Installationsprozesse in einfache Befehle. 2. Bietet ein einheitliches Softwarepaket -?kosystem, um die Standardisierung des Software -Installationsorts und der Konfiguration zu gew?hrleisten. 3. Integriert Service -Management -Funktionen und kann Dienste leicht über Brewservices starten und stoppen. 4. Bequemes Software -Upgrade und -wartung und verbessert die Sicherheit und Funktionalit?t der Systeme.
 KOSTENLOSER Eingang zur Website Fertiger Produktressourcen. Komplettes Vue -Ferd -Produkt wird dauerhaft online angezeigt
Jul 23, 2025 pm 12:39 PM
KOSTENLOSER Eingang zur Website Fertiger Produktressourcen. Komplettes Vue -Ferd -Produkt wird dauerhaft online angezeigt
Jul 23, 2025 pm 12:39 PM
In diesem Artikel wurde eine Reihe von Fertigproduktressourcen-Websites der Top-Ebene für VUE-Entwickler und -Lernende ausgew?hlt. über diese Plattformen k?nnen Sie massive qualitativ hochwertige Vue-Projekte kostenlos online st?bern, lernen und sogar wiederverwenden, wodurch Ihre Entwicklungsf?higkeiten und Projektpraxisfunktionen schnell verbessert werden.
 Solana Sommer: Entwicklerereignisse, Meme -Münzen und die n?chste Welle
Jul 25, 2025 am 07:54 AM
Solana Sommer: Entwicklerereignisse, Meme -Münzen und die n?chste Welle
Jul 25, 2025 am 07:54 AM
Solanas starke Erholung: Kann der Anstieg der Entwickler und der Meme -Münz -Karneval -Fahrt dauern? Eingehende Interpretation von Trends Solana feiert ein Comeback! Nach einer Zeit der Stille ist die ?ffentliche Kette verjüngt, der Münzpreis steigt weiter und die Entwicklungsgemeinschaft wird immer lebhafter. Aber wo ist die wahre treibende Kraft für diesen Abpraller? Ist es nur ein Blitz in der Pfanne? Lassen Sie uns in die aktuellen Kerntrends von Solana eingehen: Entwickler?kologie, Meme -Münz -Fanatismus und allgemeine ?kologische Expansion. Nach dem Anstieg der Münzpreise: Real Development -Aktivit?ten haben sich in letzter Zeit erholt. SOL -Preise sind zum ersten Mal seit Juni auf über 200 US -Dollar zurückgekehrt, was zu heftigen Diskussionen auf dem Markt geführt hat. Dies ist nicht unbegründet - laut Santimentdaten haben die Entwickler in den letzten zwei Monaten ein neues Hoch erreicht. Das
 So konfigurieren Sie Windows 11 Firewall so, dass PHP -Dienste PHP -Port ge?ffnet und sichere Einstellungen ge?ffnet und sichern k?nnen
Jul 23, 2025 pm 06:27 PM
So konfigurieren Sie Windows 11 Firewall so, dass PHP -Dienste PHP -Port ge?ffnet und sichere Einstellungen ge?ffnet und sichern k?nnen
Jul 23, 2025 pm 06:27 PM
Damit PHP -Dienste die Windows 11 -Firewall durchlaufen k?nnen, müssen Sie eingehende Regeln erstellen, um den entsprechenden Port oder das entsprechende Programm zu ?ffnen. 1. Bestimmen Sie den Port, den PHP tats?chlich zuh?rt. Wenn der integrierte Server mit PHP-SlocalHost: 8000 gestartet wird, betr?gt der Port 8000. Wenn Sie Apache oder IIS verwenden, ist es normalerweise 80 oder 443. 3. W?hlen Sie Verbindungen zulassen, überprüfen Sie die entsprechende Netzwerkkonfigurationsdatei, benennen Sie die Regeln und fügen Sie eine Beschreibung hinzu. Die IP -Adressen, die zugreifen dürfen, wie z. B. lokales Netzwerk oder spezifisches IP, k?nnen durch den Umfang eingeschr?nkt werden. Sicherheit
