
 Technologie-Peripherieger?te
KI
Gro?e Modelle k?nnen ebenfalls in Scheiben geschnitten werden, und Microsoft SliceGPT erh?ht die Recheneffizienz von LLAMA-2 erheblich
Technologie-Peripherieger?te
KI
Gro?e Modelle k?nnen ebenfalls in Scheiben geschnitten werden, und Microsoft SliceGPT erh?ht die Recheneffizienz von LLAMA-2 erheblich
Gro?e Modelle k?nnen ebenfalls in Scheiben geschnitten werden, und Microsoft SliceGPT erh?ht die Recheneffizienz von LLAMA-2 erheblich
Jan 31, 2024 am 11:39 AM
Gro? angelegte Sprachmodelle (LLM) verfügen normalerweise über Milliarden von Parametern und werden auf Billionen von Token trainiert. Die Schulung und Bereitstellung solcher Modelle ist jedoch sehr teuer. Um den Rechenaufwand zu reduzieren, werden h?ufig verschiedene Modellkomprimierungstechniken eingesetzt.
Diese Modellkomprimierungstechniken k?nnen im Allgemeinen in vier Kategorien unterteilt werden: Destillation, Tensorzerlegung (einschlie?lich Faktorisierung mit niedrigem Rang), Bereinigung und Quantisierung. Pruning-Methoden gibt es schon seit einiger Zeit, aber viele erfordern nach dem Pruning eine Feinabstimmung der Wiederherstellung (Recovery Fine-Tuning, RFT), um die Leistung aufrechtzuerhalten, was den gesamten Prozess kostspielig und schwierig zu skalieren macht.
Forscher der ETH Zürich und von Microsoft haben eine L?sung für dieses Problem namens SliceGPT vorgeschlagen. Die Kernidee dieser Methode besteht darin, die Einbettungsdimension des Netzwerks durch L?schen von Zeilen und Spalten in der Gewichtsmatrix zu reduzieren, um die Leistung des Modells aufrechtzuerhalten. Das Aufkommen von SliceGPT bietet eine wirksame L?sung für dieses Problem.
Die Forscher stellten fest, dass sie mit SliceGPT gro?e Modelle in wenigen Stunden mit einer einzigen GPU komprimieren konnten und so auch ohne RFT eine wettbewerbsf?hige Leistung bei Generierungs- und Downstream-Aufgaben aufrechterhielten. Derzeit wurde die Forschung vom ICLR 2024 akzeptiert.

- Papiertitel: SLICEGPT: KOMPRIMIEREN SIE GRO?E SPRACHENMODELLE DURCH L?SCHEN VON ZEILEN UND SPALTEN
- Papierlink: https://arxiv.org/pdf/2401. .15024.pdf
Die Pruning-Methode funktioniert, indem sie bestimmte Elemente der Gewichtsmatrix im LLM auf Null setzt und umgebende Elemente zum Ausgleich selektiv aktualisiert. Dies führt zu einem sp?rlichen Muster, das einige Gleitkommaoperationen im Vorw?rtsdurchlauf des neuronalen Netzwerks überspringt und so die Recheneffizienz verbessert.
Der Grad der Sparsity und der Sparsity-Modus sind Faktoren, die die relative Verbesserung der Rechengeschwindigkeit bestimmen. Wenn der Sparse-Modus sinnvoller ist, bringt er mehr Rechenvorteile. Im Gegensatz zu anderen Beschneidungsmethoden beschneidet SliceGPT, indem es ganze Zeilen oder Spalten der Gewichtsmatrix abschneidet (abschneidet!). Vor der Resektion durchl?uft das Netzwerk eine Transformation, die die Vorhersagen unver?ndert l?sst, aber leicht beeinflusste Scherprozesse zul?sst.
Die Folge ist, dass die Gewichtsmatrix reduziert, die Signalübertragung geschw?cht und die Dimension des neuronalen Netzwerks verringert wird.
Abbildung 1 unten vergleicht die SliceGPT-Methode mit vorhandenen Sparsity-Methoden.
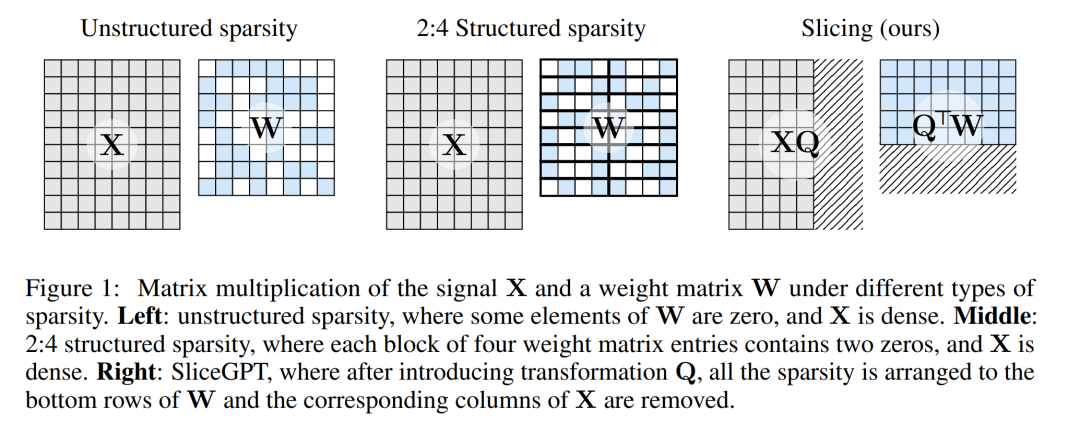
Durch umfangreiche Experimente haben die Autoren herausgefunden, dass SliceGPT bis zu 25 % der Modellparameter (einschlie?lich Einbettungen) für LLAMA-2 70B-, OPT 66B- und Phi-2-Modelle entfernen kann, w?hrend 99 % davon beibehalten werden dichte Modelle, 99 % bzw. 90 % Null-Stichproben-Aufgabenleistung.
Von SliceGPT verarbeitete Modelle k?nnen auf weniger GPUs und schneller ausgeführt werden, ohne dass zus?tzliche Codeoptimierung erforderlich ist: Auf einer 24-GB-GPU für Endverbraucher verglich der Autor die gesamte Inferenzberechnung von LLAMA-2 mit 70?B. Der Betrag wurde auf 64?% reduziert. beim dichten Modell; bei der 40-GB-A100-GPU wurde sie auf 66 % reduziert.
Darüber hinaus schlugen sie auch ein neues Konzept vor, die rechnerische Invarianz in Transformer-Netzwerken, das SliceGPT erm?glicht.
SliceGPT im Detail
Die SliceGPT-Methode basiert auf der rechnerischen Invarianz, die der Transformer-Architektur innewohnt. Das bedeutet, dass Sie eine orthogonale Transformation auf die Ausgabe einer Komponente anwenden und diese dann in der n?chsten Komponente rückg?ngig machen k?nnen. Die Autoren stellten fest, dass zwischen Netzwerkbl?cken durchgeführte RMSNorm-Operationen keinen Einfluss auf die Transformation haben: Diese Operationen sind kommutativ.
In dem Artikel stellt der Autor zun?chst vor, wie man mit RMSNorm-Verbindungen Invarianz in einem Transformer-Netzwerk erreicht, und erkl?rt dann, wie man ein mit LayerNorm-Verbindungen trainiertes Netzwerk in RMSNorm umwandelt. Als n?chstes stellen sie die Methode vor, die Hauptkomponentenanalyse (PCA) zu verwenden, um die Transformation jeder Schicht zu berechnen und so das Signal zwischen Bl?cken auf seine Hauptkomponenten zu projizieren. Schlie?lich zeigen sie, wie das Entfernen kleinerer Hauptkomponenten dem Abschneiden von Zeilen oder Spalten des Netzwerks entspricht.
Rechnerinvarianz des Transformer-Netzwerks
Verwenden Sie Q, um die orthogonale Matrix darzustellen: 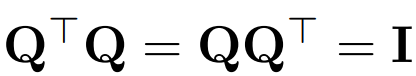
- Beachten Sie, dass das Multiplizieren eines Vektors
Angenommen, X_? ist die Ausgabe eines Transformatorblocks. Nach der Verarbeitung durch RMSNorm wird sie in Form von RMSNorm (X_?) in den n?chsten Block eingegeben. Wenn Sie eine lineare Schicht mit einer orthogonalen Matrix Q vor RMSNorm und Q^? nach RMSNorm einfügen, bleibt das Netzwerk unver?ndert, da jede Zeile der Signalmatrix mit Q multipliziert, normalisiert und mit Q^ ? multipliziert wird. Hier haben wir:
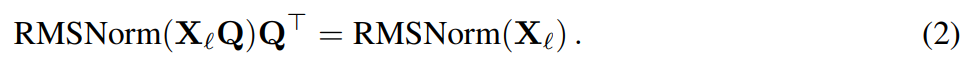
Da nun jeder Aufmerksamkeits- oder FFN-Block im Netzwerk eine lineare Operation am Ein- und Ausgang ausführt, kann die zus?tzliche Operation Q in die lineare Schicht des Moduls aufgenommen werden. Da das Netzwerk Restverbindungen enth?lt, muss Q auch auf die Ausg?nge aller vorherigen Schichten (bis zur Einbettung) und aller nachfolgenden Schichten (bis zum LM-Kopf) angewendet werden.
Eine invariante Funktion bezieht sich auf eine Funktion, deren Eingabetransformation keine ?nderung der Ausgabe verursacht. Im Beispiel dieses Artikels kann jede orthogonale Transformation Q auf die Gewichte des Transformators angewendet werden, ohne das Ergebnis zu ?ndern, sodass die Berechnung in jedem Transformationszustand durchgeführt werden kann. Die Autoren nennen diese rechnerische Invarianz und definieren sie im folgenden Satz.
Theorem 1: Sei 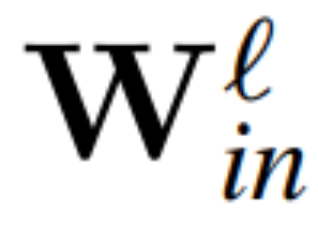 und
und 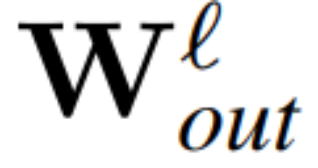 die Gewichtsmatrix der linearen Schicht des ?-ten Blocks des Transformatornetzwerks, die durch RMSNorm verbunden ist,
die Gewichtsmatrix der linearen Schicht des ?-ten Blocks des Transformatornetzwerks, die durch RMSNorm verbunden ist, 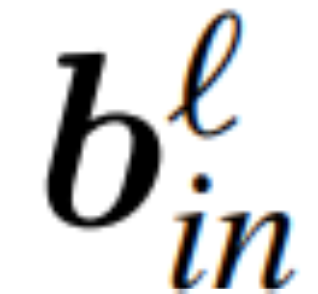 und
und 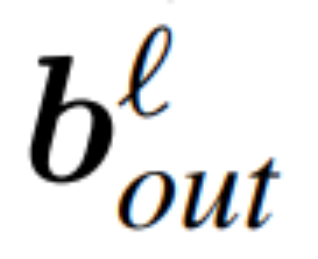 seien die entsprechenden Bias (falls vorhanden), W_embd und W_head seien die Einbettungsmatrix und Kopfmatrix. Angenommen, Q ist eine orthogonale Matrix mit der Dimension D, dann entspricht das folgende Netzwerk dem ursprünglichen Transformatornetzwerk:
seien die entsprechenden Bias (falls vorhanden), W_embd und W_head seien die Einbettungsmatrix und Kopfmatrix. Angenommen, Q ist eine orthogonale Matrix mit der Dimension D, dann entspricht das folgende Netzwerk dem ursprünglichen Transformatornetzwerk:
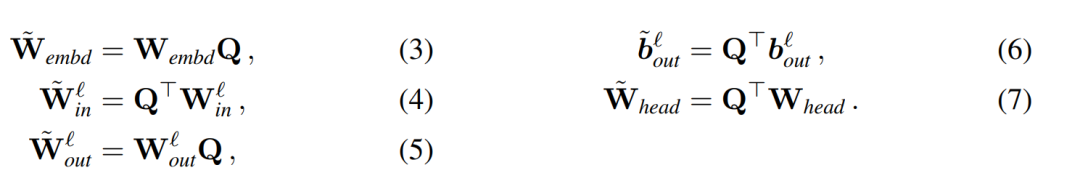
Das Kopieren der Eingangsvorspannung und der Kopfvorspannung:
kann über den Algorithmus erfolgen 1, um zu beweisen, dass das konvertierte Netzwerk dieselben Ergebnisse berechnet wie das ursprüngliche Netzwerk.
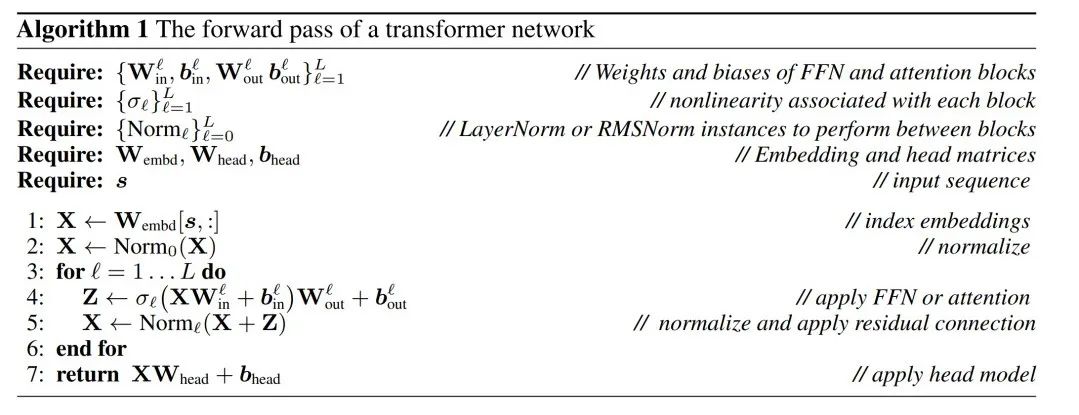
LayerNorm Transformer kann in RMSNorm umgewandelt werden
Transformer Die rechnerische Invarianz des Netzwerks gilt nur für mit RMSNorm verbundene Netzwerke. Bevor ein Netzwerk mit LayerNorm verarbeitet wird, konvertieren die Autoren das Netzwerk zun?chst in RMSNorm, indem sie lineare Bl?cke von LayerNorm in benachbarte Bl?cke absorbieren.
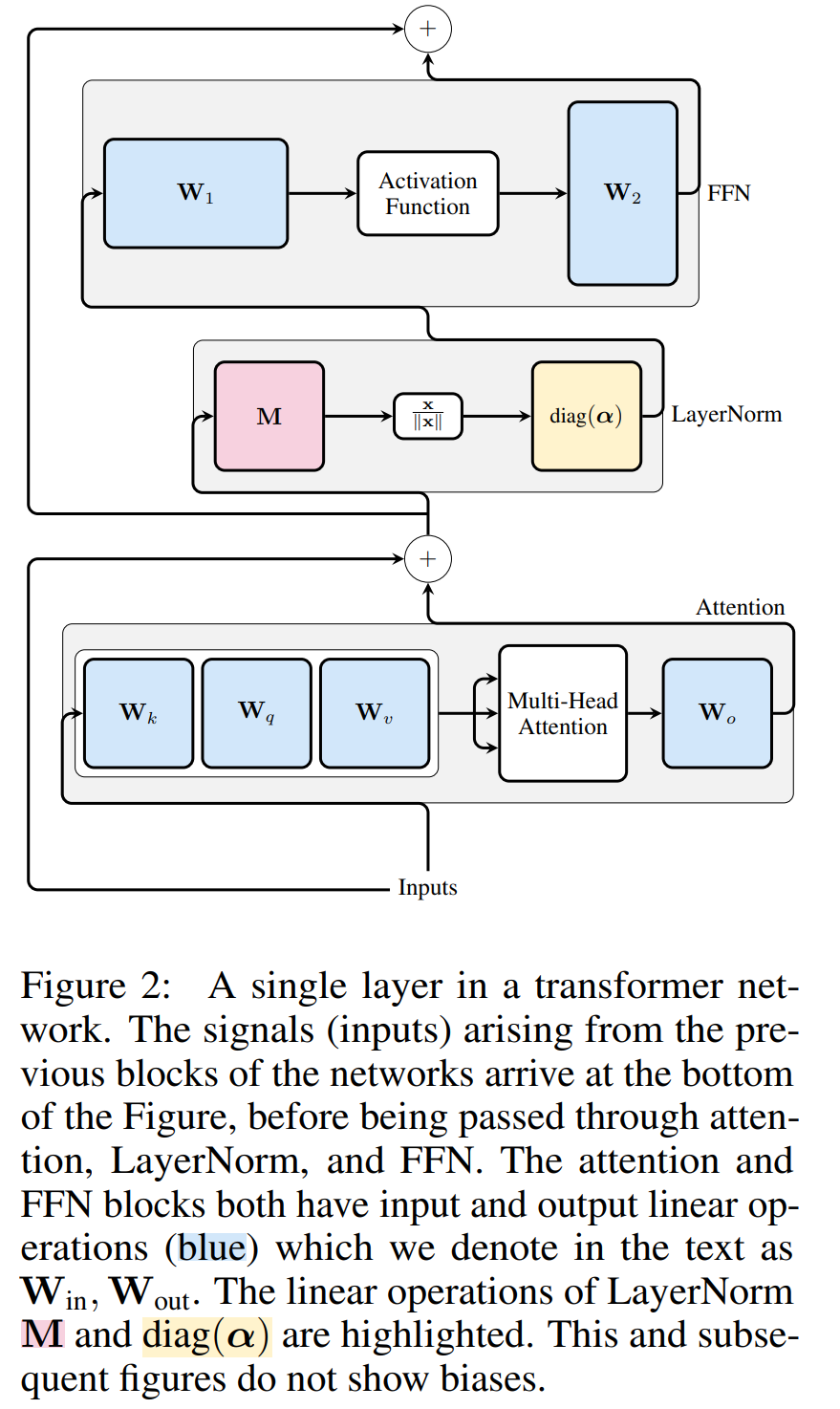
Abbildung 3 zeigt diese Transformation des Transformer-Netzwerks (siehe Abbildung 2). In jedem Block multiplizieren die Autoren die Ausgabematrix W_out mit der mittleren Subtraktionsmatrix M, die die mittlere Subtraktion in der nachfolgenden LayerNorm berücksichtigt. Die Eingabematrix W_in wird mit dem Anteil des vorherigen LayerNorm-Blocks vormultipliziert. Die Einbettungsmatrix W_embd muss einer mittleren Subtraktion unterzogen werden und W_head muss entsprechend dem Anteil der letzten LayerNorm neu skaliert werden. Dies ist eine einfache ?nderung der Reihenfolge der Vorg?nge und hat keinen Einfluss auf die Netzwerkausgabe.
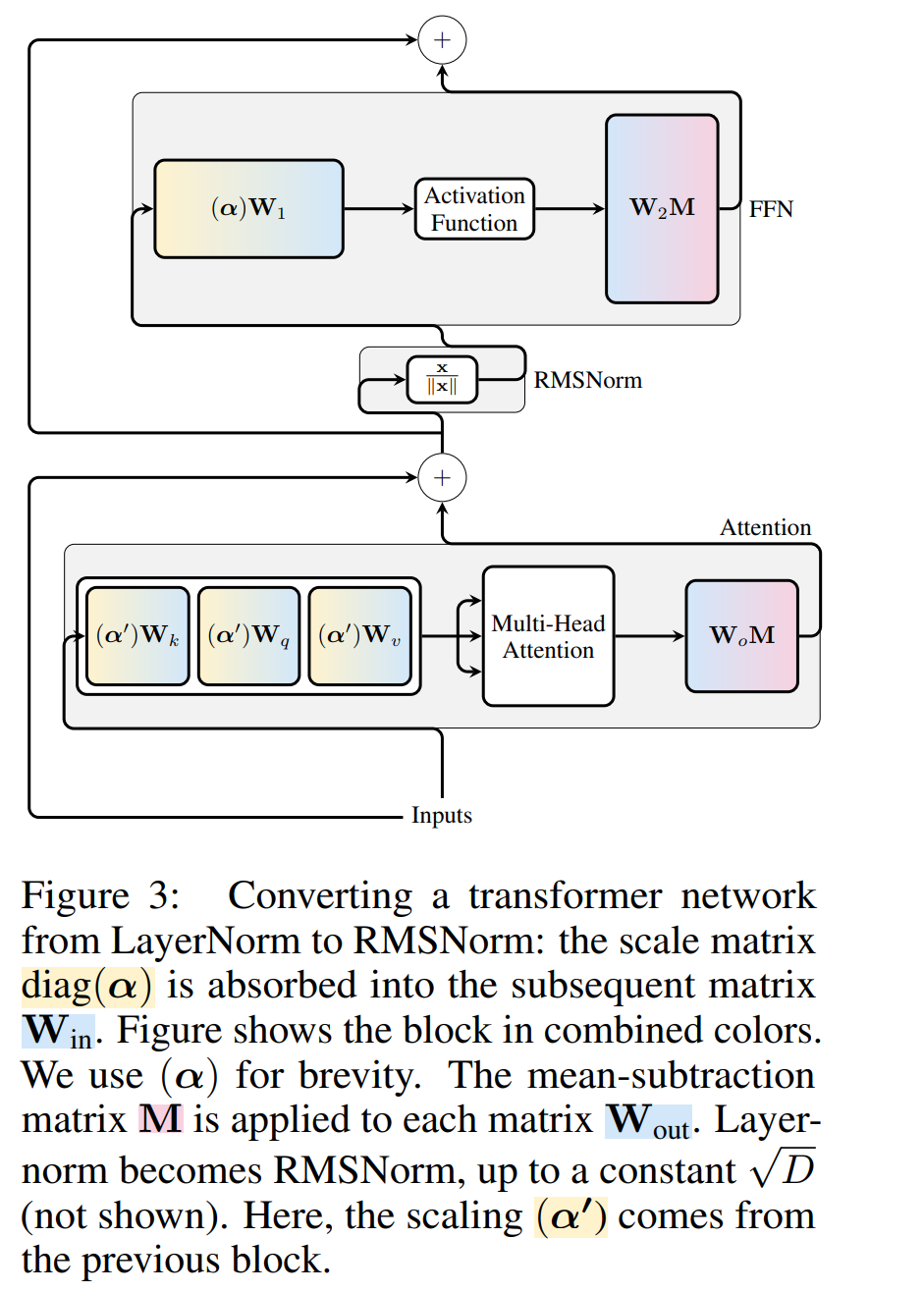
Transformation jedes Blocks
Da nun jede LayerNorm im Transformator in RMSNorm konvertiert wurde, kann ein beliebiges Q ausgew?hlt werden, um das Modell zu ?ndern. Der ursprüngliche Plan des Autors bestand darin, Signale aus dem Modell zu sammeln, diese Signale zum Aufbau einer orthogonalen Matrix zu verwenden und dann Teile des Netzwerks zu l?schen. Sie stellten schnell fest, dass die Signale von verschiedenen Bl?cken im Netzwerk nicht ausgerichtet waren, sodass sie auf jeden Block eine andere orthogonale Matrix oder Q_? anwenden mussten.
Wenn die in jedem Block verwendete orthogonale Matrix unterschiedlich ist, ?ndert sich das Modell nicht. Die Beweismethode ist dieselbe wie bei Satz 1, mit Ausnahme von Zeile 5 von Algorithmus 1. Hier sieht man, dass der Ausgang der Restverbindung und der Block die gleiche Drehung haben müssen. Um dieses Problem zu l?sen, modifiziert der Autor die Restverbindung, indem er den Rest linear transformiert. 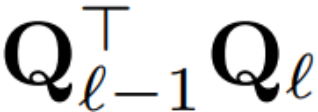
Abbildung 4 zeigt, wie unterschiedliche Drehungen an verschiedenen Bl?cken durchgeführt werden, indem zus?tzliche lineare Operationen an der Restverbindung ausgeführt werden. Im Gegensatz zu ?nderungen an der Gewichtsmatrix k?nnen diese zus?tzlichen Operationen nicht vorberechnet werden und fügen dem Modell einen geringen Overhead (D × D) hinzu. Dennoch sind diese Vorg?nge erforderlich, um das Modell wegzuschneiden, und Sie k?nnen sehen, dass die Gesamtgeschwindigkeit tats?chlich zunimmt.
Zur Berechnung der Matrix Q_? verwendete der Autor PCA. Sie w?hlen einen Kalibrierungsdatensatz aus dem Trainingssatz aus, lassen ihn durch das Modell laufen (nachdem sie die LayerNorm-Operation in RMSNorm konvertiert haben) und extrahieren die orthogonale Matrix für diese Ebene. Genauer gesagt, wenn sie die Ausgabe des transformierten Netzwerks verwenden, um die orthogonale Matrix der n?chsten Schicht zu berechnen. Genauer gesagt, wenn 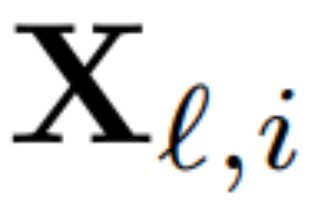 die Ausgabe des ?-ten RMSNorm-Moduls für die i-te Sequenz im Kalibrierungsdatensatz ist, berechnen Sie:
die Ausgabe des ?-ten RMSNorm-Moduls für die i-te Sequenz im Kalibrierungsdatensatz ist, berechnen Sie: 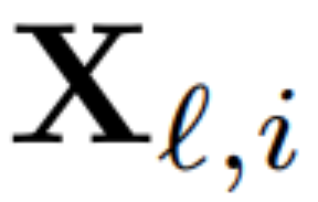

und setzen Sie Q_? als abnehmenden Eigenvektor von C_? in Eigenwerten Sortieren.成 Entfernung 分 Das Ziel der Hauptkomponentenanalyse besteht darin, die Datenmatrix eine kleine D × D-Deletionsmatrix (die D kleine Spalten der D × D-Homotopenmatrix enth?lt), die zum L?schen einiger Spalten auf der linken Seite der Matrix verwendet wird. Die Rekonstruktion ist L_2-optimal in dem Sinne, dass QD eine lineare Karte ist, die minimiert.
Beim Anwenden von PCA auf die Interblock-Signalmatrix In der obigen Operation wurde diese Matrix mit Q multipliziert. Der Autor hat die Zeile von W_in und die Spalten von W_out und W_embd entfernt. Sie entfernten auch die Zeilen und Spalten der Matrix , die in die Restverbindung eingefügt wurden (siehe Abbildung 4). Experimentelle Ergebnisse Datensatz. Tabelle 1 zeigt die Komplexit?t, die nach verschiedenen Bereinigungsstufen des Modells erhalten bleibt. Im Vergleich zum LLAMA-2-Modell zeigte SliceGPT bei der Anwendung auf das OPT-Modell eine überlegene Leistung, was mit den Spekulationen des Autors auf der Grundlage der Analyse des Modellspektrums übereinstimmt.
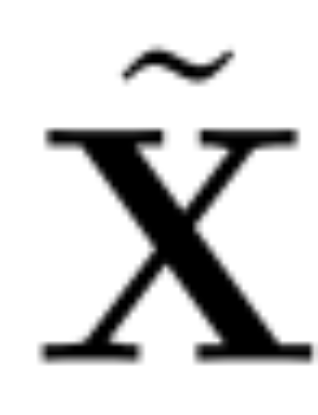 Die Leistung von SliceGPT verbessert sich mit zunehmender Modellgr??e. Der SparseGPT 2:4-Modus schneidet bei allen Modellen der LLAMA-2-Serie mit 25 % Clipping schlechter ab als SliceGPT. Für OPT kann festgestellt werden, dass die Sparsit?t des Modells mit einem Resektionsverh?ltnis von 30 % in allen Modellen mit Ausnahme des 2,7B-Modells besser ist als die von 2:4.
Die Leistung von SliceGPT verbessert sich mit zunehmender Modellgr??e. Der SparseGPT 2:4-Modus schneidet bei allen Modellen der LLAMA-2-Serie mit 25 % Clipping schlechter ab als SliceGPT. Für OPT kann festgestellt werden, dass die Sparsit?t des Modells mit einem Resektionsverh?ltnis von 30 % in allen Modellen mit Ausnahme des 2,7B-Modells besser ist als die von 2:4.
Zero-Sample-Aufgabe
Der Autor verwendete fünf Aufgaben: PIQA, WinoGrande, HellaSwag, ARC-e und ARCc, um die Leistung von SliceGPT bei der Zero-Sample-Aufgabe zu bewerten. Als Standard verwendete er LM Evaluation Harness im Bewertungsparameter.
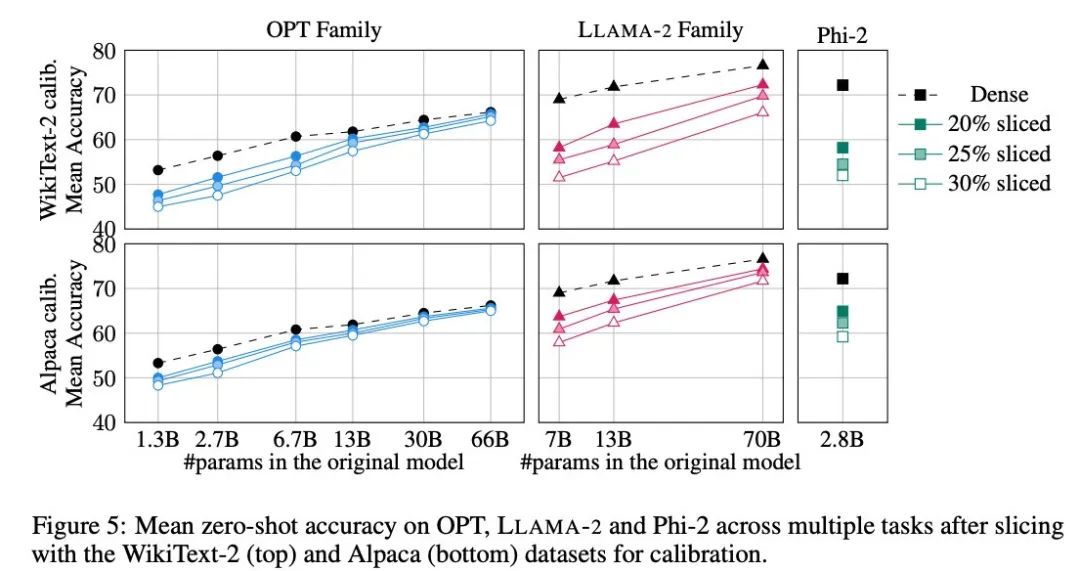
Abbildung 5 zeigt die durchschnittlichen Ergebnisse, die das ma?geschneiderte Modell bei den oben genannten Aufgaben erzielt. Die obere Reihe der Abbildung zeigt die durchschnittliche Genauigkeit von SliceGPT in WikiText-2 und die untere Reihe zeigt die durchschnittliche Genauigkeit von SliceGPT in Alpaca. Aus den Ergebnissen lassen sich ?hnliche Schlussfolgerungen wie bei der Generierungsaufgabe ziehen: Das OPT-Modell l?sst sich besser an die Komprimierung anpassen als das LLAMA-2-Modell, und je gr??er das Modell, desto weniger offensichtlich ist der Rückgang der Genauigkeit nach dem Bereinigen.
Der Autor hat die Wirkung von SliceGPT an einem kleinen Modell wie Phi-2 getestet. Das getrimmte Phi-2-Modell weist eine vergleichbare Leistung wie das getrimmte LLAMA-2 7B-Modell auf. Die gr??ten OPT- und LLAMA-2-Modelle k?nnen effizient komprimiert werden, und SliceGPT verliert nur wenige Prozentpunkte, wenn 30 % aus dem 66B-OPT-Modell entfernt werden.
Der Autor führte auch ein Experiment zur Wiederherstellung der Feinabstimmung (RFT) durch. Eine kleine Anzahl von RFTs wurde mit LoRA an den getrimmten LLAMA-2- und Phi-2-Modellen durchgeführt.
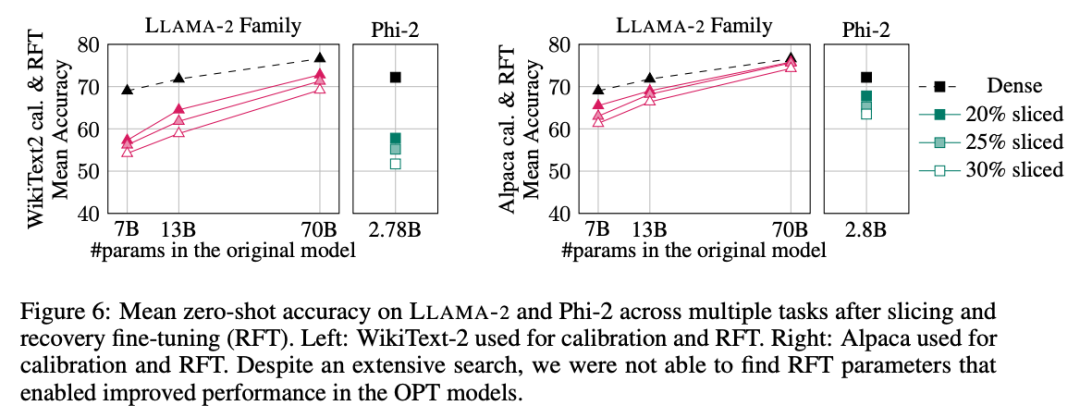
Die experimentellen Ergebnisse sind in Abbildung 6 dargestellt. Es l?sst sich feststellen, dass es erhebliche Unterschiede in den RFT-Ergebnissen zwischen den WikiText-2- und Alpaca-Datens?tzen gibt und das Modell im Alpaca-Datensatz eine bessere Leistung zeigt. Die Autoren glauben, dass der Grund für den Unterschied darin liegt, dass die Aufgaben im Alpaca-Datensatz n?her an den Basisaufgaben liegen.
Für das gr??te LLAMA-2 70B-Modell betr?gt die endgültige durchschnittliche Genauigkeit im Alpaka-Datensatz nach 30 % Beschneidung und Durchführung von RFT 74,3 % und die Genauigkeit des ursprünglichen dichten Modells 76,6 %. Das ma?geschneiderte Modell LLAMA-2 70B beh?lt etwa 51,6B-Parameter bei und sein Durchsatz ist deutlich verbessert.
Der Autor stellte au?erdem fest, dass Phi-2 die ursprüngliche Genauigkeit des beschnittenen Modells im WikiText-2-Datensatz nicht wiederherstellen konnte, aber einige Prozentpunkte der Genauigkeit im Alpaka-Datensatz wiederherstellen konnte. Phi-2, um 25 % gekürzt und RFTed, weist im Alpaca-Datensatz eine durchschnittliche Genauigkeit von 65,2 % auf, und die Genauigkeit des ursprünglichen dichten Modells betr?gt 72,2 %. Das getrimmte Modell beh?lt 2,2B-Parameter und 90,3 % der Genauigkeit des 2,8B-Modells. Dies zeigt, dass selbst kleine Sprachmodelle effektiv beschnitten werden k?nnen.
Benchmark-Durchsatz
Im Gegensatz zu herk?mmlichen Beschneidungsmethoden führt SliceGPT (strukturierte) Sparsit?t in der Matrix X ein: Die gesamte Spalte X wird abgeschnitten, wodurch die Einbettungsdimension verringert wird. Dieser Ansatz erh?ht sowohl die Rechenkomplexit?t (Anzahl der Gleitkommaoperationen) des SliceGPT-Komprimierungsmodells als auch die Effizienz der Datenübertragung.
Stellen Sie auf einer 80-GB-H100-GPU die Sequenzl?nge auf 128 ein und verdoppeln Sie die Sequenzl?nge stapelweise, um den maximalen Durchsatz zu ermitteln, bis der GPU-Speicher ersch?pft ist oder der Durchsatz sinkt. Die Autoren verglichen den Durchsatz von auf 25 % und 50 % bereinigten Modellen mit dem ursprünglichen dichten Modell auf einer 80-GB-H100-GPU. Modelle, die um 25 % verkleinert wurden, erzielten eine bis zu 1,55-fache Durchsatzverbesserung.
Mit 50 % Clipping erreicht das gr??te Modell mit einer einzigen GPU erhebliche Durchsatzsteigerungen von 3,13x und 1,87x. Dies zeigt, dass der Durchsatz des bereinigten Modells das 6,26-fache bzw. das 3,75-fache des ursprünglichen dichten Modells erreicht, wenn die Anzahl der GPUs festgelegt ist.
Nach 50 % Bereinigung ist die von SliceGPT in WikiText2 beibehaltene Komplexit?t zwar schlechter als bei SparseGPT 2:4, der Durchsatz übertrifft jedoch die SparseGPT-Methode bei weitem. Bei Modellen der Gr??e 13B kann sich der Durchsatz auch bei kleineren Modellen auf Consumer-GPUs mit weniger Speicher verbessern.
Inferenzzeit
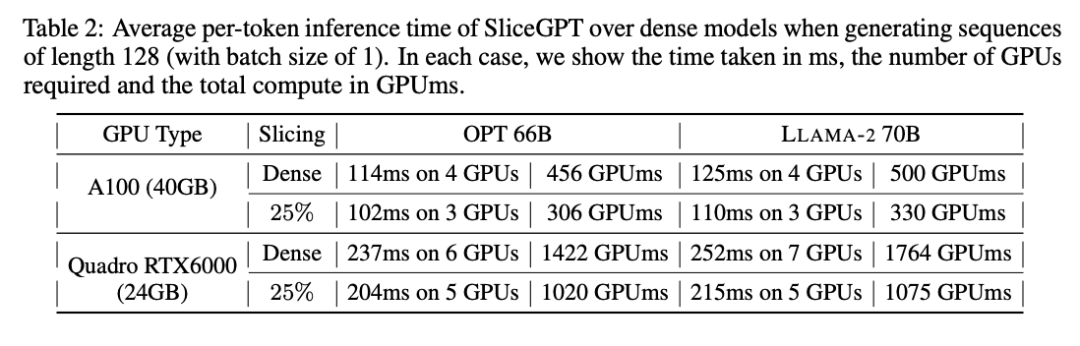
Der Autor untersuchte auch die End-to-End-Laufzeit des mit SliceGPT komprimierten Modells. Tabelle 2 vergleicht die Zeit, die zum Generieren eines einzelnen Tokens für die Modelle OPT 66B und LLAMA-2 70B auf Quadro RTX6000- und A100-GPUs erforderlich ist. Es l?sst sich feststellen, dass bei der RTX6000-GPU nach der Reduzierung des Modells um 25 % die Inferenzgeschwindigkeit um 16–17 % erh?ht wird; bei der A100-GPU wird die Geschwindigkeit um 11–13 % erh?ht. Für LLAMA-2 70B ist der Rechenaufwand mit der RTX6000-GPU im Vergleich zum ursprünglichen dichten Modell um 64 % reduziert. Der Autor führt diese Verbesserung darauf zurück, dass SliceGPT die ursprüngliche Gewichtsmatrix durch eine kleinere Gewichtsmatrix ersetzt und dichte Kernel verwendet, was mit anderen Bereinigungsschemata nicht erreicht werden kann.
Die Autoren gaben an, dass ihr Basiswert SparseGPT 2:4 zum Zeitpunkt des Schreibens keine durchg?ngigen Leistungsverbesserungen erzielen konnte. Stattdessen verglichen sie SliceGPT mit SparseGPT 2:4, indem sie die relative Zeit jeder Operation in der Transformatorschicht verglichen. Sie fanden heraus, dass SliceGPT (25 %) bei gro?en Modellen hinsichtlich Geschwindigkeitsverbesserung und Verwirrung mit SparseGPT (2:4) konkurrenzf?hig war.
Rechenkosten
Alle LLAMA-2-, OPT- und Phi-2-Modelle k?nnen in 1 bis 3 Stunden auf einer einzigen GPU segmentiert werden. Wie in Tabelle 3 gezeigt, k?nnen mit der Feinabstimmung der Wiederherstellung alle LMs innerhalb von 1 bis 5 Stunden komprimiert werden.

Weitere Informationen finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonGro?e Modelle k?nnen ebenfalls in Scheiben geschnitten werden, und Microsoft SliceGPT erh?ht die Recheneffizienz von LLAMA-2 erheblich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Was ist Ethereum? Wie k?nnen die Ethereum -ETH ETHE -ETH erhalten?
Jul 31, 2025 pm 11:00 PM
Was ist Ethereum? Wie k?nnen die Ethereum -ETH ETHE -ETH erhalten?
Jul 31, 2025 pm 11:00 PM
Ethereum ist eine dezentrale Anwendungsplattform, die auf intelligenten Vertr?gen basiert, und seine native Token -ETH kann auf verschiedene Weise erhalten werden. 1. Registrieren Sie ein Konto über zentralisierte Plattformen wie Binance und Ouyiok, vervollst?ndigen Sie die KYC -Zertifizierung und kaufen Sie ETH mit Stablecoins. 2. Einschalten Sie mit dezentralen Plattformen mit digitalem Speicher und tauschen Sie die ETH mit Stablecoins oder anderen Token direkt aus. 3.. Nehmen Sie an Netzwerkversprechen teil, und Sie k?nnen die unabh?ngige Verpf?ndung (ben?tigt 32 ETH), Liquid Pledge Services oder One-Click-Versprechen auf der zentralisierten Plattform, um Belohnungen zu erhalten. 4. Verdienen Sie ETH, indem Sie Dienstleistungen für Web3 -Projekte erstellen, Aufgaben erledigen oder Airdrops erhalten. Es wird empfohlen, dass Anf?nger mit zentralisierten Mainstream -Plattformen beginnen, schrittweise zu dezentralen Methoden übergehen und immer Bedeutung für die Sicherheit von Verm?genswerten und die unabh?ngigen Forschung beibringen
 Wie w?hle ich eine freie Marktwebsite im W?hrungskreis aus? Die umfassendste überprüfung im Jahr 2025
Jul 29, 2025 pm 06:36 PM
Wie w?hle ich eine freie Marktwebsite im W?hrungskreis aus? Die umfassendste überprüfung im Jahr 2025
Jul 29, 2025 pm 06:36 PM
Die am besten geeigneten Tools zur Abfrage von Stablecoin -M?rkten im Jahr 2025 sind: 1. Binance, mit ma?geblichen Daten und reichhaltigen Handelspaaren sowie integrierten TradingView -Diagrammen, die für die technische Analyse geeignet sind. 2. Ouyi, mit klarer Schnittstelle und starker funktionaler Integration, und unterstützt den One-Stop-Betrieb von Web3-Konten und Defi; 3. Coinmarketcap mit vielen W?hrungen und der Stablecoin -Sektor k?nnen die Marktwert -Rangliste und -Dekane betrachten. 4. Coingecko mit umfassenden Datenabmessungen bietet Vertrauenswerte und Aktivit?tsindikatoren der Community und hat eine neutrale Position. 5. Huobi (HTX) mit stabilen Marktbedingungen und freundlichen Gesch?ftst?tigkeit, geeignet für Mainstream -Anfragen; 6. Gate.io mit der schnellsten Sammlung neuer Münzen und Nischenw?hrungen und ist die erste Wahl für Projekte, um das Potenzial zu untersuchen. 7. Tra
 Die Strategie von Ethena Treasury: Der Aufstieg des dritten Reiches von Stablecoin
Jul 30, 2025 pm 08:12 PM
Die Strategie von Ethena Treasury: Der Aufstieg des dritten Reiches von Stablecoin
Jul 30, 2025 pm 08:12 PM
Der wahre Einsatz von Battle Royale im Dual -W?hrungssystem ist noch nicht stattgefunden. Schlussfolgerung Im August 2023 gab der Protokollfunke des Makerdao Ecological Lending eine annualisierte Rendite von 8 USD%. Anschlie?end trat Sun Chi in Chargen ein und investierte insgesamt 230.000 $ Steth, was mehr als 15% der Einlagen von Spark ausmacht und Makerdao dazu zwang, einen Notfallvorschlag zu treffen, um den Zinssatz auf 5% zu senken. Die ursprüngliche Absicht von Makerdao war es, die Nutzungsrate von $ dai zu "subventionieren" und fast zu Justin Suns Soloertrag wurde. Juli 2025, Ethe
 Was ist Binance Treehouse (Baummünze)? überblick über das kommende Baumhausprojekt, Analyse der Token -Wirtschaft und zukünftige Entwicklung
Jul 30, 2025 pm 10:03 PM
Was ist Binance Treehouse (Baummünze)? überblick über das kommende Baumhausprojekt, Analyse der Token -Wirtschaft und zukünftige Entwicklung
Jul 30, 2025 pm 10:03 PM
Was ist Baumhaus (Baum)? Wie funktioniert Baumhaus (Baum)? Treehouse Products Tethdor - Dezentrale Anführungsquote Gonuts Points System Treeehouse Highlights Tree Tokens und Token Economics übersicht über das dritte Quartal des Roadmap -Entwicklungsteams von 2025, Investoren und Partners Treehouse Gründungsteam Investmentfonds Partner Zusammenfassung, da Defi weiter expandiert. Auf Blockchain bauen jedoch
 Ethereum (ETH) NFT verkaufte in sieben Tagen fast 160 Millionen US
Jul 30, 2025 pm 10:06 PM
Ethereum (ETH) NFT verkaufte in sieben Tagen fast 160 Millionen US
Jul 30, 2025 pm 10:06 PM
Inhaltsverzeichnis Kryptomarkt Panorama -Nugget Popul?r Token Vinevine (114,79%, Kreismarktwert 144 Millionen US -Dollar) Zorazora (16,46%, Kreismarktwert 290 Millionen US -Dollar US -Dollar) Navxnaviprotokoll (10,36%, kreisf?rmiger Marktwert 35,7624 Millionen US -Dollar). Cryptopunks starteten den ersten Platz im dezentralen Prover -Netzwerk, das die Loccinte Foundation gestartet hat, die m?glicherweise das Token tge sein k?nnte
 Solana und die Gründer von Base Coin starten eine Debatte: Der Inhalt von Zora hat 'Grundwert'.
Jul 30, 2025 pm 09:24 PM
Solana und die Gründer von Base Coin starten eine Debatte: Der Inhalt von Zora hat 'Grundwert'.
Jul 30, 2025 pm 09:24 PM
Ein verbaler Kampf um den Wert von "Sch?pfer -Token" fegte über den Krypto -sozialen Kreis. Die beiden gro?en Helmans von Base und Solana hatten eine seltene Frontalkonfrontation und eine heftige Debatte um Zora und Pump. Woher kam diese mit Schie?pulver gefüllte Konfrontation? Lassen Sie uns herausfinden. Die Kontroverse brach aus: Die Sicherung von Sterling Crispins Angriff auf Zora war Delcomplex -Forscher Sterling Crispin, das Zora auf sozialen Plattformen ?ffentlich bombardierte. Zora ist ein soziales Protokoll in der Basiskette, das sich auf die Tokenisierung der Benutzer -Homepage und des Inhalts konzentriert
 Was ist Zircuit (ZRC -W?hrung)? Wie arbeite ich? ZRC -Projektübersicht, Token Economy und Prospect Analysis
Jul 30, 2025 pm 09:15 PM
Was ist Zircuit (ZRC -W?hrung)? Wie arbeite ich? ZRC -Projektübersicht, Token Economy und Prospect Analysis
Jul 30, 2025 pm 09:15 PM
Verzeichnis Wie ist Zirkan. SCHLUSSFOLGERUNG In den letzten Jahren ist der Nischenmarkt der Layer2 -Blockchain -Plattform, die Dienste für das Ethereum -Layer1 -Netzwerk erbringt, vor allem aufgrund von Netzwerküberlastungen, hohen Abhandlungsgebühren und schlechter Skalierbarkeit floriert. Viele dieser Plattformen verwenden die Hochvolumentechnologie, mehrere Transaktionsstapel verarbeitet abseits der Kette
 Warum f?llt die Registrierung von Binance -Konto fehl? Ursachen und L?sungen
Jul 31, 2025 pm 07:09 PM
Warum f?llt die Registrierung von Binance -Konto fehl? Ursachen und L?sungen
Jul 31, 2025 pm 07:09 PM
Das Vers?umnis, ein Binance -Konto zu registrieren, wird haupts?chlich durch regionale IP -Blockade, Netzwerkanomalien, KYC -Authentifizierungsfehler, Kontoverdünnung, Probleme mit Ger?tekompatibilit?t und Systemwartung verursacht. 1. Verwenden Sie uneingeschr?nkte regionale Knoten, um die Netzwerkstabilit?t zu gew?hrleisten. 2. Senden Sie klare und vollst?ndige Zertifikatsinformationen und übereinstimmen die Nationalit?t; 3. Registrieren Sie sich mit ungebundener E -Mail -Adresse; 4. Reinigen Sie den Browser -Cache oder ersetzen Sie das Ger?t. 5. Wartungsphase vermeiden und auf die offizielle Ankündigung achten; 6. Nach der Registrierung k?nnen Sie 2FA sofort aktivieren, den Whitelist und den Anti-Phishing-Code adressieren, der die Registrierung innerhalb von 10 Minuten abschlie?en und die Sicherheit um mehr als 90%verbessern und schlie?lich eine Compliance- und Sicherheits-geschlossene Schleife aufbauen kann.
