


Wir wissen, dass der Speicher als ein sehr gro?es Array betrachtet werden kann. Wenn wir ein Element im Speicher finden m?chten, wird es durch den Index des Arrays angegeben. Das Gleiche gilt für den Speicher, aber es gibt eine Voraussetzung Das Array besteht aus einer Reihe geordneter Bytes. In diesem geordneten Byte-Array hat jedes Byte eine eindeutige Adresse. Diese Adresse wird auch als Speicheradresse bezeichnet.
Im Speicher sind viele Objekte gespeichert, z. B. ein char-Objekt, ein byte-Objekt, ein int-Objekt usw. Die CPU ist in verschiedene Speicherorte unterteilt Der Vorgang des Auffindens der Adressen dieser Objekte wird als Speicheradressierung bezeichnet. Die Speicherbusbreite bestimmt, wie viele Bits der Speicheradresse ab Adresse 0 adressiert werden k?nnen. Da 80X86 32 Bit ist, betr?gt die Busbreite auch 32 Bit, sodass insgesamt 2 ^ 32 Speicheradressen vorhanden sind, sodass insgesamt 4 GB Speicheradressen gespeichert werden k?nnen. Mehrere Byte-Datentypen wie int, long und double k?nnen über aufeinanderfolgende Speicheradressen extrahiert werden.
Obwohl Objekte adressiert werden k?nnen, ist die Bytereihenfolge, in der diese Objekte gespeichert werden, unterschiedlich. Es gibt zwei Speichermethoden, n?mlich Big Endian und Little Endian.
Zum Beispiel gibt es ein Objekt vom Typ int an der Adresse 0x100 und sein Hexadezimalwert ist 0x01234567. Ich werde Ihnen ein Bild zeichnen und Sie werden den Unterschied zwischen den beiden Speicherreihenfolgen verstehen.
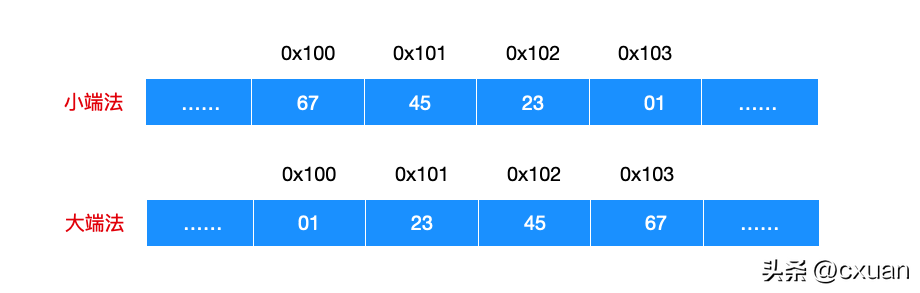
Das ist eigentlich leicht zu verstehen. Der int-Datentyp von 0x01234567 kann in 01 23 45 67 Bytes aufgeteilt werden, und 01 ist das High-Bit und 67 das Low-Bit, also die Speicherreihenfolge von Little Endian Big-Endian-Methoden k?nnen erkl?rt werden: Das hei?t, die Little-Endian-Methode verwendet zuerst das Bit niedriger Ordnung, w?hrend die Big-Endian-Methode zuerst das Bit hoher Ordnung verwendet. Der Unterschied zwischen Big-Endian und Little-Endian besteht nur in der Speicherreihenfolge und hat nichts mit der Anzahl der Ziffern und dem numerischen Wert des Objekts zu tun. Die meisten Intel-Maschinen verwenden den Little-Endian-Modus, daher ist 80X86 auch Little-Endian-Speicher, w?hrend die meisten IBM- und Oracle-Maschinen Big-Endian-Speicher verwenden.
Da der Computer nicht alle Daten im Speicher auf einmal ansprechen kann, weil dieser relativ gro? ist, wird der Speicher im Allgemeinen segmentiert. Dabei stellt sich die Frage: Warum ist der Speicher segmentiert? Ich habe oben nur eine allgemeine Einführung gegeben.
Warum muss das Ged?chtnis segmentiert werden?
http://www.miracleart.cn/link/d005ce7aeef46bd18515f783fb8e87fa
Mit dem Segmentierungsmechanismus wird der Speicherplatz in lineare Bereiche unterteilt, und jeder lineare Bereich kann anhand der Segmentbasisadresse plus dem Intrasegment lokalisiert werden versetzt. Der Basisadressteil des Segments wird durch einen 16-Bit-Segmentselektor angegeben, von dem 14 Bits 2^14, also 16384 Segmente, ausw?hlen k?nnen. Der Offset-Adressteil innerhalb des Segments wird mithilfe eines 32-Bit-Werts angegeben Die Adresse innerhalb des Segments kann zwischen 0 und 4 GB liegen. Die maximale L?nge eines Segments betr?gt 4 GB, was der oben erw?hnten Speicheradresse von 4 GB entspricht. Eine 48-Bit-Adresse oder ein langer Zeiger, der aus einem 16-Bit-Segment und einem Offset innerhalb eines 32-Bit-Segments besteht, wird als logische Adresse bezeichnet, und die logische Adresse ist die virtuelle Adresse.
In der X86-Architektur gibt es sechs spezielle Register zum Speichern von Segmentbasisadressen: CS, DS, ES, SS, FS und GS. CS wird zur Adressierung des Codesegments, SS zur Adressierung des Stapelsegments und andere Register zur Adressierung des Datensegments verwendet. Das vom CS zu einem bestimmten Zeitpunkt adressierte Segment wird als aktuelles Codesegment bezeichnet. Die Offset-Adresse des n?chsten Befehls, der im aktuellen Codesegment ausgeführt werden soll, ist bereits im EIP-Register vorhanden. Zu diesem Zeitpunkt kann die Segmentbasisadresse:Offsetadresse als CS:EIP ausgedrückt werden.
Das vom Segmentregister SS adressierte Segment wird als aktuelles Stapelsegment bezeichnet. SS:ESP zeigt jederzeit auf die Spitze des Stapels, und es gibt keine Ausnahmen Die anderen vier sind allgemeine Datensegmentregister. Wenn der Befehl standardm??ig kein Datensegment enth?lt, wird es von DS angegeben.
Adressübersetzung
Normalerweise besteht ein vollst?ndiges Speicherverwaltungssystem aus zwei Komponenten: Zugriffsschutz und Adressübersetzung. Der Zugriffsschutz soll verhindern, dass eine Anwendung auf eine Speicheradresse zugreift, die von einem anderen Programm verwendet wird. Die Adressübersetzung dient dazu, eine dynamische Adresszuweisungsmethode für verschiedene Anwendungen bereitzustellen. Zugriffsschutz und Adressübersetzung erg?nzen sich.
Bei der Adressübersetzung werden normalerweise Speicherbl?cke als Grundeinheit verwendet. Hier finden Sie eine Erkl?rung, was ein Block ist. Wie wir alle wissen, sind in Linux alles Dateien, die aus Bl?cken bestehen. Die Komponenteneinheit des Systems ist auch die Grundeinheit der Datenverarbeitung. G?ngige Bl?cke haben unterschiedliche Gr??en, z. B. 512 B, 1 KB, 4 KB usw. Obwohl ein Block die Grundeinheit ist, besteht er im Wesentlichen aus Sektoren.
Es gibt zwei M?glichkeiten, die Adressübersetzung zu implementieren: den Segmentierungsmechanismus und den Paging-Mechanismus. Die Implementierung der Speicherverwaltung in x86 kombiniert Segmentierungs- und Paging-Mechanismen. Das Folgende ist ein Zuordnungsdiagramm virtueller Adressen, die nach Segmentierung und Paging in physische Adressen umgewandelt werden
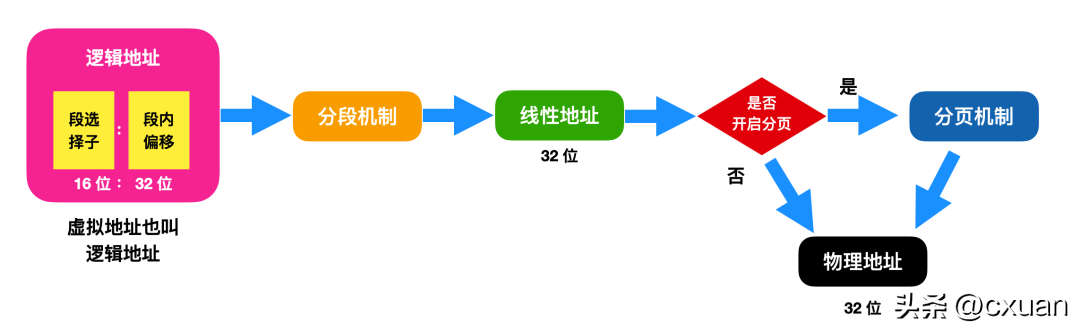
Für dieses Bild ist Folgendes zu erkl?ren:
Zun?chst enth?lt dieses Bild drei Adressen und den Konvertierungsprozess dieser drei Adressen. Nach der segmentierten Basisadresskonvertierung wird die lineare Adresse zur Segmentbasisadresse + Intra-. Segmentoffset, daher ist dieses Bild ein Adressübersetzungsdiagramm im geschützten Modus. Die lineare Adresse wird nach dem Paging-Mechanismus in eine physische Adresse umgewandelt, sofern der Paging-Mechanismus aktiviert werden muss. Wenn der Paging-Mechanismus nicht aktiviert ist, ist die lineare Adresse = physische Adresse.
Ich muss noch einmal über die logische Adresse sprechen. Die logische Adresse enth?lt den Segmentselektor und den Intra-Segment-Offset. Das Konzept des Segmentselektors war relativ vage, als ich damit in Kontakt kam Wir alle wissen, dass die Segmentbasisadresse im geschützten Modus 16 Bit und der Offset innerhalb des Segments 32 Bit betr?gt.
In vielen Büchern oder Artikeln werden Segmentselektoren erw?hnt. Im Englischen handelt es sich ausschlie?lich um Segmentselektoren.
Segmentdeskriptor wird sp?ter erw?hnt. Segmentdeskriptor und Segmentselektor sind nicht dasselbe, aber der Segmentselektor ist ein 16-Bit-Segmentdeskriptor.
Lassen Sie mich Ihnen etwas sagen, das in diesem Bild nicht steht. Jetzt wei? jeder, dass logische Adressen in lineare Adressen und lineare Adressen in physische Adressen umgewandelt werden k?nnen. Tats?chlich wird hier die MMU (Speicherverwaltungseinheit) zur Konvertierung verwendet, und die Konvertierung linearer Adressen in physische Adressen verwendet die Hardwareschaltung der Paging-Einheit. Der Schwerpunkt dieses Artikels liegt nicht auf der Er?rterung des spezifischen Konvertierungsprozesses, sondern auf den beiden Mechanismen Segmentierung und Paging.
Lassen Sie uns im Detail über die beiden Mechanismen Segmentierung und Paging sprechen.
Segmentierungsmechanismus
Ich empfehle Ihnen, zuerst die Beschreibung zu lesen, die ich zum Thema ?Warum Speicher segmentiert werden muss“ geschrieben habe.
http://www.miracleart.cn/link/d005ce7aeef46bd18515f783fb8e87fa
Mehrere Programme werden im selben Speicherbereich ausgeführt und st?ren sich nicht gegenseitig. Dies liegt daran, dass die Segmentierung für die Isolierung von Code-, Daten- und Stapelbereichen sorgt . Wenn in der CPU mehrere Programme oder Aufgaben ausgeführt werden, kann jedem Programm ein eigener Satz von Segmenten zugewiesen werden (einschlie?lich Programmcode, Daten und Stapel). Die CPU verhindert, dass Anwendungen sich gegenseitig st?ren, indem sie die Grenzen zwischen den Segmenten st?rkt.
Alle in einem System verwendeten Segmente sind im linearen Adressraum der CPU enthalten. Um ein Byte in einem bestimmten Segment zu finden, muss das Programm eine logische Adresse bereitstellen, damit die übersetzung stattfinden kann. Die logische Adresse enth?lt den Segmentselektor und den Offset innerhalb des Segments. Jedes Segment verfügt über einen Segmentdeskriptor. Der Segmentdeskriptor wird verwendet, um die Gr??e des Segments, die Zugriffsrechte und die Berechtigungsstufe des Segments, den Segmenttyp und das erste Byte anzugeben des Segments ist der Online-Standort im sexuellen Adressraum (Segment-Basisadresse). Der Offset-Teil der logischen Adresse wird zur Segmentbasisadresse hinzugefügt, um die Position eines bestimmten Bytes im Segment zu lokalisieren, sodass die Segmentbasisadresse + Offset die Adresse im linearen Adressraum der CPU bildet.
Der lineare Adressraum hat die gleiche Struktur wie der physische Adressraum, aber die Segmente, die er aufnehmen kann, sind sehr unterschiedlich. Die virtuelle Adresse, d. h. der logische Adressraum, kann bis zu 16 K-Segmente enthalten, und jedes Segment kann eine Gr??e von 4 GB, sodass die virtuelle Adresse insgesamt 64 TB (2 ^ 46) Segmente finden kann und der lineare Adress- und physische Adressraum 4 GB (2 ^ 32) betr?gt. Wenn also Paging deaktiviert ist, ist der lineare Adressraum der physische Adressraum.
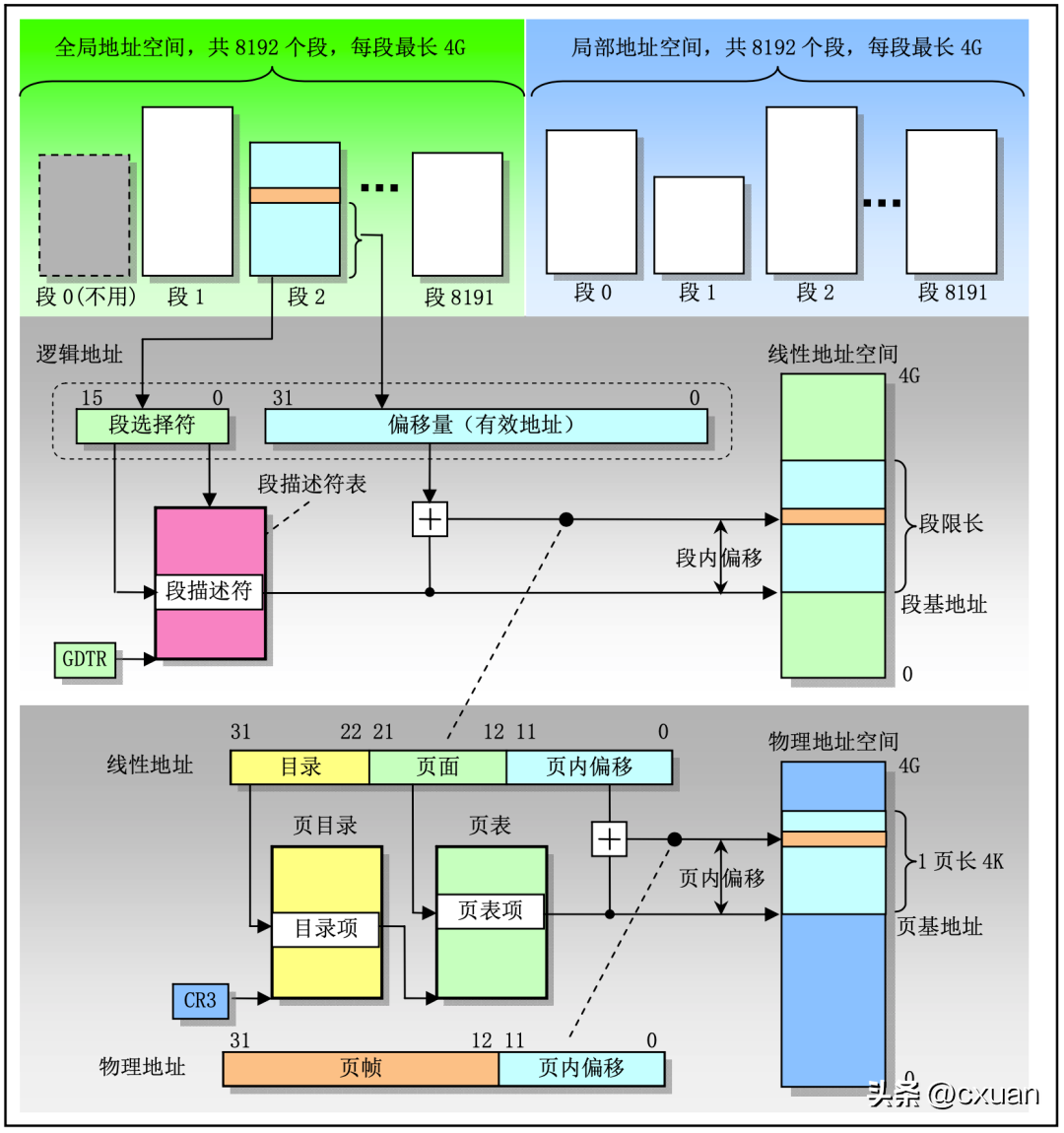
Dieses Bild ist das Zuordnungsdiagramm der logischen Adresse – > lineare Adresse – > Die GDT-Tabelle und die LDT-Tabelle belegen jeweils die H?lfte des Adressraums mit jeweils 8192 Segmenten bis 4 G, ob aus der GDT-Tabelle oder der LDT-Tabelle abgefragt werden soll, welche Tabelle abgefragt werden soll, h?ngt vom TI-Attribut des Segmentselektors ab. Die Struktur des Segmentselektors ist wie folgt:

Der Segmentselektor ist unterteilt in Insgesamt drei Teile:
- RPL (Request Privilege Level): Anforderungsprivilegstufe, die angibt, welche Berechtigungen der Prozess für den Zugriff auf das Segment haben sollte. Je gr??er der Wert, desto kleiner die Berechtigungen.
- TI (Tabellenindikator): Gibt an, welche Tabelle abgefragt werden soll, TI = 0, um die GDT-Tabelle abzufragen; TI = 1, um die LDT-Tabelle abzufragen.
- Index: Die CPU fügt automatisch Index * 8 sowie die Segmentbasisadresse in GDT und LDT hinzu, bei der es sich um den zu ladenden Segmentdeskriptor handelt.
Hier gibt es keine detaillierte Erkl?rung der Segmentdeskriptoren, da dieser Artikel immer noch die Speicherverwaltung bevorzugt und sich nicht zu sehr auf bestimmte Details konzentriert.
In GDTR kann die logische Adresse, bestehend aus Segmentselektor und Offset, zu einem Segmentdeskriptor synthetisiert und direkt gespeichert werden. Segmentselektoren und Intrasegment-Offsets k?nnen nach dem Durchlaufen der MMU in lineare Adressen umgewandelt werden.
Paging-Mechanismus
Wie oben erw?hnt, wird die lineare Adresse von der logischen Adresse umgewandelt. Wenn der Paging-Mechanismus aktiviert ist, ist die lineare Adresse die Anzahl der linearen Adressen Adressr?ume sind immer noch unterschiedlich. Im Allgemeinen sind Programme Multitasking-f?hig, und der lineare Adressraum, der normalerweise durch Multitasking definiert wird, ist viel gr??er als die physische Speicherkapazit?t. Warum? Die Adressübersetzungskarte zeigt, dass sowohl die lineare Adresse als auch die physische Adresse 4G gro? sind. Das liegt daran, dass lineare Adressen durch virtuelle Speichertechnologie virtualisiert werden.
Virtueller Speicher ist eine Speicherverwaltungstechnologie, die uns die Illusion vermitteln kann, dass der Speicherplatz viel gr??er ist als die tats?chliche physische Speicherkapazit?t. Das bedeutet, dass der Speicher m?glicherweise nur 4G gro? ist. Aber Sie denken, der Speicher hat 64 G, deshalb kann ich so viele Anwendungen ?ffnen.
Der Paging-Mechanismus ist eigentlich eine Implementierung der Virtualisierung. In einer virtualisierten Umgebung wird ein gro?er Teil des linearen Adressraums einem kleinen Teil des physischen Speichers (RAM oder ROM) zugeordnet. Beim Paging wird jedes Segment in Seiten (normalerweise 4 KB) unterteilt und diese Seiten werden im physischen Speicher oder auf der Festplatte gespeichert. Das Betriebssystem verwaltet diese Seiten mithilfe eines Seitenverzeichnisses und von Seitentabellen. Wenn ein Programm versucht, auf eine Adressposition im linearen Adressraum zuzugreifen, verwendet die CPU das Seitenverzeichnis und die Seitentabelle, um die lineare Adresse in eine physische Adresse umzuwandeln und sie dann im physischen Speicher zu speichern.
Wenn sich die aktuell aufgerufene Seite nicht im physischen Speicher befindet, führt die CPU einen Interrupt aus. Der allgemeine Fehler ist eine Seitenausnahme. Anschlie?end liest das Betriebssystem die Seite von der Festplatte in den physischen Speicher und führt sie dann weiter aus Programm ab der Unterbrechungsstelle. Das Betriebssystem tauscht h?ufig Seiten ein und aus, was ebenfalls zu einem Leistungsengpass führt.
Bei der Segmentierung ist die L?nge jedes Segments nicht festgelegt und die maximale L?nge betr?gt 4G, w?hrend beim Paging die Gr??e jeder Seite festgelegt ist. Ob im physischen Speicher oder auf der Festplatte, die Verwendung von Seiten mit fester Gr??e eignet sich besser für die Verwaltung des physischen Speichers, w?hrend der Segmentierungsmechanismus mit Bl?cken variabler Gr??e besser für die Verarbeitung logischer Partitionen komplexer Systeme geeignet ist.
Obwohl Segmentierung und Paging zwei verschiedene Adressübersetzungsmechanismen sind, werden sie w?hrend des gesamten Adressübersetzungsprozesses unabh?ngig voneinander behandelt, und jeder Prozess ist unabh?ngig. Beide Mechanismen verwenden eine Zwischentabelle zum Speichern von Eintragszuordnungen, die Struktur dieser Zwischentabelle ist jedoch unterschiedlich. Die Segmenttabelle existiert im linearen Adressraum und die Seitentabelle wird im physischen Adressraum gespeichert.
Schutzmechanismus
80x86 verfügt über zwei Schutzmechanismen, von denen einer eine vollst?ndige Isolierung zwischen Aufgaben erreicht, indem jeder Aufgabe unterschiedliche virtuelle Adressr?ume zugewiesen werden. Dies wird erreicht, indem jeder Aufgabe eine andere Umwandlung von einer logischen Adresse in eine physische Adresse zugewiesen wird. Jede Anwendung kann nur auf Daten und Anweisungen in ihrem eigenen virtuellen Raum zugreifen und die physische Adresse nur über ihre eigene Zuordnung erhalten. Schützen Sie die Speichersegmente des Betriebssystems und einige spezielle Register vor dem Zugriff durch Anwendungen. Lassen Sie uns diese beiden Aufgaben im Folgenden im Detail besprechen.
Schutz zwischen Aufgaben
Jede Aufgabe wird separat in ihrem eigenen virtuellen Adressraum platziert und dann über die Hardware einer physischen Adresse zugeordnet. Verschiedene virtuelle Adressen werden in unterschiedliche physische Adressen umgewandelt, und es gibt keine virtuelle Adresse von A Die Adresse wird dem Bereich der physischen Adresse zugeordnet, an der sich B befindet, sodass alle Aufgaben isoliert sind und sich verschiedene Aufgaben nicht gegenseitig st?ren.
Jede Aufgabe verfügt über eine eigene Zuordnungstabelle, Segmenttabelle und Seitentabelle. Wenn die CPU zwischen verschiedenen Anwendungen oder Aufgaben wechselt, wechseln auch diese Tabellen.
Virtuelle Adresse ist eine Abstraktion des Betriebssystems, was bedeutet, dass die virtuelle Adresse vollst?ndig vom Betriebssystem als Tr?ger abstrahiert wird, der Anwendungen und Aufgaben besser verwalten kann zeigt, dass jede Aufgabe Zugriff auf das Betriebssystem hat, das von allen Aufgaben gemeinsam genutzt wird. Dieser Teil des virtuellen Adressraums, in dem alle Aufgaben denselben virtuellen Adressraum haben, wird als globaler Adressraum bezeichnet, und Linux verwendet den globalen Adressraum.
Jede Aufgabe im globalen Adressraum verfügt über einen eigenen, einzigartigen virtuellen Adressraum. Dieser virtuelle Adressraum wird als lokaler Adressraum bezeichnet.
Spezieller Schutz von Speichersegmenten und Registern
Wenn der Schutz des Betriebssystems zwischen verschiedenen Aufgaben mit einem horizontalen Schutz verglichen wird, kann der Schutz von Speichersegmenten und Registern als vertikaler Schutz angesehen werden. Um den Zugriff auf verschiedene Segmente innerhalb einer Aufgabe einzuschr?nken, legt das Betriebssystem vier Berechtigungsstufen fest, um jede Aufgabe zu schützen.
Die Priorit?t ist in 4 Stufen unterteilt, 0 ist die h?chste und 3 die niedrigste. Im Allgemeinen erhalten die vertraulichsten Daten die h?chste Priorit?t, und auf sie kann nur der vertrauenswürdigste Teil der Aufgabe zugreifen. Weniger vertrauliche Daten erhalten im Allgemeinen eine niedrigere Priorit?t, Anwendungsdaten dagegen im Allgemeinen Level 3. Jedem Speichersegment ist eine Berechtigungsstufe zugeordnet.
Wir wissen, dass die CPU über CS Anweisungen und Daten zur Ausführung erh?lt. Der Zugriff auf die vom Segment erhaltenen Anweisungen und Daten erfolgt im Allgemeinen mit der aktuellen Berechtigungsstufe (aktuelle Berechtigungsstufe). Ebene des aktuell aktiven Codes. Wenn eine Anwendung versucht, auf ein Segment zuzugreifen, wird es mit dieser Berechtigungsstufe verglichen und es kann nur auf Berechtigungsstufen zugegriffen werden, die niedriger als dieses Segment sind.
Das obige ist der detaillierte Inhalt vonSpeicherverwaltung im geschützten Linux-Modus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Wie installiere ich Linux neben Windows (Dual -Boot)?
Jun 18, 2025 am 12:19 AM
Wie installiere ich Linux neben Windows (Dual -Boot)?
Jun 18, 2025 am 12:19 AM
Der Schlüssel zur Installation von Dual -Systemen unter Linux und Windows sind die Einstellungen für die Partitionierung und Start. 1. Vorbereitung umfasst das Sicherungsdaten und die Komprimierung vorhandener Partitionen, um Platz zu schaffen. 2. Verwenden Sie Ventoy oder Rufus, um Linux -Start -USB -Festplatten zu erstellen, und empfehlen Sie Ubuntu. 3.. W?hlen Sie "Koexist mit anderen Systemen" oder partitionieren Sie w?hrend der Installation manuell ( /mindestens 20 GB, /Home Bleibender Platz, optional); 4. überprüfen Sie die Installation von Treibern von Drittanbietern, um Hardwareprobleme zu vermeiden. 5. Wenn Sie nach der Installation das Grub-Boot-Menü nicht eingeben, k?nnen Sie den Boot-Repair verwenden, um den Start zu reparieren oder die BIOS-Startsequenz anzupassen. Solange die Schritte klar sind und die Operation ordnungsgem?? durchgeführt wird, ist der gesamte Vorgang nicht kompliziert.
 So aktivieren Sie das EPEL -Repository (zus?tzliche Pakete für Enterprise Linux)?
Jun 17, 2025 am 09:15 AM
So aktivieren Sie das EPEL -Repository (zus?tzliche Pakete für Enterprise Linux)?
Jun 17, 2025 am 09:15 AM
Der Schlüssel zum Aktivieren von Epel -Repository ist die Auswahl der richtigen Installationsmethode gem?? der Systemversion. Best?tigen Sie zun?chst den Systemtyp und die Systemtyp und den Befehlskatze/etc/os-Release, um Informationen zu erhalten. Zweitens aktivieren Sie EPEL durch Dnfinstallepel-Release auf CentOS/Rockylinux, und die 8- und 9-Versionsbefehle sind gleich; Drittens müssen Sie die entsprechende Version der .Repo -Datei manuell herunterladen und auf RHEL installieren. Viertens k?nnen Sie die GPG-Schlüssel bei Problemen erneut importieren. Beachten Sie, dass die alte Version m?glicherweise nicht unterstützt wird und Sie auch in Betracht ziehen k?nnen, das Testpaket zu erhalten. Verwenden Sie nach Abschluss der oben genannten Schritte DNFrepolist, um zu überprüfen, ob das Epel -Repository erfolgreich hinzugefügt wird.
 Wie w?hle ich eine Linux -Distribution für einen Anf?nger aus?
Jun 19, 2025 am 12:09 AM
Wie w?hle ich eine Linux -Distribution für einen Anf?nger aus?
Jun 19, 2025 am 12:09 AM
Neulingsnutzer sollten ihre Nutzungsanforderungen zun?chst bei der Auswahl einer Linux -Verteilung kl?ren. 1. W?hlen Sie Ubuntu oder Linuxmint für den t?glichen Gebrauch. Programmierung und Entwicklung eignen sich für Manjaro oder Fedora; Verwenden Sie Lubuntu und andere leichte Systeme für alte Ger?te. Empfehlen Sie Centosstream oder Debian, um die zugrunde liegenden Prinzipien zu erlernen. 2. Stabilit?t wird für Ubuntults oder Debian bevorzugt; Sie k?nnen Arch oder Manjaro ausw?hlen, um neue Funktionen zu verfolgen. 3. In Bezug auf die Unterstützung der Community sind Ubuntu und Linuxmint reich an Ressourcen, und Arch -Dokumente sind technisch ausgerichtet. 4. In Bezug auf die Installationsschwierigkeit sind Ubuntu und Linuxmint relativ einfach und Arch ist für diejenigen mit Grundbedürfnissen geeignet. Es wird empfohlen, es zuerst zu versuchen und dann zu entscheiden.
 So fügen Sie Linux eine neue Festplatte hinzu
Jun 27, 2025 am 12:15 AM
So fügen Sie Linux eine neue Festplatte hinzu
Jun 27, 2025 am 12:15 AM
Die Schritte zum Hinzufügen einer neuen Festplatte zum Linux-System sind wie folgt: 1. Stellen Sie sicher, dass die Festplatte erkannt wird und LSBLK oder FDISK-L verwendet, um zu überprüfen. 2. Verwenden Sie FDISK- oder Abteilte -Partitionen wie FDISK/Dev/SDB und erstellen und speichern. 3. Formatieren Sie die Partition in ein Dateisystem wie Mkfs.ext4/dev/sdb1; 4. Verwenden Sie den Befehl montage für tempor?re Halterungen wie Mount/Dev/SDB1/MNT/Daten; 5. ?ndern Sie /etc /fstab, um eine automatische Halterung am Computer zu erreichen, und testen Sie zuerst die Halterung, um die Korrektheit zu gew?hrleisten. Stellen Sie sicher, dass Sie die Datensicherheit vor dem Betrieb best?tigen, um Hardware -Verbindungsprobleme zu vermeiden.
 Es wurde das Vers?umnis beim Hochladen von Dateien in Windows Google Chrome behoben
Jul 08, 2025 pm 02:33 PM
Es wurde das Vers?umnis beim Hochladen von Dateien in Windows Google Chrome behoben
Jul 08, 2025 pm 02:33 PM
Haben Sie Probleme beim Hochladen von Dateien in Google Chrome? Das kann nervig sein, oder? Unabh?ngig davon, ob Sie Dokumente an E -Mails anh?ngen, Bilder in sozialen Medien weitergeben oder wichtige Dateien für die Arbeit oder die Schule senden, ist ein reibungsloser Upload -Prozess von entscheidender Bedeutung. Es kann also frustrierend sein, wenn Ihre Datei -Uploads weiterhin in Chrome auf Windows PC versagt. Wenn Sie nicht bereit sind, Ihren bevorzugten Browser aufzugeben, finden Sie hier einige Tipps für Korrekturen, bei denen Dateien auf Windows Google Chrome nicht hochgeladen werden k?nnen. 1. Beginnen Sie mit der universellen Reparatur, bevor wir über eine fortgeschrittene Fehlerbehebungstipps informieren. Es ist am besten, einige der unten genannten grundlegenden L?sungen auszuprobieren. Fehlerbehebung bei Internetverbindungsproblemen: Internetverbindung
 Wo befinden sich Systemprotokolle unter Linux?
Jun 24, 2025 am 12:15 AM
Wo befinden sich Systemprotokolle unter Linux?
Jun 24, 2025 am 12:15 AM
Protokolle in Linux -Systemen werden normalerweise im Verzeichnis /var /log gespeichert, das eine Vielzahl von Schlüsselprotokolldateien wie Syslog oder Nachrichten (Datensatzsystemprotokolle), Auth.log (Record -Authentifizierungsereignisse), Kern.log (Aufzeichnungskernel -Nachrichten), DPKG.Log oder Yum.log (Aufzeichnungspaketpaket Operations), Boot.log (Aufzeichnungsmeldungen) (Aufzeichnungsstart) enth?lt. Protokollinhalte k?nnen über CAT-, Tail-F- oder JournalCtl-Befehle angezeigt werden. Anwendungsprotokolle befinden sich h?ufig in Unterverzeichnissen unter /var /log /logisch, z. B. Apache2 oder HTTPD -Verzeichnis, MySQL -Protokolldateien usw.; Gleichzeitig ist zu beachten, dass Protokollberechtigungen normalerweise s erforderlich sind
 Was ist der Sudo -Befehl und wann sollte ich ihn verwenden?
Jul 02, 2025 am 12:20 AM
Was ist der Sudo -Befehl und wann sollte ich ihn verwenden?
Jul 02, 2025 am 12:20 AM
Sudo steht für "SubstituteUserDo" oder "Superuserdo", sodass Benutzer Befehle mit Berechtigungen anderer Benutzer ausführen k?nnen (normalerweise Root). Zu den Kern verwendet: 1. Operationen auf Systemebene wie die Installation von Software oder Bearbeitungssystemdateien durchführen; 2. Zugriff auf geschützte Verzeichnisse oder Protokolle; 3. Verwalten Sie Dienste wie das Neustarten von Nginx; 4. ?ndern Sie globale Einstellungen wie /etc /hosts. Bei der Verwendung überprüft das System die Konfiguration /etc /sudoers und überprüft das Benutzerkennwort, gibt tempor?re Berechtigungen an, anstatt sich kontinuierlich als Stamm anzumelden und die Sicherheit zu gew?hrleisten. Zu den besten Verfahren geh?ren: Wenn dies erforderlich ist, vermeiden Sie nur bei Bedarf blindige Ausführung von Netzwerkbefehlen, Bearbeiten von Sudoers -Dateien mit Visudo und Berücksichtigung kontinuierlicher Vorg?nge.
 So verwalten Gruppen unter Linux
Jul 06, 2025 am 12:02 AM
So verwalten Gruppen unter Linux
Jul 06, 2025 am 12:02 AM
Um Linux -Benutzergruppen zu verwalten, müssen Sie den Betrieb des Betrachtens, Erstellens, L?schens, ?nderns und Benutzerattributanpassungen beherrschen. Um Benutzergruppeninformationen anzuzeigen, k?nnen Sie CAT/ETC/Group oder GetentGroup verwenden, Gruppen [Benutzername] oder ID [Benutzername] verwenden, um die Gruppe anzuzeigen, zu der der Benutzer geh?rt. Verwenden Sie GroupAdd, um eine Gruppe zu erstellen und GroupDel zu verwenden, um die GID anzugeben. Verwenden Sie GroupDel, um leere Gruppen zu l?schen. Verwenden Sie Usermod-Ag, um Benutzer zur Gruppe hinzuzufügen, und verwenden Sie Usermod-G, um die Hauptgruppe zu ?ndern. Verwenden Sie Usermod-G, um Benutzer aus der Gruppe zu entfernen, indem Sie /etc /Gruppe bearbeiten oder den VigR-Befehl verwenden. Verwenden Sie GroupMod-N (?nderung Name) oder GroupMod-G (?nderung GID), um Gruppeneigenschaften zu ?ndern, und denken Sie daran, die Berechtigungen relevanter Dateien zu aktualisieren.
