


Apache ICEBERG: Ein modernes Tabellenformat für das erweiterte Data Lake Management
Apache Iceberg ist ein hochmodernes Tabellenformat, das die M?ngel herk?mmlicher Bienenstocktabellen angeht und überlegene Leistung, Datenkonsistenz und Skalierbarkeit liefert. In diesem Artikel wird die Entwicklung von Iceberg, die wichtigsten Merkmale (S?uretransaktionen, Schemaentwicklung, Zeitreisen), Architektur und Vergleiche mit anderen Tabellenformaten wie Delta Lake und Parquet untersucht. Wir werden auch seine Integration in moderne Datenseen und ihre Auswirkungen auf das gro?e Datenmanagement und die Analyse des Datenverwaltungswesens untersuchen.
Wichtige Lernpunkte
- Fassen Sie die Kernmerkmale und die Architektur von Apache Iceberg.
- Verstehen Sie, wie Eisberg das Schema und die Partitionentwicklung ohne Daten umschrieben.
- Erforschen Sie, wie S?uretransaktionen und Zeitreisen die Datenkonsistenz st?rken.
- Vergleichen Sie die F?higkeiten von Iceberg mit Delta Lake und Hudi.
- Identifizieren Sie Szenarien, in denen Eisberg die Leistung des Datensees optimiert.
Inhaltsverzeichnis
- Einführung in Apache Iceberg
- Die Entwicklung von Eisberg
- Verst?ndnis des Eisberg -Formats
- Kernmerkmale von Apache Iceberg
- Taucher in Eisbergs Architektur eintauchen
- Eisberg gegen andere Tischformate: Ein Vergleich
- Abschluss
- H?ufig gestellte Fragen
Einführung in Apache Iceberg
Apache Iceberg wurde 2017 (die Idee von Ryan Blue und Daniel Weeks) auf Netflix (die Idee von Ryan Blue und Daniel Weeks) erstellt und wurde erstellt, um Leistungsengp?sse, Konsistenzprobleme und Einschr?nkungen des Hive -Tabellenformats zu l?sen. Open-Sourced und spendete 2018 an die Apache Software Foundation und erlangte schnell an die Anziehung und lieferte Beitr?ge von Branchengiganten wie Apple, AWS und LinkedIn.
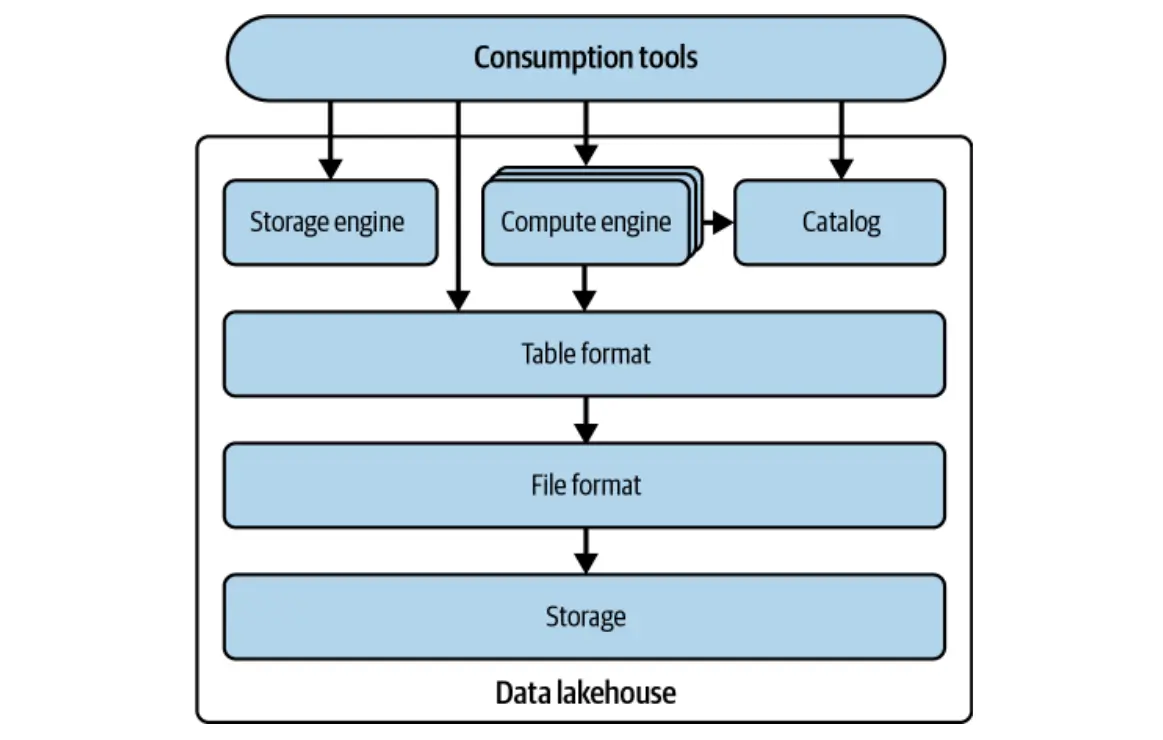
Die Entwicklung von Apache Iceberg
Die Erfahrung von Netflix zeigte eine kritische Schw?che im Bienenstock: seine Abh?ngigkeit von Verzeichnissen für die Tischverfolgung. Dieser Ansatz fehlte die Granularit?t, die für eine robuste Konsistenz, effiziente Parallelit?t und die erwarteten fortschrittlichen Merkmale in modernen Data Warehouses erforderlich war. Die Entwicklung von Iceberg zielte darauf ab, diese Einschr?nkungen zu überwinden, mit einem Fokus auf:
Wichtige Designziele
- Datenkonsistenz: Aktualisierungen über mehrere Partitionen hinweg müssen atomar und nahtlos sein, wodurch die Benutzer inkonsistente Daten angezeigt werden.
- Leistungsoptimierung: Effizientes Metadatenmanagement war von gr??ter Bedeutung, um Abfragenplanung Engp?sse zu beseitigen und die Ausführung der Abfrage zu beschleunigen.
- Benutzerfreundlichkeit: Die Partitionierung sollte für die Benutzer transparent sein und eine automatische Abfrageoptimierung ohne manuelle Intervention erm?glichen.
- Schema -Anpassungsf?higkeit: Schema -Modifikationen sollten sicher behandelt werden, ohne dass vollst?ndige Datensatzumschreiben erforderlich sind.
- Skalierbarkeit: Die L?sung musste effizient Petabyte von Daten verarbeiten und die Skala von Netflix widerspiegeln.
Verst?ndnis des Eisberg -Formats
Iceberg befasst sich mit diesen Herausforderungen, indem sie Tabellen als strukturierte Liste von Dateien und nicht als Verzeichnis verfolgen. Es bietet ein standardisiertes Format, das Metadatenstruktur für mehrere Dateien definiert und Bibliotheken für eine nahtlose Integration in beliebte Motoren wie Spark und Flink bietet.
Ein Datenseestandard
Das Design von Iceberg Prioritiert die Kompatibilit?t mit vorhandenen Speicher- und Berechnung von Motoren und f?rdert eine breite Akzeptanz ohne wesentliche ?nderungen. Ziel ist es, Eisberg als Branchenstandard zu etablieren, sodass Benutzer unabh?ngig vom zugrunde liegenden Format mit Tabellen interagieren k?nnen. Viele Datenwerkzeuge bieten jetzt native Eisberg -Unterstützung.
Kernmerkmale von Apache Iceberg
Iceberg übertrifft einfach die Grenzen von Hive. Es führt leistungsstarke Funktionen für die Verbesserung des Datenloads von Data Lake und Data Lakehouse. Zu den wichtigsten Funktionen geh?ren:
S?ure -Transaktionsgarantien
Iceberg verwendet eine optimistische Parallelit?tskontrolle, um die S?ureeigenschaften sicherzustellen, und garantiert, dass Transaktionen entweder vollst?ndig engagiert oder vollst?ndig zurückgerollt sind. Dies minimiert Konflikte bei der Aufrechterhaltung der Datenintegrit?t.
Partitionentwicklung
Im Gegensatz zu herk?mmlichen Datenseen erm?glicht Iceberg die ?nderung der Partitionierungsschemata, ohne die gesamte Tabelle neu zu schreiben. Dies gew?hrleistet eine effiziente Abfrageoptimierung, ohne vorhandene Daten zu st?ren.
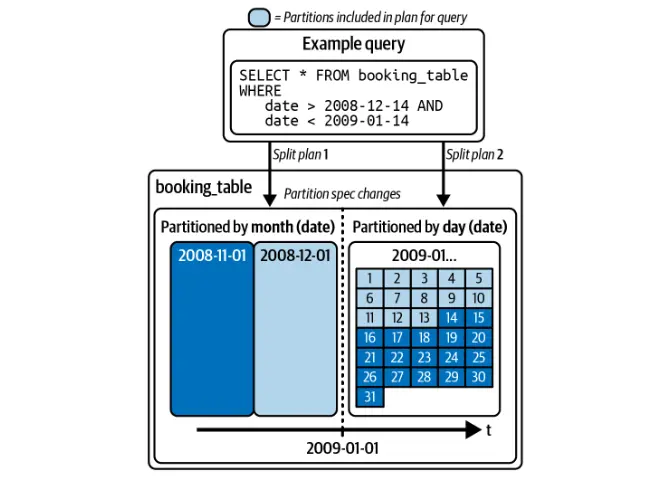
Versteckte Partitionierung
Iceberg optimiert automatisch Abfragen, die auf der Partitionierung basieren, und beseitigt die Notwendigkeit, dass Benutzer manuell durch Partitionsspalten filtern.
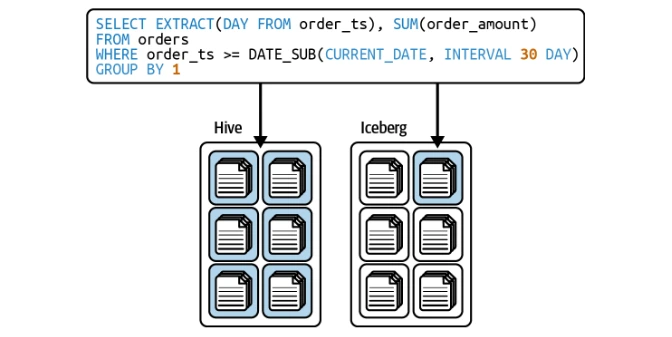
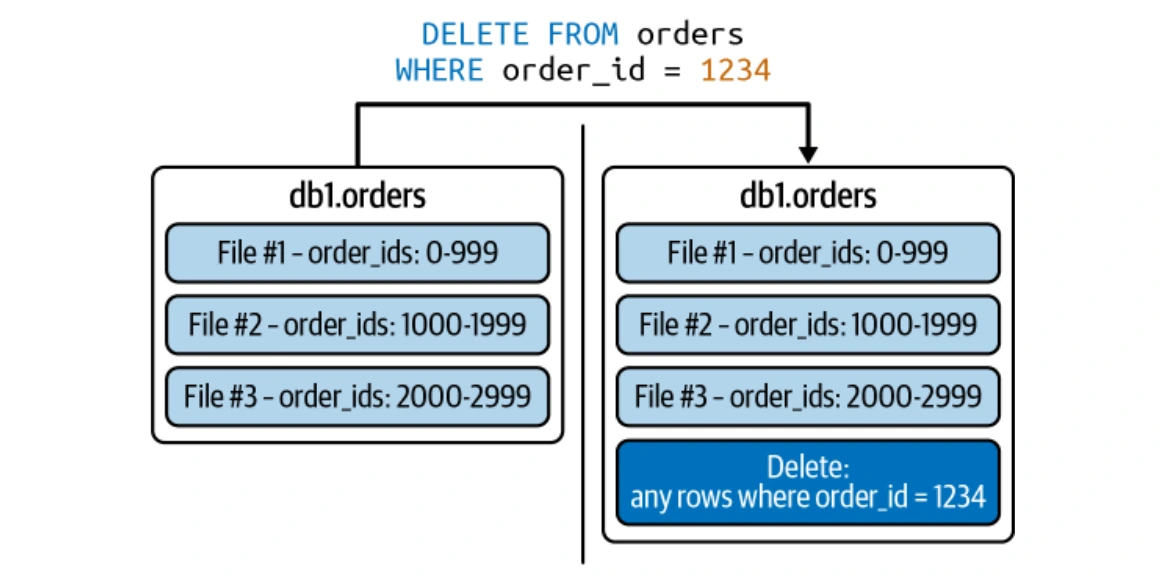
Operationen auf Zeilenebene (Kopie auf dem Schreiben und Merge-on-Read)
Iceberg unterstützt sowohl Kopien-auf-Schrei- als auch MORGE-On-Read-Strategien für effiziente Updates auf Zeilenebene.
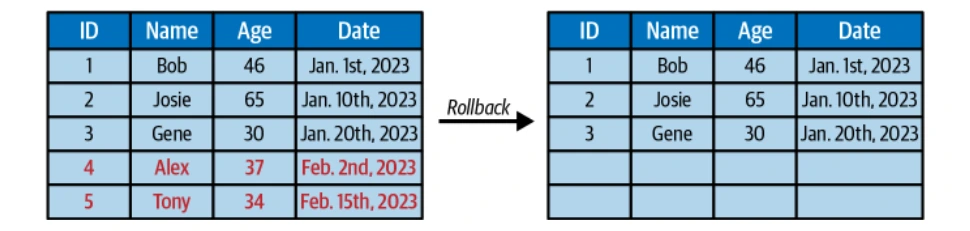
Zeitreisen und Versionsrollback
Die unver?nderlichen Schnappschüsse von Iceberg erm?glichen Zeitreisefragen und die M?glichkeit, in frühere Tischzust?nde zurückzukehren.

Schemaentwicklung
Iceberg unterstützt Schema -Modifikationen (Hinzufügen, Entfernen oder ?ndern von Spalten), ohne dass Daten umschreiben, um Flexibilit?t und Kompatibilit?t zu gew?hrleisten.
Taucher in Eisbergs Architektur eintauchen
In diesem Abschnitt werden die Architektur von Iceberg und wie sie die Grenzen von Hive überwindet.
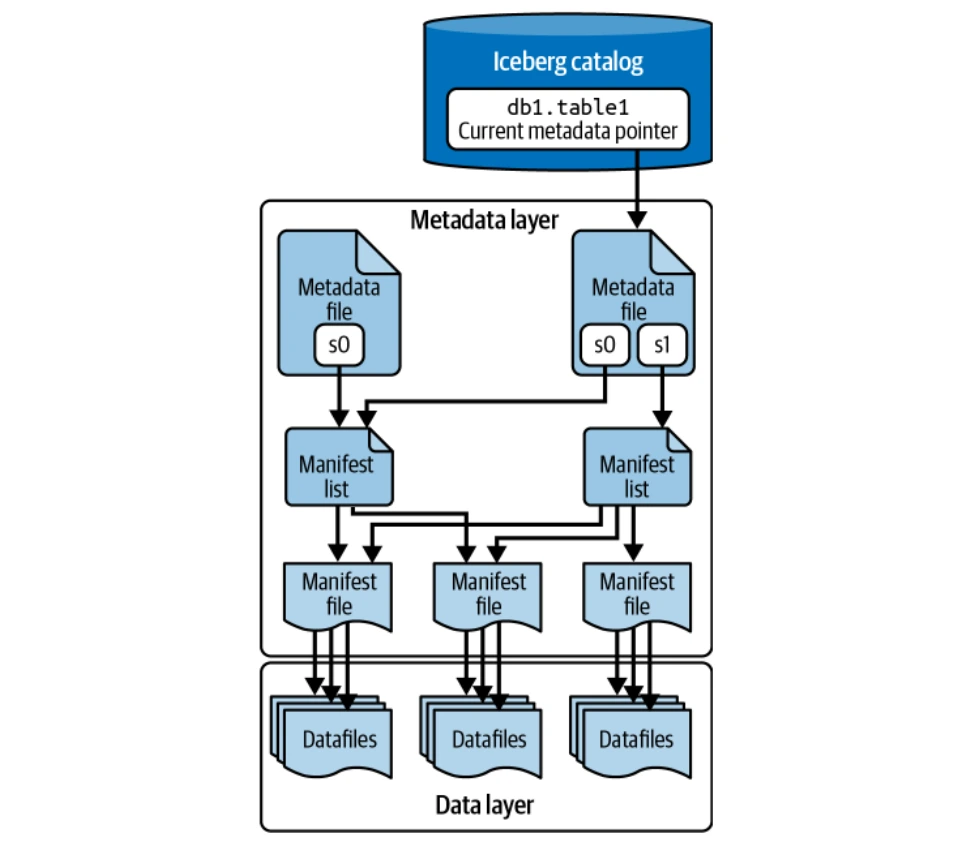
Die Datenschicht
Die Datenschicht speichert die tats?chlichen Tabellendaten (Datendateien und L?schen von Dateien). Es wird in verteilten Dateisystemen (HDFs, S3 usw.) gehostet und unterstützt mehrere Dateiformate (Parquet, ORC, AVRO). Parquet wird üblicherweise für seine S?ulenspeicherung bevorzugt.


Die Metadatenschicht
Diese Ebene verwaltet alle Metadatendateien in einer Baumstruktur und verfolgt Datendateien und Operationen. Zu den Schlüsselkomponenten geh?ren Manifestdateien, Manifest -Listen und Metadatendateien. Puffin -Dateien speichern erweiterte Statistiken und Indizes für die Abfrageoptimierung.
Der Katalog
Der Katalog fungiert als zentrales Register und bietet den Standort der aktuellen Metadatendatei für jede Tabelle an, um alle Leser und Autoren konsistenten Zugriff zu gew?hrleisten. Verschiedene Backends k?nnen als Eisberg -Katalog (Hadoop -Katalog, Hive -Metastore, Nessie -Katalog, AWS -Kleberkatalog) dienen.
Eisberg gegen andere Tischformate: Ein Vergleich
Iceberg, Parquet, Orc und Delta Lake werden h?ufig in der Datenverarbeitung in gro?em Ma?stab verwendet. Iceberg unterscheidet sich als Tabellenformat, das Transaktionsgarantien und Metadatenoptimierungen bietet, im Gegensatz zu Parquet und ORC, die Dateiformate sind. Im Vergleich zu Delta Lake zeichnet sich Iceberg in Schema und Partitionentwicklung aus.
Abschluss
Apache Iceberg bietet einen robusten, skalierbaren und benutzerfreundlichen Ansatz für das Data Lake-Management. Seine Funktionen machen es zu einer überzeugenden L?sung für Organisationen, die mit gro? angelegten Daten umgehen.
H?ufig gestellte Fragen
Q1. Was ist Apache Iceberg? A. Ein modernes Open-Source-Tabellenformat verbessert die Leistung, Konsistenz und Skalierbarkeit von Datensee.
Q2. Warum wird Apache Iceberg ben?tigt? A. um die Einschr?nkungen von Hive bei Metadatenhandhabung und Transaktionsfunktionen zu überwinden.
Q3. Wie geht Eisberg mit der Schema -Evolution um? A. Es unterstützt Schema?nderungen, ohne dass eine vollst?ndige Tischumschreibung erforderlich ist.
Q4. Was ist die Partitionentwicklung in Eisberg? A. ?nderung von Partitionierungsschemata ohne Umschreiben historischer Daten.
Q5. Wie unterstützt Eisberg S?uretransaktionen? A. durch optimistische Parallelit?tskontrolle, um Atomaktualisierungen zu gew?hrleisten.
Das obige ist der detaillierte Inhalt vonWie benutze ich Apache -Eisberg -Tabellen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Kimi K2: Das m?chtigste Open-Source-Agentenmodell
Jul 12, 2025 am 09:16 AM
Kimi K2: Das m?chtigste Open-Source-Agentenmodell
Jul 12, 2025 am 09:16 AM
Erinnern Sie sich an die Flut chinesischer Open-Source-Modelle, die die Genai-Industrie Anfang dieses Jahres gest?rt haben? W?hrend Deepseek die meisten Schlagzeilen machte, war Kimi K1.5 einer der herausragenden Namen in der Liste. Und das Modell war ziemlich cool.
 Grok 4 gegen Claude 4: Was ist besser?
Jul 12, 2025 am 09:37 AM
Grok 4 gegen Claude 4: Was ist besser?
Jul 12, 2025 am 09:37 AM
Bis Mitte 2025 heizt sich das KI ?Wettret“ auf, und Xai und Anthropic haben beide ihre Flaggschiff-Modelle GROK 4 und Claude 4 ver?ffentlicht. Diese beiden Modelle befinden
 10 erstaunliche humanoide Roboter, die heute bereits unter uns gehen
Jul 16, 2025 am 11:12 AM
10 erstaunliche humanoide Roboter, die heute bereits unter uns gehen
Jul 16, 2025 am 11:12 AM
Aber wir müssen wahrscheinlich nicht einmal 10 Jahre warten, um einen zu sehen. Was als erste Welle wirklich nützlicher, menschlicher Maschinen angesehen werden k?nnte, ist bereits da. In den letzten Jahren wurden eine Reihe von Prototypen und Produktionsmodellen aus t herausgezogen
 Context Engineering ist der neue ' Schnelltechnik
Jul 12, 2025 am 09:33 AM
Context Engineering ist der neue ' Schnelltechnik
Jul 12, 2025 am 09:33 AM
Bis zum Vorjahr wurde eine schnelle Engineering als entscheidende F?higkeit zur Interaktion mit gro?artigen Modellen (LLMs) angesehen. In jüngster Zeit sind LLM jedoch in ihren Argumentations- und Verst?ndnisf?higkeiten erheblich fortgeschritten. Natürlich unsere Erwartung
 6 Aufgaben Manus ai kann in wenigen Minuten erledigen
Jul 06, 2025 am 09:29 AM
6 Aufgaben Manus ai kann in wenigen Minuten erledigen
Jul 06, 2025 am 09:29 AM
Ich bin sicher, Sie müssen über den allgemeinen KI -Agenten Manus wissen. Es wurde vor einigen Monaten auf den Markt gebracht, und im Laufe der Monate haben sie ihrem System mehrere neue Funktionen hinzugefügt. Jetzt k?nnen Sie Videos erstellen, Websites erstellen und viel MO machen
 Leia's Imgsitary Mobile App bringt die 3D -Tiefe in allt?gliche Fotos
Jul 09, 2025 am 11:17 AM
Leia's Imgsitary Mobile App bringt die 3D -Tiefe in allt?gliche Fotos
Jul 09, 2025 am 11:17 AM
Aufgebaut auf Leia's propriet?rer neuronaler Tiefenmotor verarbeitet die App still Bilder und fügt die natürliche Tiefe zusammen mit simulierten Bewegungen hinzu - wie Pfannen, Zoome und Parallaxeffekte -, um kurze Video -Rollen zu erstellen, die den Eindruck erwecken, in die SCE einzusteigen
 Diese KI -Modelle haben nicht die Sprache gelernt, sie lernten Strategie
Jul 09, 2025 am 11:16 AM
Diese KI -Modelle haben nicht die Sprache gelernt, sie lernten Strategie
Jul 09, 2025 am 11:16 AM
Eine neue Studie von Forschern am King's College London und der University of Oxford teilt die Ergebnisse dessen, was passiert ist, als OpenAI, Google und Anthropic in einem Cutthroat -Wettbewerb zusammengeworfen wurden, der auf dem iterierten Dilemma des Gefangenen basiert. Das war nein
 Was sind die 7 Arten von AI -Agenten?
Jul 11, 2025 am 11:08 AM
Was sind die 7 Arten von AI -Agenten?
Jul 11, 2025 am 11:08 AM
Stellen Sie sich vor, dass etwas Geformtes, wie ein KI -Motor, der bereit ist, ein detailliertes Feedback zu einer neuen Kleidungssammlung von Mailand oder automatische Marktanalyse für ein weltweit betriebenes Unternehmen zu geben, oder intelligentes Systeme, das eine gro?e Fahrzeugflotte verwaltet.
