


chinesische KI macht erhebliche Fortschritte und forderte führende Modelle wie GPT-4, Claude und Grok mit kostengünstigen Open-Source-Alternativen wie Deepseek-V3 und Qwen 2.5. Diese Modelle zeichnen sich aufgrund ihrer Effizienz, Zug?nglichkeit und starker Leistung aus. Viele arbeiten unter zul?ssigen kommerziellen Lizenzen und erweitern ihre Berufung auf Entwickler und Unternehmen.
Minimax-Text-01, die neueste Erg?nzung dieser Gruppe, setzt einen neuen Standard mit seiner beispiellosen 4-Millionen-Token-Kontextl?nge und übertrifft die typische 128K-256-K-Token-Grenze. Diese erweiterte Kontextf?higkeit in Kombination mit einer hybriden Aufmerksamkeitsarchitektur für Effizienz und einer Open-Source-Lizenz f?rdert Innovation ohne hohe Kosten.
Lassen Sie uns in die Funktionen von Minimax-Text-01 eintauchen:
Inhaltsverzeichnis
- Hybridarchitektur
- Mischungsmischung (MOE) Strategie
- Trainings- und Skalierungsstrategien
- Optimierung nach dem Training
- Key Innovations
- Kern akademische Benchmarks
- Allgemeine Aufgaben Benchmarks
- Begründung Aufgaben Benchmarks
- Mathematik- und Codierungsaufgaben Benchmarks
- Erste Schritte mit Minimax-text-01
- Wichtige Links
- Schlussfolgerung
Hybridarchitektur
minimax-text-01 gleicht Effizienz und Leistung geschickt aus, indem sie die Aufmerksamkeit der Blitze, die Aufmerksamkeit von Softmax und die Expertenmischung (MOE) integrieren.
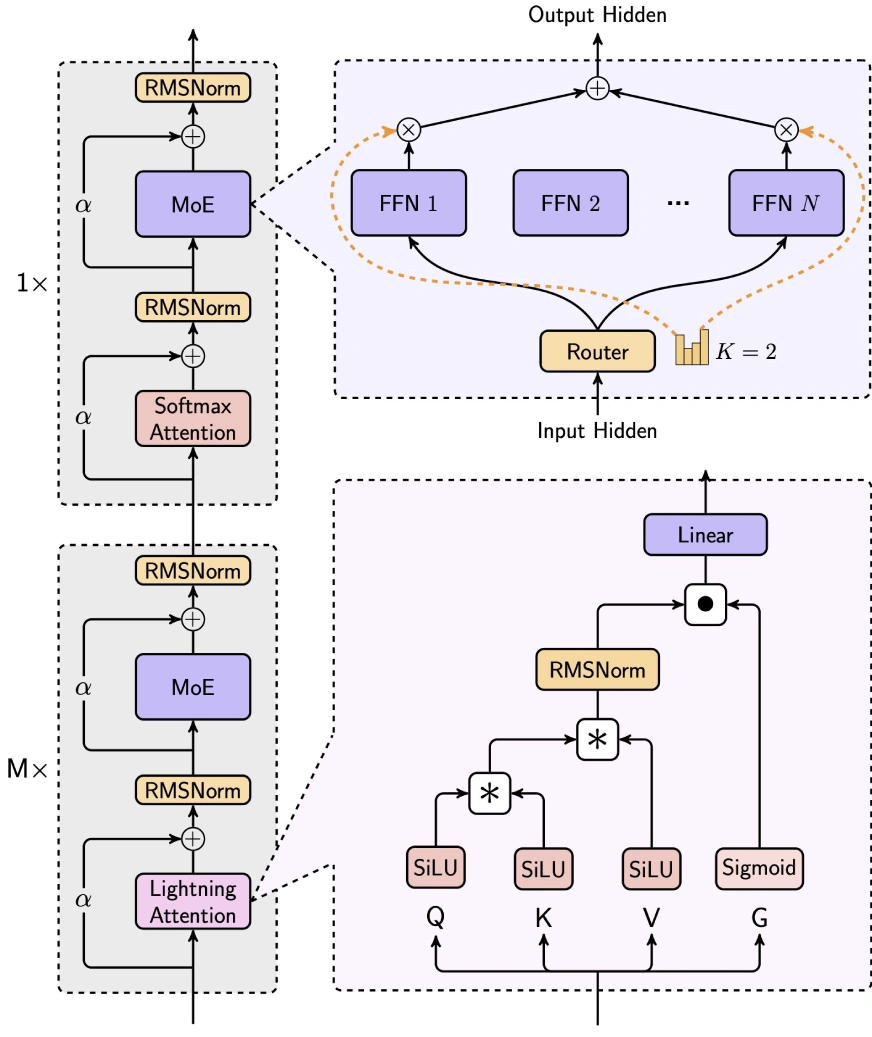
- 7/8 Lineare Aufmerksamkeit (Blitzaufmerksamkeit-2): Dieser lineare Aufmerksamkeitsmechanismus reduziert drastisch die Rechenkomplexit?t von O (n2d) auf O (d2n), ideal für die langkontexte Verarbeitung. Es verwendet die SILU -Aktivierung für die Eingangstransformation, Matrixoperationen zur Berechnung der Aufmerksamkeitsbewertung sowie RMSNorm und Sigmoid zur Normalisierung und Skalierung.
- 1/8 Softmax Aufmerksamkeit: Ein traditioneller Aufmerksamkeitsmechanismus, der Seil (Rotationsposition einbettet) in die halbe Aufmerksamkeitskopfdimension, die L?nge extrapoliert, ohne die Leistung zu beeintr?chtigen.
Mischungsmischung (MOE) Strategie
Die einzigartige Moe-Architektur von minimax-text-01 unterscheidet sie von Modellen wie Deepseek-V3:
- Token -Drop -Strategie: verwendet einen Hilfsverlust, um die ausgewogene Token -Verteilung über Experten hinweg aufrechtzuerhalten, im Gegensatz zu Deepseeks Tropfenansatz.
- Globaler Router: optimiert Token -Allokation für die Verteilung der Arbeitsbelastung zwischen Expertengruppen.
- Top-K-Routing: W?hlt die Top-2-Experten pro Token aus (im Vergleich zu Deepseeks Top-8 1-Shared Expert).
- Expertenkonfiguration: verwendet 32 ??Experten (gegen Deepseeks 256 1 geteilt) mit einer versteckten Expertendimension von 9216 (gegen Deepseeks 2048). Die gesamten aktivierten Parameter pro Schicht bleiben die gleichen wie Deepseek (18.432).
Trainings- und Skalierungsstrategien
- Schulungsinfrastruktur: nutzte ungef?hr 2000 H100 -GPUs unter Verwendung fortgeschrittener Parallelismus -Techniken wie Experten -Tensor -Parallelit?t (ETP) und linearer Aufmerksamkeitssequenz Parallelism Plus (LASP). Optimiert für die 8-Bit-Quantisierung für eine effiziente Inferenz auf 8x80 GB H100-Knoten.
- Trainingsdaten: trainiert auf rund 12 Billionen Token mit einem WSD-?hnlichen Lernrate-Zeitplan. Die Daten umfassten eine Mischung aus hoch- und minderwertigen Quellen mit globaler Deduplizierung und 4x-Wiederholung für hochwertige Daten.
- Langkontext-Training: Ein dreiphasiertes Ansatz: Phase 1 (128K-Kontext), Phase 2 (512K-Kontext) und Phase 3 (1M-Kontext) unter Verwendung der linearen Interpolation zur Verwaltung der Verteilungsverschiebungen w?hrend der Kontextl?nge.
- iterative Feinabstimmung: Zyklen der beaufsichtigten Feinabstimmung (SFT) und Verst?rkungslernen (RL), die Offline-DPO und Online-Grpo zur Ausrichtung verwendet.
- Langkontext Feinabstimmung: Ein phasenvertretender Ansatz: Kurzkontext SFT → Langkontext SFT → Kurzkontext RL → Long-Context RL, entscheidend für die überlegene Langkontextleistung.
- Deepnorm: Eine Architektur nach der Norm, die die Skalierung und die Trainingsstabilit?t der verbleibenden Verbindung verbessert.
- Stapelgr??e Aufw?rmen: erh?ht die Stapelgr??e nach und nach von 16 m auf 128 m Token für eine optimale Trainingsdynamik.
- Effiziente Parallelit?t: nutzt die Aufmerksamkeit von Ring, um den Speicheraufwand für lange Sequenzen und die Polsteroptimierung zu minimieren, um die Verschwendung zu reduzieren.
(Tabellen, die Benchmark -Ergebnisse für allgemeine Aufgaben, Argumentationsaufgaben und Mathematik- und Codierungsaufgaben enthalten, sind hier enthalten, die die Tabellen der ursprünglichen Eingabe spiegeln.)

(zus?tzliche Bewertungsparameter verbleiben)
Erste Schritte mit Minimax-text-01
(Code-Beispiel für die Verwendung von Minimax-Text-01 mit umarmenden Gesichtstransformatoren bleibt gleich.)
Wichtige Links
- chatbot
- Online -API
- Dokumentation
Schlussfolgerung
minimax-text-01 zeigt beeindruckende F?higkeiten und erzielte eine modernste Leistung bei langen Kontext- und allgemeinen Aufgaben. W?hrend Verbesserungsbereiche existieren, machen seine Open-Source-Natur, die Kosteneffizienz und die innovative Architektur es zu einem bedeutenden Akteur im KI-Bereich. Es ist besonders für speicherintensive und komplexe Argumentationsanwendungen geeignet, obwohl eine weitere Verfeinerung der Codierungsaufgaben von Vorteil sein kann.
Das obige ist der detaillierte Inhalt von4m Token? Minimax-text-01 übertrifft Deepseek v3. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Kimi K2: Das m?chtigste Open-Source-Agentenmodell
Jul 12, 2025 am 09:16 AM
Kimi K2: Das m?chtigste Open-Source-Agentenmodell
Jul 12, 2025 am 09:16 AM
Erinnern Sie sich an die Flut chinesischer Open-Source-Modelle, die die Genai-Industrie Anfang dieses Jahres gest?rt haben? W?hrend Deepseek die meisten Schlagzeilen machte, war Kimi K1.5 einer der herausragenden Namen in der Liste. Und das Modell war ziemlich cool.
 Grok 4 gegen Claude 4: Was ist besser?
Jul 12, 2025 am 09:37 AM
Grok 4 gegen Claude 4: Was ist besser?
Jul 12, 2025 am 09:37 AM
Bis Mitte 2025 heizt sich das KI ?Wettret“ auf, und Xai und Anthropic haben beide ihre Flaggschiff-Modelle GROK 4 und Claude 4 ver?ffentlicht. Diese beiden Modelle befinden
 10 erstaunliche humanoide Roboter, die heute bereits unter uns gehen
Jul 16, 2025 am 11:12 AM
10 erstaunliche humanoide Roboter, die heute bereits unter uns gehen
Jul 16, 2025 am 11:12 AM
Aber wir müssen wahrscheinlich nicht einmal 10 Jahre warten, um einen zu sehen. Was als erste Welle wirklich nützlicher, menschlicher Maschinen angesehen werden k?nnte, ist bereits da. In den letzten Jahren wurden eine Reihe von Prototypen und Produktionsmodellen aus t herausgezogen
 Context Engineering ist der neue ' Schnelltechnik
Jul 12, 2025 am 09:33 AM
Context Engineering ist der neue ' Schnelltechnik
Jul 12, 2025 am 09:33 AM
Bis zum Vorjahr wurde eine schnelle Engineering als entscheidende F?higkeit zur Interaktion mit gro?artigen Modellen (LLMs) angesehen. In jüngster Zeit sind LLM jedoch in ihren Argumentations- und Verst?ndnisf?higkeiten erheblich fortgeschritten. Natürlich unsere Erwartung
 Leia's Imgsitary Mobile App bringt die 3D -Tiefe in allt?gliche Fotos
Jul 09, 2025 am 11:17 AM
Leia's Imgsitary Mobile App bringt die 3D -Tiefe in allt?gliche Fotos
Jul 09, 2025 am 11:17 AM
Aufgebaut auf Leia's propriet?rer neuronaler Tiefenmotor verarbeitet die App still Bilder und fügt die natürliche Tiefe zusammen mit simulierten Bewegungen hinzu - wie Pfannen, Zoome und Parallaxeffekte -, um kurze Video -Rollen zu erstellen, die den Eindruck erwecken, in die SCE einzusteigen
 Was sind die 7 Arten von AI -Agenten?
Jul 11, 2025 am 11:08 AM
Was sind die 7 Arten von AI -Agenten?
Jul 11, 2025 am 11:08 AM
Stellen Sie sich vor, dass etwas Geformtes, wie ein KI -Motor, der bereit ist, ein detailliertes Feedback zu einer neuen Kleidungssammlung von Mailand oder automatische Marktanalyse für ein weltweit betriebenes Unternehmen zu geben, oder intelligentes Systeme, das eine gro?e Fahrzeugflotte verwaltet.
 Diese KI -Modelle haben nicht die Sprache gelernt, sie lernten Strategie
Jul 09, 2025 am 11:16 AM
Diese KI -Modelle haben nicht die Sprache gelernt, sie lernten Strategie
Jul 09, 2025 am 11:16 AM
Eine neue Studie von Forschern am King's College London und der University of Oxford teilt die Ergebnisse dessen, was passiert ist, als OpenAI, Google und Anthropic in einem Cutthroat -Wettbewerb zusammengeworfen wurden, der auf dem iterierten Dilemma des Gefangenen basiert. Das war nein
 Versteckte Befehlskrise: Forscher Game KI, um ver?ffentlicht zu werden
Jul 13, 2025 am 11:08 AM
Versteckte Befehlskrise: Forscher Game KI, um ver?ffentlicht zu werden
Jul 13, 2025 am 11:08 AM
Wissenschaftler haben eine clevere, aber alarmierende Methode aufgedeckt, um das System zu umgehen. Juli 2025 markierte die Entdeckung einer aufw?ndigen Strategie, bei der Forscher unsichtbare Anweisungen in ihre akademischen Einreichungen eingefügt haben - diese verdeckten Richtlinien waren Schwanz
