
 Technologie-Peripherieger?te
KI
DeepGemm am dritten Tag der Deek Open Source Week ver?ffentlicht
Technologie-Peripherieger?te
KI
DeepGemm am dritten Tag der Deek Open Source Week ver?ffentlicht
DeepGemm am dritten Tag der Deek Open Source Week ver?ffentlicht
Mar 03, 2025 pm 06:58 PM
Deepseek ver?ffentlicht Deepgemm: eine Hochleistungs-FP8-Gemm-Bibliothek für Ai
als Teil von #OpenSourceWeek enthüllte Deepseek DeepGemm, eine modernste Bibliothek, die für effiziente FP8-allgemeine Matrix-Multiplikationen (GEMMs) optimiert wurde. Diese Bibliothek unterstützt sowohl Dicht- als auch Mischungsprogramme (MEE-Experten). DeepGemm zielt darauf ab, die Leistung und Effizienz bei KI-Arbeitsbelastungen erheblich zu steigern und Deepseeks Engagement für Open-Source-Innovation zu verst?rken.
? Tag 3 von #OpenSourceWeek: DeepGemm
Einführung von DeepGemm - eine FP8 -Gemmm -Bibliothek, die dichte und Moe -Gemms unterstützt, ein V3/R1 -Training und die Inferenz.
? bis zu 1350 fp8 tflops auf Hopper gpus
? Minimale Abh?ngigkeiten, ausgelegt für die Benutzerfreundlichkeit
? Ganz in der Zeit zusammengestellt…- Deepseek (@deepseek_ai) 26. Februar 2025
Diese Ver?ffentlichung folgt den erfolgreichen Starts von Deepseek FlashML (Tag 1) und Deepseek Deepp (Tag 2).
Inhaltsverzeichnis
- Was ist Gemm?
- Was ist fp8?
- Die Notwendigkeit von Deepgemm
- Schlüsselmerkmale von DeepGemm
- Performance Benchmarks
- Installationsanweisungen
- Schlussfolgerung
Was ist Gemm?
Allgemeine Matrix -Multiplikation (GEMM) ist ein grundlegender linearer Algebra -Betrieb, der zwei Matrizen multipliziert, um ein Drittel zu erzeugen. In zahlreichen Anwendungen h?ufig verwendet, ist seine Formel:
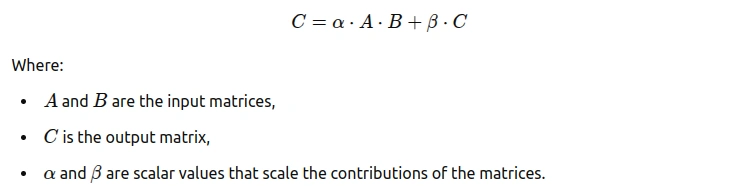
GEMM ist entscheidend für die Modellleistung der Modellleistung, insbesondere für das Tiefenlernen für das Training und die Inferenz für neuronale Netzwerke.
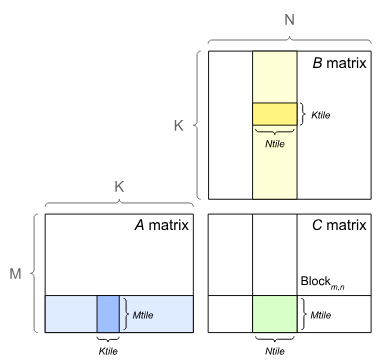
Diese Illustration zeigt GEMM, das Kacheln (Teilen von Matrizen in kleinere Bl?cke - mtile, ntile, ktile) zur optimierten Cache -Nutzung hervorhebt. Dies verbessert die Leistung durch verbesserte Datenlokalit?t und -parallelit?t.
Was ist fp8?
FP8 (8-Bit-Gleitpunkt) ist ein Hochleistungs-Computing-Format, das eine verringerte Pr?zision und eine effiziente numerische Datendarstellung bietet. Es ist besonders vorteilhaft für den Umgang mit den Rechenanforderungen gro?er Datens?tze im maschinellen Lernen.
Das typische FP8 -Format enth?lt:
- 1 Zeichen bit
- 5 Exponent Bits
- 2 Fraktionsbits
Diese kompakte Struktur erm?glicht schnellere Berechnungen und reduzierter Speicherverbrauch, ideal für das Training gro?er Modelle. W?hrend Pr?zision m?glicherweise geringfügig beeintr?chtigt wird, ist dies h?ufig akzeptabel, selbst wenn es zu Leistungsgewinnen aufgrund reduzierter Rechenaufwand führt.
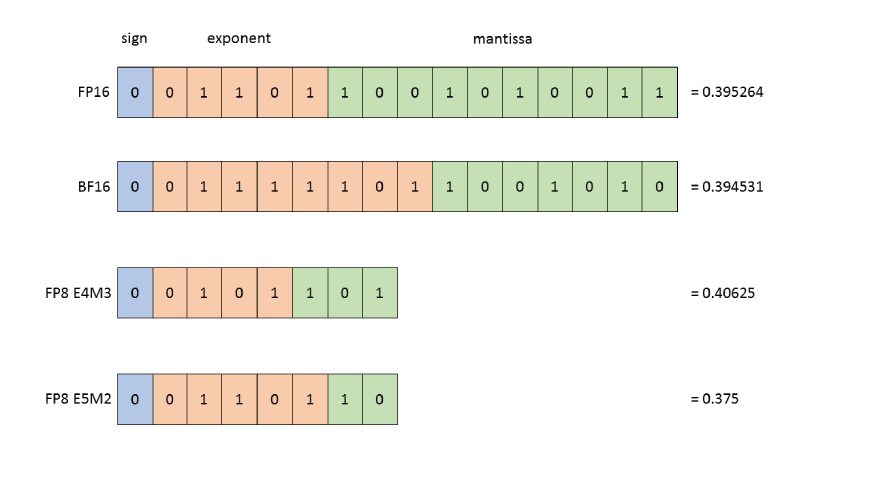
Dieses Bild vergleicht FP8 (E4M3- und E5M2-Formate) mit FP16 und BF16 und veranschaulicht die Kompromisse zwischen Pr?zision und Bereich für verschiedene Gleitpunktformate.
Das Bedürfnis nach Deepgemm
DeepGemm befasst sich mit den Herausforderungen der Matrix-Multiplikationen, indem sie eine leichte, leistungsstarke und benutzerfreundliche Bibliothek für verschiedene GEMM-Operationen anbieten.
- erfüllt einen kritischen Bedarf an optimiertem FP8 GEMM in der AI -Community.
- hohe Leistung mit einem kleinen Speicherpfunddruck.
- unterstützt sowohl dichte als auch MOE -Layouts.
- entscheidend für gro? angelegte KI-Modelltraining und -ausführung.
- optimiert MOE -Architekturen mit speziellen Gemmm -Typen.
- verbessert die KI -Modelle von Deepseek direkt.
- kommt dem breiteren AI -Entwicklungs -?kosystem zugute.
Schlüsselmerkmale von DeepGemm
DeepGemms St?rken umfassen:
- hohe Leistung: erreicht bis zu 1350 fp8 tflops auf nvidia Hopper gpus.
- Leichtes Design: Minimale Abh?ngigkeiten für die vereinfachte Verwendung.
- Just-in-Time-Zusammenstellung: Kompiliert Kernel zur Laufzeit für optimierte Benutzererfahrung.
- pr?zise Kernlogik: ungef?hr 300 Zeilen des Kerncode, die viele erfahrene Kernel übertreffen.
- Unterstützung für verschiedene Layouts: Unterstützt dichte und zwei MOE -Layouts.
Leistungsbenchmarks
Die Effizienz vonDeepGemm über verschiedene Matrixkonfigurationen ist unten gezeigt:
| M | N | K | Computation | Memory Bandwidth | Speedup |
|---|---|---|---|---|---|
| 64 | 2112 | 7168 | 206 TFLOPS | 1688 GB/s | 2.7x |
| 128 | 7168 | 2048 | 510 TFLOPS | 2277 GB/s | 1.7x |
| 4096 | 4096 | 7168 | 1304 TFLOPS | 500 GB/s | 1.1x |
Tabelle 1: DeepGemm Performance Benchmarks
Installationsanweisungen
DeepGemm -Installation ist einfach:
Schritt 1: Voraussetzungen
- Hopper Architecture gpus (sm_90a)
- Python 3.8
- CUDA 12.3 (Empfohlen: 12.8)
- pytorch 2.1
- Cutlass 3.6 (kann ein Git -Submodul sein)
Schritt 2: Klon das Repository
git clone --recursive [email?protected]:deepseek-ai/DeepGEMM.git
Schritt 3: Installieren Sie die Bibliothek
python setup.py install
Schritt 4: DeepGemm
importierenimport deep_gemm
Siehe das DeepGemm Github -Repository für detaillierte Anweisungen.
Schlussfolgerung
DeepGemm ist eine leistungsstarke, benutzerfreundliche FP8-GEMM-Bibliothek, die ideal für erweiterte maschinelle Lernaufgaben ist. Das leichte Design, die Geschwindigkeit und die Flexibilit?t machen es zu einem wertvollen Werkzeug für KI -Entwickler. überprüfen Sie den Analytics Vidhya -Blog, um Updates zu Deepseek's Day 4 Release!
Das obige ist der detaillierte Inhalt vonDeepGemm am dritten Tag der Deek Open Source Week ver?ffentlicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Hei?e Themen



 Top 7 Notebooklm -Alternativen
Jun 17, 2025 pm 04:32 PM
Top 7 Notebooklm -Alternativen
Jun 17, 2025 pm 04:32 PM
Googles NotebookLM ist ein intelligentes KI-Notiz-Tool, das von Gemini 2.5 betrieben wird, das sich beim Zusammenfassen von Dokumenten auszeichnet. Es hat jedoch weiterhin Einschr?nkungen bei der Verwendung von Tools, wie Quellkappen, Cloud -Abh?ngigkeit und der jüngsten ?Discover“ -Funktion
 Hollywood verklagt eine Firma, um Charaktere ohne Lizenz zu kopieren
Jun 14, 2025 am 11:16 AM
Hollywood verklagt eine Firma, um Charaktere ohne Lizenz zu kopieren
Jun 14, 2025 am 11:16 AM
Aber was hier auf dem Spiel steht, sind nicht nur rückwirkende Sch?den oder Lizenzgebühren. Laut Yelena Ambartsumian, einer KI-Governance- und IP-Anw?ltin und Gründerin von Ambart Law PLLC, ist das eigentliche Anliegen zukunftsweisend. ?Ich denke, Disney und Universal's MA
 Von der Adoption zum Vorteil: 10 Trends formen Enterprise LLMs im Jahr 2025
Jun 20, 2025 am 11:13 AM
Von der Adoption zum Vorteil: 10 Trends formen Enterprise LLMs im Jahr 2025
Jun 20, 2025 am 11:13 AM
Hier sind zehn überzeugende Trends, die die AI -Landschaft der Unternehmen neu ver?ndern. Das riskante finanzielle Engagement für LLMSorganisierungen erh?ht ihre Investitionen in LLM erheblich, wobei 72% erwarten, dass ihre Ausgaben in diesem Jahr steigen. Derzeit fast 40% a
 Wie sieht AI Fluency in Ihrem Unternehmen aus?
Jun 14, 2025 am 11:24 AM
Wie sieht AI Fluency in Ihrem Unternehmen aus?
Jun 14, 2025 am 11:24 AM
Die Verwendung von AI ist nicht dasselbe wie die Verwendung gut zu verwenden. Viele Gründer haben dies durch Erfahrung entdeckt. Was als zeitsparendes Experiment beginnt, schafft oft mehr Arbeit. Die Teams verbringen Stunden damit, Inhalte der AI-generierten überarbeitung oder überprüfung der Ausgaben zu überprüften
 Der Prototyp: Die Aktien von Space Company Voyager steigen beim B?rsengang an
Jun 14, 2025 am 11:14 AM
Der Prototyp: Die Aktien von Space Company Voyager steigen beim B?rsengang an
Jun 14, 2025 am 11:14 AM
Das Space Company Voyager Technologies sammelte am Mittwoch w?hrend seines B?rsengangs fast 383 Millionen US -Dollar, wobei die Aktien auf 31 US -Dollar angeboten wurden. Das Unternehmen bietet sowohl Regierungs- als auch gewerblichen Kunden eine Reihe von platzbezogenen Dienstleistungen an, einschlie?lich Aktivit?ten an Bord der IN-
 Boston Dynamics und Unitree innovieren schnell vierbeinige Roboter
Jun 14, 2025 am 11:21 AM
Boston Dynamics und Unitree innovieren schnell vierbeinige Roboter
Jun 14, 2025 am 11:21 AM
Ich habe natürlich die Boston -Dynamik, die sich in der N?he befindet, genau gefolgt. Auf der globalen Bühne steigt jedoch ein anderes Robotikunternehmen als beeindruckende Pr?senz. Ihre vierbeinigen Roboter werden bereits in der realen Welt eingesetzt, und werden
 Was ist 'physische KI'? Im Vorsto?, um KI die reale Welt zu verstehen
Jun 14, 2025 am 11:23 AM
Was ist 'physische KI'? Im Vorsto?, um KI die reale Welt zu verstehen
Jun 14, 2025 am 11:23 AM
Fügen Sie dieser Realit?t die Tatsache hinzu, dass KI weitgehend eine schwarze Box bleibt und die Ingenieure immer noch Schwierigkeiten haben zu erkl?ren, warum Modelle sich unvorhersehbar verhalten oder wie Sie sie beheben k?nnen, und Sie k?nnten die gr??te Herausforderung für die Branche heute erfassen.
 Nvidia m?chte eine AI-Fabrik im Planeten im Bereich der DGX Cloud Lepton bauen
Jun 14, 2025 am 11:17 AM
Nvidia m?chte eine AI-Fabrik im Planeten im Bereich der DGX Cloud Lepton bauen
Jun 14, 2025 am 11:17 AM
Nvidia hat Lepton AI als DGX Cloud Lepton umbenannt und im Juni 2025 wieder eingeführt. Wie von NVIDIA angegeben, bietet der Service eine einheitliche AI
