

PHP Master | Datenstrukturen für PHP -Entwickler: Diagramme
Feb 23, 2025 am 08:49 AM
Key Takeaways
- Diagramme sind mathematische Konstrukte, die zum Modellieren von Beziehungen zwischen Schlüssel-/Wertpaaren verwendet werden, und haben zahlreiche reale Anwendungen wie Netzwerkoptimierung, Verkehrsrouting und soziale Netzwerkanalyse. Sie bestehen aus Scheitelpunkten (Knoten) und Kanten (Zeilen), die sie verbinden, die gerichtet oder ungerichtet und gewichtet oder ungewichtet sind.
- Diagramme k?nnen auf zwei Arten dargestellt werden: als Adjazenzmatrix oder Adjazenzliste. Die Adjazenzlisten sind platz effizienter, insbesondere für sp?rliche Graphen, bei denen die meisten Eckpaare nicht verbunden sind, w?hrend Adjazenzmatrizen schnellere Lookups erm?glichen.
- Eine gemeinsame Anwendung der Graphentheorie findet die geringste Anzahl von Hopfen (d. H. Der kürzeste Weg) zwischen zwei beliebigen Knoten. Dies kann mithilfe der Breite-First-Suche erreicht werden, bei der die Grafikpegel durch einen festgelegten Stammknoten durch die Grafikniveau durchquert wird. Dieser Prozess erfordert die Aufrechterhaltung einer Warteschlange von nicht besuchten Knoten. Der Algorithmus von
- Dijkstra wird h?ufig verwendet, um den kürzesten oder optimalen Pfad zwischen zwei beliebigen Knoten in einem Diagramm zu finden. Dies beinhaltet die Untersuchung jeder Kante zwischen allen m?glichen Scheitelpunktpaaren, die vom Quellknoten beginnen, und die Aufrechterhaltung eines aktualisierten Satzes von Scheitelpunkten mit dem kürzesten Gesamtabstand, bis der Zielknoten erreicht ist.
die geringste Anzahl von Hops
Eine gemeinsame Anwendung der Graphentheorie besteht darin, die geringste Anzahl von Hopfen zwischen zwei beliebigen Knoten zu finden. Wie bei B?umen k?nnen Diagramme auf zwei Arten durchquert werden: Tiefen- oder Breite. Wir haben im vorherigen Artikel die Suche in der Tiefe zuerst behandelt. Schauen wir uns also die Breite der ersten Suche an. Betrachten Sie die folgende Grafik:
1. Create a queue 2. Enqueue the root node and mark it as visited 3. While the queue is not empty do: 3a. dequeue the current node 3b. if the current node is the one we're looking for then stop 3c. else enqueue each unvisited adjacent node and mark as visitedAber woher wissen wir, welche Knoten benachbart sind, geschweige denn nicht besucht, ohne zuerst die Grafik zu durchqueren? Dies bringt uns zu dem Problem, wie eine Diagrammdatenstruktur modelliert werden kann.
Darstellung des Diagramms
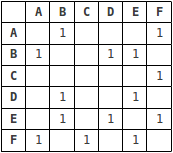
Es gibt im Allgemeinen zwei M?glichkeiten, ein Diagramm darzustellen: entweder als Adjazenzmatrix oder als Adjazenzliste. Die obige Grafik, die als Adjazenzliste dargestellt wird, sieht Folgendes aus: 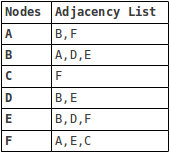
1. Create a queue 2. Enqueue the root node and mark it as visited 3. While the queue is not empty do: 3a. dequeue the current node 3b. if the current node is the one we're looking for then stop 3c. else enqueue each unvisited adjacent node and mark as visitedUnd nun sehen wir sehen, wie die Implementierung des allgemeinen Breit-First-Suchalgorithmus aussieht:
<span><span><?php
</span></span><span><span>$graph = array(
</span></span><span> <span>'A' => array('B', 'F'),
</span></span><span> <span>'B' => array('A', 'D', 'E'),
</span></span><span> <span>'C' => array('F'),
</span></span><span> <span>'D' => array('B', 'E'),
</span></span><span> <span>'E' => array('B', 'D', 'F'),
</span></span><span> <span>'F' => array('A', 'E', 'C'),
</span></span><span><span>);</span></span>
Wenn wir die folgenden Beispiele ausführen, bekommen wir:
<span><span><?php
</span></span><span><span>class Graph
</span></span><span><span>{
</span></span><span> <span>protected $graph;
</span></span><span> <span>protected $visited = array();
</span></span><span>
</span><span> <span>public function __construct($graph) {
</span></span><span> <span>$this->graph = $graph;
</span></span><span> <span>}
</span></span><span>
</span><span> <span>// find least number of hops (edges) between 2 nodes
</span></span><span> <span>// (vertices)
</span></span><span> <span>public function breadthFirstSearch($origin, $destination) {
</span></span><span> <span>// mark all nodes as unvisited
</span></span><span> <span>foreach ($this->graph as $vertex => $adj) {
</span></span><span> <span>$this->visited[$vertex] = false;
</span></span><span> <span>}
</span></span><span>
</span><span> <span>// create an empty queue
</span></span><span> <span>$q = new SplQueue();
</span></span><span>
</span><span> <span>// enqueue the origin vertex and mark as visited
</span></span><span> <span>$q->enqueue($origin);
</span></span><span> <span>$this->visited[$origin] = true;
</span></span><span>
</span><span> <span>// this is used to track the path back from each node
</span></span><span> <span>$path = array();
</span></span><span> <span>$path[$origin] = new SplDoublyLinkedList();
</span></span><span> <span>$path[$origin]->setIteratorMode(
</span></span><span> <span>SplDoublyLinkedList<span>::</span>IT_MODE_FIFO|SplDoublyLinkedList<span>::</span>IT_MODE_KEEP
</span></span><span> <span>);
</span></span><span>
</span><span> <span>$path[$origin]->push($origin);
</span></span><span>
</span><span> <span>$found = false;
</span></span><span> <span>// while queue is not empty and destination not found
</span></span><span> <span>while (!$q->isEmpty() && $q->bottom() != $destination) {
</span></span><span> <span>$t = $q->dequeue();
</span></span><span>
</span><span> <span>if (!empty($this->graph[$t])) {
</span></span><span> <span>// for each adjacent neighbor
</span></span><span> <span>foreach ($this->graph[$t] as $vertex) {
</span></span><span> <span>if (!$this->visited[$vertex]) {
</span></span><span> <span>// if not yet visited, enqueue vertex and mark
</span></span><span> <span>// as visited
</span></span><span> <span>$q->enqueue($vertex);
</span></span><span> <span>$this->visited[$vertex] = true;
</span></span><span> <span>// add vertex to current path
</span></span><span> <span>$path[$vertex] = clone $path[$t];
</span></span><span> <span>$path[$vertex]->push($vertex);
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span>
</span><span> <span>if (isset($path[$destination])) {
</span></span><span> <span>echo "<span><span>$origin</span> to <span>$destination</span> in "</span>,
</span></span><span> <span>count($path[$destination]) - 1,
</span></span><span> <span>" hopsn";
</span></span><span> <span>$sep = '';
</span></span><span> <span>foreach ($path[$destination] as $vertex) {
</span></span><span> <span>echo $sep, $vertex;
</span></span><span> <span>$sep = '->';
</span></span><span> <span>}
</span></span><span> <span>echo "n";
</span></span><span> <span>}
</span></span><span> <span>else {
</span></span><span> <span>echo "No route from <span><span>$origin</span> to <span>$destinationn</span>"</span>;
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span><span>}</span></span>
Wenn wir einen Stapel anstelle einer Warteschlange verwendet hatten, wird der Traversal zu einer Tiefensuche.
Finden Sie den kürzesten Pfad
Ein weiteres h?ufiges Problem ist es, den optimalsten Weg zwischen zwei beliebigen Knoten zu finden. Früher erw?hnte ich die Fahranleitung von Googlemap als Beispiel dafür. Weitere Anwendungen sind Planungsreisen, Stra?enverkehrsmanagement und Zug-/Busplanung. Einer der berühmtesten Algorithmen, die dieses Problem angehen, wurde 1959 von einem 29-j?hrigen Informatiker namens Edsger W. Dijkstra erfunden. Im Allgemeinen umfasst die L?sung von Dijkstra die Untersuchung jeder Kante zwischen allen m?glichen Scheitelpunktpaaren, die vom Quellknoten beginnen, und die Aufrechterhaltung eines aktualisierten Satzes von Scheitelpunkten mit kürzester Gesamtentfernung, bis der Zielknoten erreicht ist oder nicht erreicht ist, je nachdem, welcher Fall auch nicht sein kann. Es gibt verschiedene M?glichkeiten, die L?sung zu implementieren, und in der Tat wurden über Jahre nach 1959 viele Verbesserungen - unter Verwendung von Minheaps, Priorit?tsquellen und Fibonacci -Haufen - an Dijkstras ursprünglicher Algorithmus gemacht. Einige verbesserte Leistung, w?hrend andere so konzipiert waren, dass sie M?ngel in der Dijkstra -L?sung behandeln, da sie nur mit positiv gewichteten Graphen arbeitete (bei denen die Gewichte positive Werte sind). Hier ist ein Beispiel für eine (positive) gewichtete Grafik: 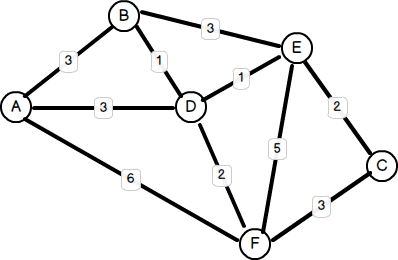
1. Create a queue 2. Enqueue the root node and mark it as visited 3. While the queue is not empty do: 3a. dequeue the current node 3b. if the current node is the one we're looking for then stop 3c. else enqueue each unvisited adjacent node and mark as visitedUnd hier finden Sie eine Implementierung mit einem Priorit?tsqueue, um eine Liste aller ?nicht optimierten“ Scheitelpunkte beizubehalten:
<span><span><?php
</span></span><span><span>$graph = array(
</span></span><span> <span>'A' => array('B', 'F'),
</span></span><span> <span>'B' => array('A', 'D', 'E'),
</span></span><span> <span>'C' => array('F'),
</span></span><span> <span>'D' => array('B', 'E'),
</span></span><span> <span>'E' => array('B', 'D', 'F'),
</span></span><span> <span>'F' => array('A', 'E', 'C'),
</span></span><span><span>);</span></span>
Wie Sie sehen k?nnen, ist die L?sung von Dijkstra einfach eine Variation der Breite-First-Suche!
Das Ausführen der folgenden Beispiele liefert die folgenden Ergebnisse:
<span><span><?php
</span></span><span><span>class Graph
</span></span><span><span>{
</span></span><span> <span>protected $graph;
</span></span><span> <span>protected $visited = array();
</span></span><span>
</span><span> <span>public function __construct($graph) {
</span></span><span> <span>$this->graph = $graph;
</span></span><span> <span>}
</span></span><span>
</span><span> <span>// find least number of hops (edges) between 2 nodes
</span></span><span> <span>// (vertices)
</span></span><span> <span>public function breadthFirstSearch($origin, $destination) {
</span></span><span> <span>// mark all nodes as unvisited
</span></span><span> <span>foreach ($this->graph as $vertex => $adj) {
</span></span><span> <span>$this->visited[$vertex] = false;
</span></span><span> <span>}
</span></span><span>
</span><span> <span>// create an empty queue
</span></span><span> <span>$q = new SplQueue();
</span></span><span>
</span><span> <span>// enqueue the origin vertex and mark as visited
</span></span><span> <span>$q->enqueue($origin);
</span></span><span> <span>$this->visited[$origin] = true;
</span></span><span>
</span><span> <span>// this is used to track the path back from each node
</span></span><span> <span>$path = array();
</span></span><span> <span>$path[$origin] = new SplDoublyLinkedList();
</span></span><span> <span>$path[$origin]->setIteratorMode(
</span></span><span> <span>SplDoublyLinkedList<span>::</span>IT_MODE_FIFO|SplDoublyLinkedList<span>::</span>IT_MODE_KEEP
</span></span><span> <span>);
</span></span><span>
</span><span> <span>$path[$origin]->push($origin);
</span></span><span>
</span><span> <span>$found = false;
</span></span><span> <span>// while queue is not empty and destination not found
</span></span><span> <span>while (!$q->isEmpty() && $q->bottom() != $destination) {
</span></span><span> <span>$t = $q->dequeue();
</span></span><span>
</span><span> <span>if (!empty($this->graph[$t])) {
</span></span><span> <span>// for each adjacent neighbor
</span></span><span> <span>foreach ($this->graph[$t] as $vertex) {
</span></span><span> <span>if (!$this->visited[$vertex]) {
</span></span><span> <span>// if not yet visited, enqueue vertex and mark
</span></span><span> <span>// as visited
</span></span><span> <span>$q->enqueue($vertex);
</span></span><span> <span>$this->visited[$vertex] = true;
</span></span><span> <span>// add vertex to current path
</span></span><span> <span>$path[$vertex] = clone $path[$t];
</span></span><span> <span>$path[$vertex]->push($vertex);
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span>
</span><span> <span>if (isset($path[$destination])) {
</span></span><span> <span>echo "<span><span>$origin</span> to <span>$destination</span> in "</span>,
</span></span><span> <span>count($path[$destination]) - 1,
</span></span><span> <span>" hopsn";
</span></span><span> <span>$sep = '';
</span></span><span> <span>foreach ($path[$destination] as $vertex) {
</span></span><span> <span>echo $sep, $vertex;
</span></span><span> <span>$sep = '->';
</span></span><span> <span>}
</span></span><span> <span>echo "n";
</span></span><span> <span>}
</span></span><span> <span>else {
</span></span><span> <span>echo "No route from <span><span>$origin</span> to <span>$destinationn</span>"</span>;
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span><span>}</span></span>
Zusammenfassung
In diesem Artikel habe ich die Grundlagen der Graphentheorie, zwei M?glichkeiten zur Darstellung von Grafiken und zwei grundlegende Probleme in der Anwendung der Graphentheorie eingeführt. Ich habe Ihnen gezeigt, wie eine Breite-First-Suche verwendet wird, um die geringste Anzahl von Hopfen zwischen zwei beliebigen Knoten zu finden und wie Dijkstra-L?sung verwendet wird, um den kürzesten Weg zwischen zwei beliebigen Knoten zu finden. Bild über Fotolienh?ufig gestellte Fragen (FAQs) zu Grafiken in Datenstrukturen
Was ist der Unterschied zwischen einem Diagramm und einem Baum in Datenstrukturen? Ein Baum ist eine Art Grafik, aber nicht alle Grafiken sind B?ume. Ein Baum ist ein verbundenes Diagramm ohne Zyklen. Es hat eine hierarchische Struktur mit einem Wurzelknoten und einem untergeordneten Knoten. Jeder Knoten in einem Baum hat einen einzigartigen Weg von der Wurzel. Andererseits kann ein Diagramm Zyklen haben und seine Struktur ist komplexer. Es kann verbunden oder getrennt werden und Knoten k?nnen mehrere Pfade zwischen sich haben.
Wie werden Grafiken in Datenstrukturen dargestellt? Liste. Eine Adjazenzmatrix ist ein 2D -Array der Gr??e V x V, wobei V die Anzahl der Scheitelpunkte im Diagramm ist. Wenn zwischen den Scheitelpunkten I und J eine Kante gibt, ist die Zelle an der Kreuzung von Zeile I und Spalte J 1, ansonsten 0. Eine Adjazenzliste ist ein Array von verknüpften Listen. Der Index des Arrays repr?sentiert einen Scheitelpunkt und jedes Element in seiner verknüpften Liste der anderen Scheitelpunkte, die mit dem Scheitelpunkt eine Kante bilden. sind verschiedene Arten von Grafiken in Datenstrukturen. Ein einfaches Diagramm ist ein Diagramm ohne Schleifen und nicht mehr als eine Kante zwischen zwei Eckpunkten. Ein Multigraph kann mehrere Kanten zwischen Scheitelpunkten haben. Ein komplettes Diagramm ist ein einfaches Diagramm, in dem jedes Eckpaar durch eine Kante verbunden ist. Ein gewichteter Diagramm weist jeder Kante ein Gewicht zu. Ein gerichteter Diagramm (oder Digraph) hat Kanten mit einer Richtung. Die Kanten zeigen von einem Scheitelpunkt zum anderen.
Welche Anwendungen von Grafiken in der Informatik werden in zahlreichen Anwendungen in der Informatik
Diagramme verwendet. Sie werden in sozialen Netzwerken verwendet, um Verbindungen zwischen Menschen darzustellen. Sie werden im Web -Crawling verwendet, um Webseiten zu besuchen und einen Suchindex zu erstellen. Sie werden in Netzwerk -Routing -Algorithmen verwendet, um den besten Weg zwischen zwei Knoten zu finden. Sie werden in Biologie verwendet, um biologische Netzwerke zu modellieren und zu analysieren. Sie werden auch in Computergrafik- und Physik-Simulationen verwendet. (BFS). DFS erforscht vor dem Backtracking so weit wie m?glich an jedem Zweig. Es verwendet eine Stapeldatenstruktur. BFS untersucht alle Scheitelpunkte in der gegenw?rtigen Tiefe, bevor er zur n?chsten Ebene geht. Es verwendet eine Warteschlangendatenstruktur. Jeder Schlüssel im HashMap ist ein Scheitelpunkt und sein Wert ist eine verknüpfte Liste, die die Scheitelpunkte enth?lt, an die er angeschlossen ist. in zwei disjunkte S?tze unterteilt werden, so dass jede Kante einen Scheitelpunkt in einem Set an einen Scheitelpunkt im anderen Satz verbindet. Kein Kanten verbindet Scheitelpunkte innerhalb desselben Satzes.
Was ist ein Untergraphen? Es hat einige (oder alle) Eckpunkte des Originalgrafiks und einige (oder alle) Kanten des Originalgraps.
Was ist ein Zyklus in einem Diagramm? Ein Pfad, der am selben Scheitelpunkt beginnt und endet und mindestens eine Kante hat.
Was ist ein Pfad in einem Diagramm? von Konsekutive Eckpunkte sind durch eine Kante verbunden.
Das obige ist der detaillierte Inhalt vonPHP Master | Datenstrukturen für PHP -Entwickler: Diagramme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Hei?e Themen



 Wie implementiere ich Authentifizierung und Autorisierung in PHP?
Jun 20, 2025 am 01:03 AM
Wie implementiere ich Authentifizierung und Autorisierung in PHP?
Jun 20, 2025 am 01:03 AM
TosecurelyHandleAuthenticationAuthorizationInphp, folge theSteps: 1.Alwayshashpasswordswithpassword_hash () und password_verify (), usePreeParedStatementStopreventsQlinjapitca und StoreuserDatain $ _SessionArtelogin.2.ImplementscaChescescesc
 Wie k?nnen Sie Dateien -Uploads in PHP sicher verarbeiten?
Jun 19, 2025 am 01:05 AM
Wie k?nnen Sie Dateien -Uploads in PHP sicher verarbeiten?
Jun 19, 2025 am 01:05 AM
Um Datei -Uploads in PHP sicher zu verarbeiten, besteht der Kern darin, Dateitypen zu überprüfen, Dateien umzubenennen und die Berechtigungen zu beschr?nken. 1. Verwenden Sie Finfo_File (), um den realen MIME -Typ zu überprüfen, und nur bestimmte Typen wie Bild/JPEG sind zul?ssig. 2. Verwenden Sie Uniqid (), um zuf?llige Dateinamen zu generieren und sie im Root-Verzeichnis ohne Web zu speichern. 3.. Begrenzen Sie die Dateigr??e durch Php.ini- und HTML -Formulare und setzen Sie die Verzeichnisberechtigungen auf 0755; 4. Verwenden Sie Clamav, um Malware zu scannen, um die Sicherheit zu verbessern. Diese Schritte verhindern effektiv Sicherheitslücken und stellen sicher, dass der Upload -Prozess des Datei -Uploads sicher und zuverl?ssig ist.
 Was sind die Unterschiede zwischen == (loser Vergleich) und === (strenger Vergleich) in PHP?
Jun 19, 2025 am 01:07 AM
Was sind die Unterschiede zwischen == (loser Vergleich) und === (strenger Vergleich) in PHP?
Jun 19, 2025 am 01:07 AM
In PHP ist der Hauptunterschied zwischen == und == die Strenge der Typprüfung. == Die Konvertierung des Typs wird vor dem Vergleich durchgeführt, beispielsweise 5 == "5" gibt true zurück und === fordert an, dass der Wert und der Typ gleich sind, bevor True zurückgegeben wird, z. B. 5 === "5" gibt false zurück. In den Nutzungsszenarien ist === sicherer und sollte zuerst verwendet werden, und == wird nur verwendet, wenn die Typumwandlung erforderlich ist.
 Wie führe ich arithmetische Operationen in PHP (, -, *, /, %) aus?
Jun 19, 2025 pm 05:13 PM
Wie führe ich arithmetische Operationen in PHP (, -, *, /, %) aus?
Jun 19, 2025 pm 05:13 PM
Die Methoden zur Verwendung grundlegender mathematischer Operationen in PHP sind wie folgt: 1. Additionszeichen unterstützen Ganzfaktoren und Floating-Punkt-Zahlen und k?nnen auch für Variablen verwendet werden. String -Nummern werden automatisch konvertiert, aber nicht für Abh?ngigkeiten empfohlen. 2. Subtraktionszeichen verwenden - Zeichen, Variablen sind gleich, und die Typumwandlung ist ebenfalls anwendbar. 3. Multiplikationszeichen verwenden * Zeichen, die für Zahlen und ?hnliche Zeichenfolgen geeignet sind; 4. Division verwendet / Zeichen, die vermeiden müssen, durch Null zu dividieren, und beachten Sie, dass das Ergebnis m?glicherweise schwimmende Punktzahlen sein kann. 5. Die Modulzeichen k?nnen verwendet werden, um ungerade und sogar Zahlen zu beurteilen, und wenn negative Zahlen verarbeitet werden, stimmen die Restzeichen mit der Dividende überein. Der Schlüssel zur korrekten Verwendung dieser Operatoren liegt darin, sicherzustellen, dass die Datentypen klar sind und die Grenzsituation gut behandelt wird.
 Wie k?nnen Sie mit NoSQL -Datenbanken (z. B. MongoDB, Redis) von PHP interagieren?
Jun 19, 2025 am 01:07 AM
Wie k?nnen Sie mit NoSQL -Datenbanken (z. B. MongoDB, Redis) von PHP interagieren?
Jun 19, 2025 am 01:07 AM
Ja, PHP kann mit NoSQL -Datenbanken wie MongoDB und Redis durch bestimmte Erweiterungen oder Bibliotheken interagieren. Verwenden Sie zun?chst den MongoDBPHP -Treiber (installiert über PECL oder Composer), um Client -Instanzen zu erstellen und Datenbanken und Sammlungen zu betreiben, wobei Sie Insertion, Abfrage, Aggregation und andere Vorg?nge unterstützen. Zweitens verwenden Sie die Predis Library oder PHPREDIS-Erweiterung, um eine Verbindung zu Redis herzustellen, Schlüsselwerteinstellungen und -akquisitionen durchzuführen und PHPREDIS für Hochleistungsszenarien zu empfehlen, w?hrend Predis für die schnelle Bereitstellung bequem ist. Beide sind für Produktionsumgebungen geeignet und gut dokumentiert.
 Wie bleibe ich mit den neuesten PHP-Entwicklungen und Best Practices auf dem neuesten Stand?
Jun 23, 2025 am 12:56 AM
Wie bleibe ich mit den neuesten PHP-Entwicklungen und Best Practices auf dem neuesten Stand?
Jun 23, 2025 am 12:56 AM
TostaycurrentwithPHPdevelopmentsandbestpractices,followkeynewssourceslikePHP.netandPHPWeekly,engagewithcommunitiesonforumsandconferences,keeptoolingupdatedandgraduallyadoptnewfeatures,andreadorcontributetoopensourceprojects.First,followreliablesource
 Was ist PHP und warum wird es für die Webentwicklung verwendet?
Jun 23, 2025 am 12:55 AM
Was ist PHP und warum wird es für die Webentwicklung verwendet?
Jun 23, 2025 am 12:55 AM
PHPBECAMEPOPULARFORWebDevelopmentDuetoitSeaseoflearning, Seamlessintegrationwithhtml, weit verbreitete Hostingsupport, andalargeecosystemincludingFrameWorkelaravelandcmsplatformen -?hnliche WordPress.itexcelsinformlingsformen, Managingusesersions, Interacti
 Wie setzen Sie die PHP -Zeitzone?
Jun 25, 2025 am 01:00 AM
Wie setzen Sie die PHP -Zeitzone?
Jun 25, 2025 am 01:00 AM
Tosettherighttimezoneinphp, usedate_default_timezone_set () functionAtthestartofyourScriptWithAvalididentifiersuchas'america/new_york'.1.usedate_default_timezone_set () beeanydate/timeFununtions.2.Alternativ, konfigurieren
